目录
- 一、前言
- 二、默认分词器
- 三、IK分词器
- 1.主要算法
- 2.安装IK分词器
- 2.1 关闭es服务
- 2.2 上传ik分词器到虚拟机
- 2.3 解压
- 2.4 启动ES服务
- 2.5 测试分词器效果
- 2.6 IK分词器词典
- 四、拼音分词器
- 1.安装
- 2.测试分词效果
- 五、自定义分词器
- 1.创建自定义分词器
- 2.测试
一、前言
ES文档的数据拆分成一个个有完整含义的关键词,并将关键词与文档对应,这样就可以通过关键词查询文档。要想正确地分词,需要选择合适的分词器。
现在咱们来探索一下分词器的真实面目!
二、默认分词器
standard analyzer:Elasticsearch默认分词器,根据空格和标点
符号对英文进行分词,会进行单词的大小写转换。
默认分词器是英文分词器,对中文的分词是一字一词。
三、IK分词器
IK分词器,全名IKAnalyzer,是一个开源的,基于Java语言开发的轻量级中文分词工具包。
1.主要算法
支持对中文进行分词,提供了两种分词算法
ik_smart:最少切分
ik_max_word:最细粒度划分
2.安装IK分词器
2.1 关闭es服务
2.2 上传ik分词器到虚拟机
tips: ik分词器的版本要和es版本保持一致
2.3 解压
解压ik分词器到elasticsearch的plugins目录下
unzip elasticsearch-analysis-ik-7.17.0.zip -d /usr/local/elasticsearch1/plugins/analysis-ik
2.4 启动ES服务
su es#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/#启动ES服务:
./elasticsearch -d
2.5 测试分词器效果
#算法1
GET /_analyze
{"text":"测试语句","analyzer":"ik_smart"
}eg:
GET /_analyze
{"text": "我爱美羊羊","analyzer": "ik_smart"
}

#算法2
GET /_analyze
{"text":"测试语句","analyzer":"ik_max_word"
}eg:
GET /_analyze
{"text": "我爱美羊羊","analyzer": "ik_max_word"
}

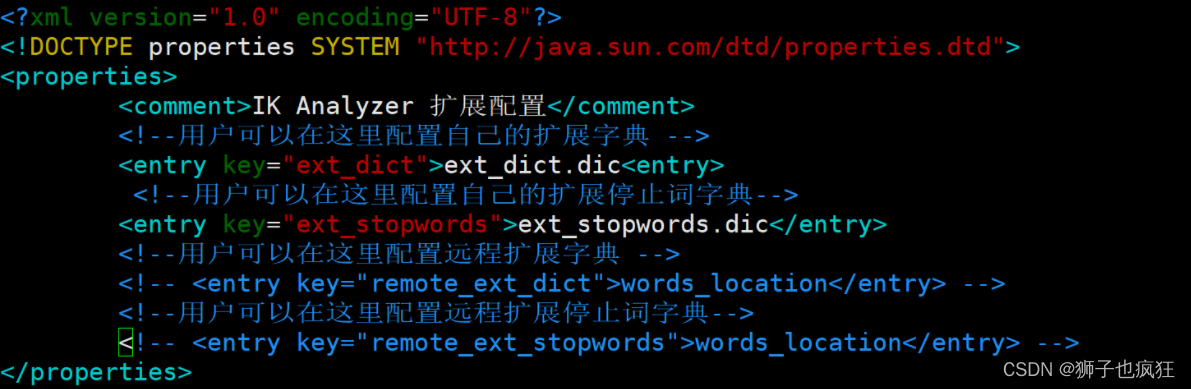
2.6 IK分词器词典
IK分词器根据词典进行分词,词典文件在IK分词器的config目录中。
- main.dic:IK中内置的词典。记录了IK统计的所有中文单词。
- IKAnalyzer.cfg.xml:用于配置自定义词库。
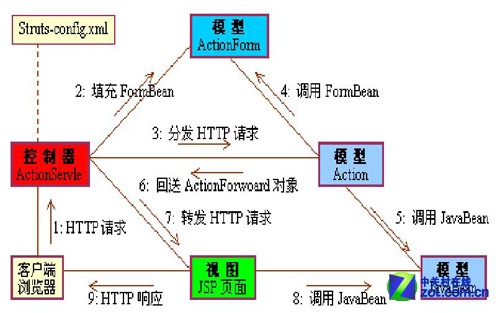
四、拼音分词器

拼音分词器可以将中文分成对应的全拼,全拼首字母等。
1.安装
和ik分词器安装一样,也是先将es服务关闭,将拼音分词器上传至虚拟机,并且分词器版本需要和es版本一致(参考ik分词器安装)
2.测试分词效果
GET /_analyze
{"text":测试语句,"analyzer":pinyin
}eg:
GET /_analyze
{"text": "xi yang yang","analyzer": "pinyin"
}
五、自定义分词器

前面两种分词器,各有优点,但是他们的功能确实不够完备,比如使用ik分词器可以对中文进行分词,但是却不能对拼音分词;所以在现实开发中,我们一般使用自定义分词器进行分词,这样既可以对文字分词,也可以对拼音分词,现在咱们来研究一下如何写一个ik+pinyin分词器。
1.创建自定义分词器
PUT /索引名
{"settings" : {"analysis" : {"analyzer" : {"ik_pinyin" : { //自定义分词器名"tokenizer":"ik_max_word", // 基本分词器"filter":"pinyin_filter" // 配置分词器过滤}},"filter" : { // 分词器过滤时配置另一个分词器,相当于同时使用两个分词器"pinyin_filter" : { "type" : "pinyin", // 另一个分词器// 拼音分词器的配置"keep_separate_first_letter" : false, // 是否分词每个字的首字母"keep_full_pinyin" : true, // 是否分词全拼"keep_original" : true, // 是否保留原始输入"remove_duplicated_term" : true // 是否删除重复项}}}},"mappings":{"properties":{"域名1":{"type":域的类型,"store":是否单独存储,"index":是否创建索引,"analyzer":分词器},"域名2":{ ...}}}
}eg:
PUT /student2
{"settings": {"analysis": {"analyzer": {"ik_pinyin":{"tokenizer":"ik_max_word","filter":"pinyin_filter"}},"filter": {"pinyin_filter":{"type":"pinyin","keep_separate_first_letter" : false, "keep_full_pinyin" : true,"keep_original" : true, "remove_duplicated_term" : true }}}},"mappings": {"properties": {"name":{"type": "text","store": true,"index": true,"analyzer": "ik_pinyin"},"age":{"type": "integer"}}}
}
2.测试
GET /student2/_analyze
{"text": "程序员","analyzer": "ik_pinyin"
}