word segmentation
- 1.概述
- 2.分词方法
- (1)基于词典的机械分词法
- ①正向最大匹配(FMM)
- ②逆向最大匹配(BMM)
- ③双向最大匹配
- (2)基于统计的分词法
- ①基于互信息的分词方法
- ②最大概率分词方法
- 3.分词粒度
- 4.中文分词工具
- 5.总结
1.概述
*◆ 何为中文分词?*中文分词指的是将一个汉字序列切分成一个个单独的词。句子1:北京人在纽约分词结果:**北京人**/**在**/**纽约***◆ 出现分词歧义怎么办?*句子2:地面积了厚厚的雪
分词结果1:**地面**/**积**/**了**/**厚厚的**/**雪**
分词结果2:**地**/**面积**/**了**/**厚厚的**/**雪**由人来判断,结果1是分词正确的,但是对于计算机来说,两者都有可能,那该如何分词?
2.分词方法
(1)基于词典的机械分词法
基于词典匹配的机械分词方法,主要依据词典的信息,根据一定的规则将输入的字符串与词典中的词逐条匹配,匹配成功则进行相应的切分处理。
①正向最大匹配(FMM)
假设自动分词词典中最长的词所含字数为M,则将字符串前M个字作为待匹配字符串,在词典中进行查找,如果该M个字与词典中的某个词匹配成功,则将其切分出来;若未匹配成功,则将最后一个字从待匹配字符串中删除,再将待匹配字符串与词典进行匹配,以此类推,直到匹配成功为止。

*举例*
输入句子:S1=“计算语言学课程有意思”
定义:MaxLen=5;S2=“”;J=“/”;
词表:计算语言学,课程,意思,有意,思......;原始句子:计算语言学课程有意思
第1次分词:**计算语言学**/课程有意思
第2次分词:**计算语言学**/**课程**/有意思
第3次分词:**计算语言学**/**课程**/**有意**/思
第4次分词:**计算语言学**/**课程**/**有意**/**思**
②逆向最大匹配(BMM)
从句子的右边取候选子串,匹配不成功时去掉候选子串最前面的一个字,其他规则与FMM相同。
*举例*
输入句子:S1=“计算语言学课程有意思”
定义:MaxLen=5;S2=“”;J=“/”;
词表:计算语言学,课程,意思,有意,思......;原始句子:计算语言学课程有意思
第1次分词:计算语言学课程有/**意思**
第2次分词:计算语言学课程/**有**/**意思**
第3次分词:计算语言学/**课程**/**有**/**意思**
第4次分词:**计算语言学**/**课程**/**有**/**意思**
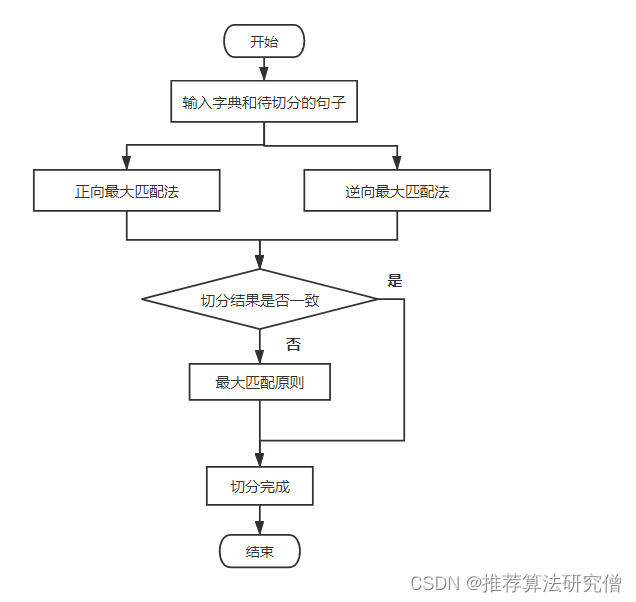
③双向最大匹配
先根据标点对文档进行粗切分,把文档分解成若干个句子,然后再对这些句子用正向最大匹配法和逆向最大匹配法进行扫描切分。如果两种分词方法得到的匹配结果相同,则认为分词正确,否则,按最小分词集处理。如果两种方法切分的次数一样时,则采用一些规则处理。
正向分词结果:计算语言学/课程/有意/*思*
逆向分词结果:**计算语言学**/**课程**/**有**/**意思**
(2)基于统计的分词法
统计分词以概率论为理论基础,将汉字上下文中汉字组合串的出现抽象成随机过程,随机过程的参数需要通过大规模语料库训练得到。
①基于互信息的分词方法
◆ 方法
根据字与字同时出现的概率大小来判断是否为一个词,几个相邻的字同时出现的次数越多,则其构成词的概率越大。
◆ 公式
对于字符串x和字符串y,计算其互信息值 M𝐼(𝑥,𝑦),用互信值得大小判断x和y之间的结合程度。M𝐼(𝑥,𝑦)= log2(𝑝(𝑥, 𝑦)/𝑝(𝑥,𝑦) )
如果M𝐼(𝑥,𝑦)>0,表示x和y会同时出现,MI值越大,共同出现程度越大;
如果M𝐼(𝑥,𝑦)=0,表示x和y是独立出现;
如果M𝐼(𝑥,𝑦)<0,表示x和y会互斥出现。
②最大概率分词方法
◆ 方法
利用语料库计算每种切分结果的概率,选取概率最高的切分作为最优分词切分,一般采用的是链式计算其概率值。
◆ N-gram模型
n元模型就是在估算条件概率时,忽略距离≥n的上文词的影响。以N=2为例,根据词典找到字串S中所有可能的词,并且根据训练语料库,根据所有S中出现的词 w i w_i wi和 w i − 1 w_{i−1} wi−1计算 p ( w i ∣ w i − 1 ) p(w_i |w_{i−1}) p(wi∣wi−1),然后把所有可能的切分词串都找出来,计算 p ( W ) p(W) p(W),并且从这些词串中找出一条概率最大的路径作为分词结果。
p ( W ) = p ( w 1 , w 2 , … , w n ) = ∏ i = 1.... n p ( w i ∣ w i − 1 ) p(W)= p(w_1,w_2,…,w_n)=\prod_{i=1....n}p(w_i |w_{i−1}) p(W)=p(w1,w2,…,wn)=i=1....n∏p(wi∣wi−1)
当N=3时,概率值为 p ( w i ∣ w i − 2 , w i − 1 ) p(w_i |w_{i−2},w_{i−1}) p(wi∣wi−2,wi−1)。显然,当n≥2时,该模型可以保留一定的词序信息,n越大,保留的词序信息越丰富,但计算量也呈指数级增长。
3.分词粒度
*◆ 何为分词粒度?*分词粒度是一个中文词包含汉字的个数。*◆ 举例*“电视机”—— 分词粒度为3“高清电视机”—— 分词粒度为5“高清/电视/机”—— 分词粒度为2*◆ 粒度大小与准确性*在搜索引擎建立索引时,如果分词粒度过大,会导致只有输入特定关键词才能搜索到相应结果;如果分词粒度过小,则影响搜索引擎查询的准确性。因此选择合适的分词粒度是构建搜索引擎的重要因素。
4.中文分词工具
Jieba分词 https://github.com/fxsjy/jieba
SnowNLP http://github.com/isnowfy/snownlp
LTP http://www.ltp-cloud.com/
HanNLP https://github.com/hankcs/HanLP/
Jieba是一个在自然语言处理中用的最多的工具之一,目前已经能够实现包括分词、词性标注以及命名实体识别等多种功能。
Jieba提供了三种分词模式:精确模式,试图将句子最精确的切开,适合文本分析;全模式,把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;搜索引擎模式,在精确模式的基础上,对长词再切分,适合用于搜索引擎分词。
import jiebasent = '中文分词是文本处理不可或缺的一步!'seg_list = jieba.cut(sent, cut_all=True)
print('全模式:', '/'.join(seg_list))seg_list = jieba.cut(sent, cut_all=False)
print('精确模式:', '/'.join(seg_list))seg_list = jieba.cut_for_search(sent)
print('搜索引擎模式:', '/'.join(seg_list))
运行结果:
5.总结
中文分词与英文分词有很大的不同,英文一个单词就是一个词,而汉语是以字为基本的书写单位,中文分词的处理较为困难。主要对中文分词技术进行了介绍,介绍了基于词典和基于统计的分词方法,对分词的粒度与准确性做了相关的评价,最后给出一种开源的中文分词工具Jieba。总之,在自然语言处理、信息搜索引擎、情感分析等方面,中文分词技术占有着重要地位。