在全文搜索(Fulltext Search)中,**词(Term)**是一个搜索单元,表示文本中的一个词,**标记(Token)**表示在文本字段中出现的词,由词的文本、在原始文本中的开始和结束偏移量、以及数据类型等组成。
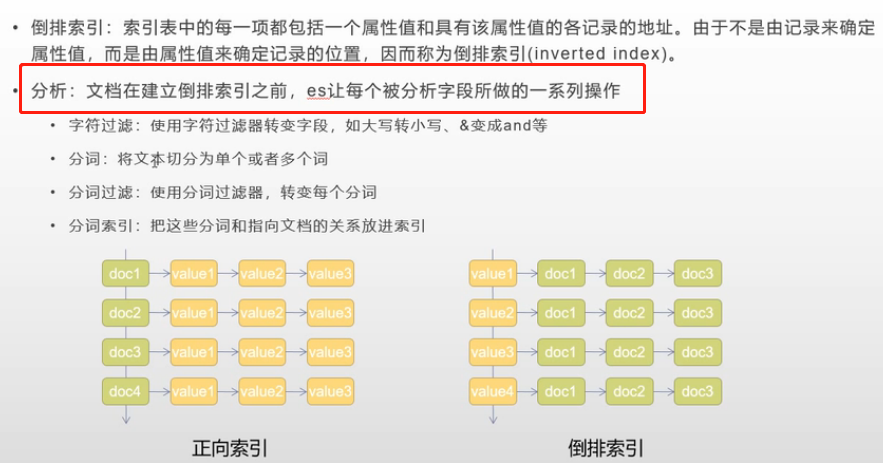
ElasticSearch 把文档数据写到倒排索引(Inverted Index)的结构中,倒排索引建立词(Term)和文档之间的映射,索引中的数据是面向词,而不是面向文档的。分析器(Analyzer)的作用就是分析(Analyse),用于把传入Lucene的文档数据转化为倒排索引,把文本处理成可被搜索的词。
什么是分析器
分析器由**一个分词器(Tokenizer)和零个或多个标记过滤器(TokenFilter)**组成,也可以包含零个或多个字符过滤器(Character Filter)。
ps:在实际使用中我们大多数听到的都是分词器,原本是因为过滤器用到的很少,所以在叫法上几乎分析器等价于分词器了。而且分词的结果经常与高亮结合使用。
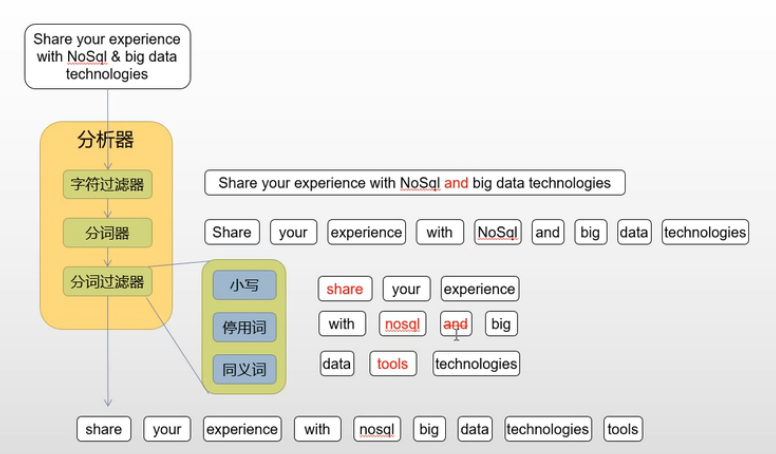
- 在ElasticSearch引擎中,分析器的任务是分析(Analyze)文本数据,分析是分词,规范化文本的意思,其工作流程是:
- 首先,字符过滤器对分析(analyzed)文本进行过滤和处理,例如从原始文本中移除HTML标记,根据字符映射替换文本等。
- 过滤之后的文本被分词器接收,分词器把文本分割成标记流,也就是一个接一个的标记。
- 标记过滤器对标记流进行过滤处理,例如,移除停用词,把词转换成其词干形式,把词转换成其同义词等。
- 过滤之后的标记流被存储在倒排索引中。
- ElasticSearch引擎在收到用户的查询请求时,会使用分析器对查询条件进行分析,根据分析的结构,重新构造查询,以搜索倒排索引,完成全文搜索请求,
图解倒排索引与分析过程
以下重点描述分词器,过滤器不经常用,不做过多记录。
分词器种类
系统默认分词器
- 标准分词器(Standard Tokenizer)
标准分词器类型是standard,用于大多数欧洲语言,使用Unicode文本分割算法对文档进行分词。
- 字母分词器(Letter Tokenizer)
字符分词器类型是letter,在非字母位置上分割文本,这就是说,根据相邻的词之间是否存在非字母(例如空格,逗号等)的字符,对文本进行分词,对大多数欧洲语言非常有用。
- 空格分词器(Whitespace Tokenizer)
空格分词类型是whitespace,在空格处分割文本
- 小写分词器(Lowercase Tokenizer)
小写分词器类型是lowercase,在非字母位置上分割文本,并把分词转换为小写形式,功能上是Letter Tokenizer和 Lower Case Token Filter的结合(Combination),但是性能更高,一次性完成两个任务。
- 经典分词器(Classic Tokenizer)
经典分词器类型是classic,基于语法规则对文本进行分词,对英语文档分词非常有用,在处理首字母缩写,公司名称,邮件地址和Internet主机名上效果非常好。
- 简单分词器(Simple Tokenizer)
功能强于WhitespaceAnalyzer, 首先会通过非字母字符来分割文本信息,然后将词汇单元统一为小写形式。该分析器会去掉数字类型的字符。
- 停用词分词器(Stop Tokenizer)
StopAnalyzer的功能超越了SimpleAnalyzer,在SimpleAnalyzer的基础上增加了去除英文中的常用单词(如the,a等),也可以更加自己的需要设置常用单词;不支持中文
- 正则分词器(Pattern Tokenizer)
一个pattern类型的analyzer可以通过正则表达式将文本分成"terms"(经过token Filter 后得到的东西 )。接受如下设置:
一个 pattern analyzer 可以做如下的属性设置:
lowercaseterms是否是小写. 默认为 true 小写.pattern正则表达式的pattern, 默认是 \W+.flags正则表达式的flagsstopwords一个用于初始化stop filter的需要stop 单词的列表.默认单词是空的列表
- 语言分词器(Language Tokenizer)
一个用于解析特殊语言文本的analyzer集合。( arabic,armenian, basque, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english, finnish, french,galician, german, greek, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian,persian, portuguese, romanian, russian, sorani, spanish, swedish, turkish, thai.),但是没有中文
- 自定义分词器(Custom Tokenizer)
是自定义的analyzer。允许多个零到多个tokenizer,零到多个 Char Filters. custom analyzer 的名字不能以 "_"开头.
等其它多种分词器,这里不再一一列出,因为不是经常用的。重点是下面的中文分词器
中文分词器
- 主要介绍ik分词器和拼音分词器
ik分词器(IK Tokenizer) - 常用
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。采用了特有的“正向迭代最细粒度切分算法“,支持细粒度和最大词长两种切分模式;具有83万字/秒(1600KB/S)的高速处理能力。采用了多子处理器分析模式,支持:英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符优化的词典存储,更小的内存占用。支持用户词典扩展定义,针对Lucene全文检索优化的查询分析器IKQueryParser(作者吐血推荐);引入简单搜索表达式,采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
ik_max_word
会将文本做最细粒度的拆分;尽可能多的拆分出词语
ik_smart
会做最粗粒度的拆分;已被分出的词语将不会再次被其它词语占有
ik_max_word和ik_smart区别
# ik_max_wordcurl -XGET 'http://localhost:9200/_analyze?pretty&analyzer=ik_max_word' -d '联想是全球最大的笔记本厂商'{"tokens" : [{"token" : "联想","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "是","start_offset" : 2,"end_offset" : 3,"type" : "CN_CHAR","position" : 1},{"token" : "全球","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 2},{"token" : "最大","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 3},{"token" : "的","start_offset" : 7,"end_offset" : 8,"type" : "CN_CHAR","position" : 4},{"token" : "笔记本","start_offset" : 8,"end_offset" : 11,"type" : "CN_WORD","position" : 5},{"token" : "笔记","start_offset" : 8,"end_offset" : 10,"type" : "CN_WORD","position" : 6},{"token" : "本厂","start_offset" : 10,"end_offset" : 12,"type" : "CN_WORD","position" : 7},{"token" : "厂商","start_offset" : 11,"end_offset" : 13,"type" : "CN_WORD","position" : 8}]
}# ik_smart
curl -XGET 'http://localhost:9200/_analyze?pretty&analyzer=ik_smart' -d '联想是全球最大的笔记本厂商'{"tokens" : [{"token" : "联想","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "是","start_offset" : 2,"end_offset" : 3,"type" : "CN_CHAR","position" : 1},{"token" : "全球","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 2},{"token" : "最大","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 3},{"token" : "的","start_offset" : 7,"end_offset" : 8,"type" : "CN_CHAR","position" : 4},{"token" : "笔记本","start_offset" : 8,"end_offset" : 11,"type" : "CN_WORD","position" : 5},{"token" : "厂商","start_offset" : 11,"end_offset" : 13,"type" : "CN_WORD","position" : 6}]
}
pinyin 分词器
pinyin分词器可以让用户输入拼音,就能查找到相关的关键词。比如在某个商城搜索中,输入yonghui,就能匹配到永辉。这样的体验还是非常好的。
http://localhost:9200/medcl/_analyze?text=刘德华&analyzer=pinyin_analyzer{"tokens" : [{"token" : "liu","start_offset" : 0,"end_offset" : 1,"type" : "word","position" : 0},{"token" : "de","start_offset" : 1,"end_offset" : 2,"type" : "word","position" : 1},{"token" : "hua","start_offset" : 2,"end_offset" : 3,"type" : "word","position" : 2},{"token" : "刘德华","start_offset" : 0,"end_offset" : 3,"type" : "word","position" : 3},{"token" : "ldh","start_offset" : 0,"end_offset" : 3,"type" : "word","position" : 4}]
}