中文分词介绍
中文分词就是将一个汉语句子中的词切分出来。为机器翻译、文本挖掘、情感分析等任务打好基础。为什么一定要先进行分词呢?这就像 26 个字母一样,单个字母并不能表达某个意思,将其组合起来成为一个英文单词才有意义。
中文虽然有时候单个字也能表达具体的意思,但是往往要组成一个词才能表达一个完整的意思。目前,自然语言处理的计算工具主要是计算机。而计算机在识别文本信息时,也跟人一样。无法去理解字这种级别的特征,因此才需要进行分词。
分词工具
目前,常用的中文分词工具主要有: Stanford NLP、 HanLP、 结巴分词器 jieba 等。而在Python中常用的为 jieba 。
中文分词方法
中文分词主要有三种方法,分别是基于字典的切分方法、基于规则的切分方法和基于统计的切分方法。具体方法如下图所示:
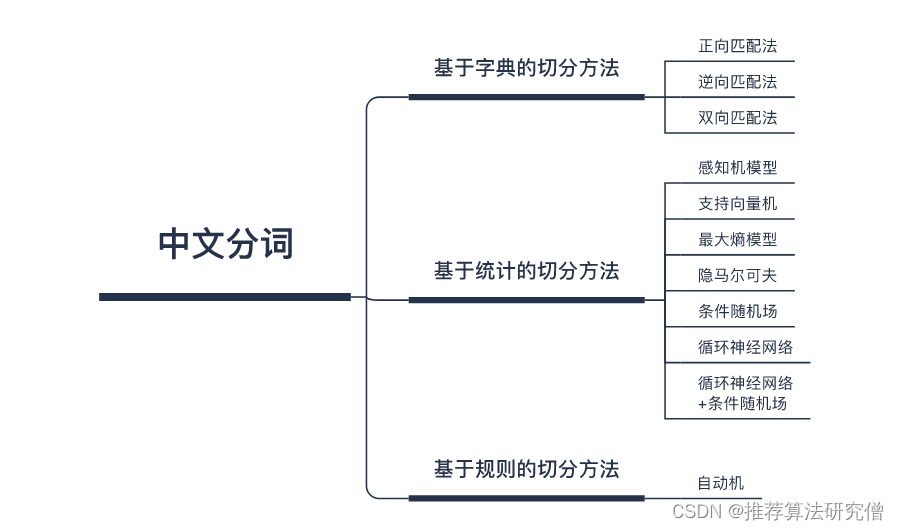
基于字典的方法通常也被称为机械切分方法,其工作原理是取句子中相邻的字组成一个词,然后去对比字典中存不存在这个词,如果存在则切分完成。如果不存在则重新组词,再去字典中对比。
基于规则的方法则是通过语法规则等来模拟人对句子的理解,从而对句子进行切分。这种切分方法目前使用得较少,主要是其针对不同领域的文本需要制定不同的规则。通用性极差。
基于统计的方法是目前许多分词器中使用得最多的方法。一般情况下,相邻的字同时出现的次数越多,就越有可能构成一个词。而基于统计的方法就是利用这一思想先来对大量的语料进行统计,然后再来计算几个字构成一个词的概率。
基于字典的切分方法
基于字典的切分方法虽然古老,而且简单。但却是目前最常用的切分方法,也是许多分词器中采用的方法之一。
正向最大匹配方法
正向最大匹配算法的原理是:从一个句子的正向开始切分,将句子切成两份,取前一份去和字典中的词进行匹配。具体的算法运行过程如下图描述:
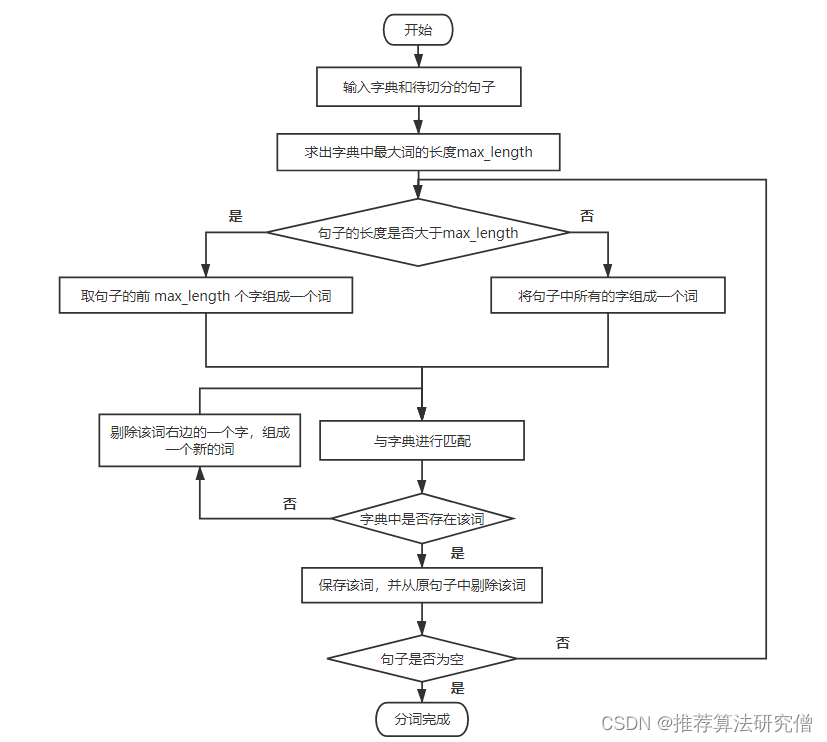
举一个例子来说明,假设我们有一个这样一个句子:【我想吃苹果】。
词典为:【我,苹果,想,吃,今天,发放,可以】。
- 第一步:求出字典中词的最大长度 word_length。在这个例子中,最大长度的词只有两个字,因此,word_length = 2。
- 第二步:对句子进行切分,切分结果为:【我想|吃苹果】。
- 第三步:拿【我想】去和字典中的词进行匹配。
- 第四步:字典中没有【我想】这个词。因此将斜杠往左移动一位。此时切分结果为:【我|想吃苹果】。
- 第五步:拿【我】去和字典中的词进行匹配。字典中存在【我】这个词。因此得到一个切分结果【我】。
- 第六步:把句子中的【我】字去掉,此时的句子为:【想吃苹果】。
- 第七步:重复上述的过程,最后会得到的切分结果为:【我,想,吃,苹果】。
逆向最大匹配法
正向最大匹配法每次是取的是句子的前几个字来构成一个词,然后去和字典进行匹配。而逆向最大匹配法与正向最大匹配法正好相反,每次都是从句子的末尾开始取。为什么要从后边开始取,这样做与正向最大匹配法又有什么区别呢?
这主要是考虑到汉语的语言习惯问题,一般情况下,汉语的中心词往往在句子的后边。所以逆向最大匹配法的分词效果通常也比正向最大匹配法好一点点。
双向最大匹配法
可能你也想到了,双向最大匹配法就是将正向最大匹配法和逆向最大匹配法相结合起来,组成一个性能更优的分词器。
具体来说就是,使用正向最大匹配切分一次,然后使用逆向最大匹配法再切一次。然后判断两者切分结果是否一致,若不一致则按最大匹配原则来决定使用哪一种切分结果。具体过程如下图所示:
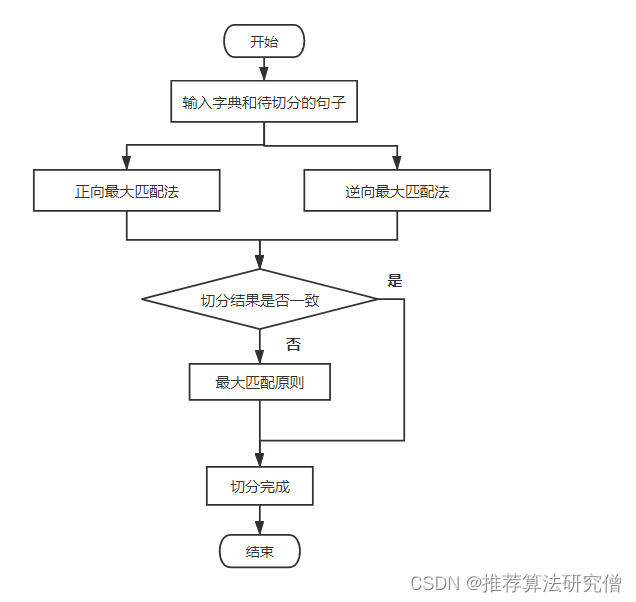
最大切分原则是:要保证切分结果的词最少,因为切分出的词越多,表达出的含义就越丰富,准确理解这句话的意思就相对越难。例如这句话:【自然语言处理是人工智能的一个重要分支】。
假设我们有两种切法:
- 【自然|语言|处理|是|人工|智能|的|一个|重要|分支】
- 【自然语言处理|是|人工智能|的|一个|重要|分支】
很显然,第二种切法,把【自然语言处理】和【人工智能】看做是一个词要更准确些,也更符合人对句子的理解。
实战构建分词器
前面主要讲述了基于字典的分词方法。为了更直观的理解,我们现在使用正向最大匹配法来构建一个分词器。正向最大匹配法的实现代码如下:
def cut_word(sentence, word_dic):"""正向最大匹配分词器sentence:待切分的句子word_dic:字典"""# 寻找字典中最大词的长度word_length_list = [len(word) for word in word_dic]max_length = max(word_length_list)# 求出句子的长度word_length = len(sentence)# 创建一个列表用来存放切分结果cut_word_list = []# 判断句子的长度是否为 0 ,若为 0 ,则句子为空while word_length > 0:max_cut_length = min(max_length, word_length)# 取前 max_cut_length 个字组成一个词subsentence = sentence[0:max_cut_length]while max_cut_length > 0:# 匹配字典if subsentence in word_dic:cut_word_list.append(subsentence)breakelif max_cut_length == 1:cut_word_list.append(subsentence)breakelse:# 若字典没有词匹配,则剔除一个字,重新组成一个新的词max_cut_length = max_cut_length-1subsentence = subsentence[0:max_cut_length]# 剔除切分完成的词sentence = sentence[max_cut_length:]# 重新计算句子的长度word_length = word_length-max_cut_lengthreturn cut_word_list
构建好分词器和字典之后,使用几个句子来进行测试。
word_dict = ['我们', '不错', '太阳', '西瓜', '大厦', '成都', '天气', '大学','雪花', '周末', '我', '吃', '了', '香蕉', '三星', '大家', '看','好玩', '熊猫', '现在', '代码', '书', '同学', '今天', '理性', '抱怨','想', '室友', '字典', '去', '风格', '生成', '大', '奶茶', ]
test_sentence = '今天天气不错'
result = cut_word(test_sentence, word_dict)
print('|'.join(result))
test_sentence = '我想去成都看大熊猫'
result = cut_word(test_sentence, word_dict)
print('|'.join(result))如果字典里一个对应的词都没有,则切分的最终结果会把每个字都切成一个词。这也是基于字典的切分方法的弊端。一般情况下,这种字典不包含的词被称作 未登录词 。现在来测试一下基于正向最大匹配法的分词器性能如何。
这里我们使用北京大学计算语言学研究所提供的中文分词数据集,该数据将搜集的语料是 1998 年人民日报上的文本文字。该数据集可以在 Bakeoff 中下载。
也可以通过执行下面代码下载到当前目录。
!wget https://labfile.oss.aliyuncs.com/courses/1329/pku_training.txt
# 创建一个空列表来存放数据
data_set = []
with open("pku_training.txt",'rb') as f:# 每次读取一行数据line = f.readline()while line:line=line.decode("gb18030","ignore")data_set.append(line)line = f.readline()# 查看出前六个句子,并打印出数据集的长度。
# 打印前六行数据
for i in range(7):print(data_set[i])print('-'*100)
len(data_set)从上面结果可以看到,该数据集使用空格来将词与词之间区分开。并且总共包含 19056 份数据。该数据集里的每一份数据为一个段落。而分词器的输入为句子。因此将数据集切分成句子的形式。
sentence_list = [] # 创建空列表用于存放处理后的数据
for para in data_set:sentence = para.split('。') # 按 ‘。’ 对句子进行切分sentence_list.extend(sentence)
# 打印切分后句子的前 10 个句子
for i in range(10):print(sentence_list[i])print('-'*100)
len(sentence_list)
从上面的打印结果,可以看出总共含有 54660 个句子。接下来使用该数据集构建一个词典,并划分一部分数据用于测试。
word_dict = [] # 创建一个空列表作为字典
test_sentence_list = [] # 创建一个空列表用于存放测试句子
word_test_labels = [] # 创建一个空列表用于存放测试句子的正确分词结果
for i in range(len(sentence_list)):sentence = sentence_list[i]sentence = sentence.strip()if not sentence:continue# 将句子按空格进行切分,得到词words = sentence.split(" ")# 取后 60 个句子用于测试if len(sentence_list)-i > 60:word_dict.extend(words)else:test_sentence = ''.join(words)test_sentence_list.append(test_sentence)word_test_labels.append(words)
为了能够看出分词器的分词效果,定义一个评价指标来对其进行评价。指标计算公式如下:
a c c u r e n c y = ∑ 1 k ∑ 1 n I ( w i ) ∑ 1 k ∑ 1 n w i accurency = \frac{\sum_{1}^{k}\sum_{1}^{n}{I(w_{i})}}{\sum_{1}^{k}\sum_{1}^{n}{w_i}} accurency=∑1k∑1nwi∑1k∑1nI(wi)
在上式中, k k k 表示句子总数, n n n 表示每个句子切分出来词的总数。 I ( w i ) I(w_{i}) I(wi) 为指示函数。若 w i w_{i} wi 切分正确,则该函数为 1,否则为 0。
定义计算准确率的函数。
def accurency(y_pre, y):"""分词准确率计算函数y_pre:预测结果y: 正确结果"""count = 0n = len(y_pre)for i in range(len(y_pre)):# 统计每个句子切分出来的词数n += len(y_pre[i])for word in y_pre[i]:# 统计每个句子切词正确的词数if word in y[i]:count += 1return count/n使用所构建的分词器来进行分词,并求出分词的准确率。
from tqdm.notebook import tqdmword_cut_result = [] # 创建一个空列表来存放分词结果
# 每次切一个句子
for sent in tqdm(test_sentence_list):# 使用前面所构建的分词器进行切词temp = cut_word(sent, word_dict)# 存放分词后的数据word_cut_result.append(temp)
# 计算准确率
acc = accurency(word_cut_result, word_test_labels)
从上面的实验结果可知,分词的准确率约为 85% 左右。这个结果虽然并不算太理想,但也算还可以。下面我们打印出分词结果与数据集的标注结果,进行对比。
for i in range(3):print('数据集的标准切分:', '|'.join(word_test_labels[i]))print('-'*100)print('分词器切分的结果: ', '|'.join(word_cut_result[i]))print('='*100)
从上的结果可以看出,我们所构建的基于正向最大匹配的分词器,虽然简单,但分词效果还是很显著的,这也是许多分词器仍然使用这种古老方法的原因,因为我们只需要维护字典就可以。
下面我们使用 jieba 来对同样的数据进行切分,并计算出切分的准确率。
word_cut_result = [] # 创建一个空列表来存放分词结果
# 每次切分一个句子
for sent in test_sentence_list:# 使用 jieba 进行分词temp = jieba.cut(sent)# jieba 分词返回的是一个 jieba 的数据格式,将其转换为列表temp = list(temp)# 保存分词结果word_cut_result.append(temp)
# 计算分词准确率
acc = accurency(word_cut_result, word_test_labels)
acc
使用同样的方法,打印出 jieba 分词的结果。for i in range(3):print('数据集的标准切分:', '|'.join(word_test_labels[i]))print('-'*40)print('分词器切分的结果: ', '|'.join(word_cut_result[i]))print('='*100)有点意外,jieba 要比我们所构建的分词器要差一点,可能的原因是我们的字典和测试数据属于同一领域的数据,而 jieba 的字典数据则是常用的词数据,因为不同领域的知识通常有差异,常用的词语也不同。例如用医学、金融、法律等文本来测试我们所构建的分词器,效果应该会大打折扣。如下:
test_sentence = '甲状腺激素是一种激素'
result = cut_word(test_sentence, word_dict)
print('|'.join(result))
print('='*100)
result = jieba.cut(test_sentence)
print('|'.join(result))
还有就是切词标准的差异。例如:在我们所使用的的数据中,姓名会切分成 “姓” 和 “名”,而 jieba 则不切分。如下:
test_sentence = '刘德华是歌手,也是演员'
result = cut_word(test_sentence, word_dict)
print('|'.join(result))
print('='*100)
result = jieba.cut(test_sentence)
print('|'.join(result))
但是 jieba 的速度要快许多,当然,这是其内部做了许多的优化。
总结
本文主要介绍常用的中文分词方法,并详细介绍了基于字典的中文分词方法。此外使用 Python 构建出来了一个基于正向最大匹配方法的分词器,并与 jieba 进行了对比。
相关链接
- 中文分词-百度百科