AWR自动工作量资料档案库: AWR用于收集关于该特定数据库的操作统计信息和其他统计信息,oracle以固定的时间间隔(默认60分钟)为其所有重要统计信息和负载信息执行一次快照,并将这些快照存储在AWR中。这些信息在AWR中保留给定的时间(默认为1周),然后被清除
AWR默认每隔60分钟从SGA中采样收集一次统计数据(10G则是GATHER_STATS_JOB收集的数据库对象的统计数据,11G则是auto optimizer stats collection收集的数据库对象的统计数据)以快照的方式存放在SYSAUX表空间,具体是以WRM$、WRH$、WRR$、WRI$、WRI$的系统视图保存起来,保存一周,然后删除。为了正确收集统计数据,STATISTICS_LEVEL设置为TYPICAL(默认)或ALL,所以AWR快照里面保存的就是统计数据。
AWR (Automatic Workload Repository)通俗讲就是一堆历史性能数据,放在SYSAUX表空间上。
AWR数据最近一小时的放在内存,其他历史的放在表中
AWR=ASH(dba_hist_active_sess_history)+其他统计信息(含OS指标)和等待信息(dba_hist_sys_time_model、dba_hist_sysstat)
ASH其实就是v$active_session_history中数据,是存放在内存中,是放在SGA中的一些DB的读写及各种操作的统计信息
实验过v$active_session_history中数据每时每刻都不一样,且重启后之前的数据都没有了
10G开启关闭AWR
关闭awr(停止AWR快照的收集,不是统计数据的收集)
exec DBMS_WORKLOAD_REPOSITORY.MODIFY_SNAPSHOT_SETTINGS(INTERVAL => 0);
关闭awr,一般不建议如下操作,不仅关闭了AWR信息,也把CBO所需要的数据对象统计信息功能关闭了
exec dbms_scheduler.disable('SYS.GATHER_STATS_JOB');
开启awr,每隔20分钟收集一次,默认保留时间2天
dbms_workload_repository.modify_snapshot_settings (interval => 20,retention => 2*24*60)
11G开启关闭AWR
关闭awr(停止AWR快照的收集,不是统计数据的收集)
exec DBMS_WORKLOAD_REPOSITORY.MODIFY_SNAPSHOT_SETTINGS(INTERVAL => 0);
关闭awr,一般不建议如下操作,不仅关闭了AWR,,也把其他一些数据对象统计信息功能关闭了
设置参数statistics_level=basic
上面两种关闭AWR方式的区别在于:设置satitstics_level后,还可以进行手动创建快照,设置采集间隔为0后,不可以手动创建快照.
启动awr,默认保留时间8天
exec DBMS_WORKLOAD_REPOSITORY.MODIFY_SNAPSHOT_SETTINGS(interval=>60);
启动awr,默认保留时间要改为14天(20160分钟)
exec DBMS_WORKLOAD_REPOSITORY.MODIFY_SNAPSHOT_SETTINGS(retention=>20160, interval=>60);
AWR报告
Elapsed 为该AWR性能报告的时间跨度(自然时间的跨度,例如前一个快照snapshot是4点生成的,后一个快照snapshot是6点生成的,则若使用@?/rdbms/admin/awrrpt 脚本中指定这2个快照的话,那么其elapsed = (6-4)=2 个小时),一个AWR性能报告 至少需要2个AWR snapshot性能快照才能生成 ( 注意这2个快照时间 实例不能重启过,否则指定这2个快照生成AWR性能报告会报错),AWR性能报告中的指标往往是后一个快照和前一个快照的指标的delta,这是因为 累计值并不能反映某段时间内的系统workload。
AWR报告的所取的两个SNAP之间不能重启DB,ASH的采样数据是保存在内存中。而分配给ASH的内存空间是有限的,当所分配空间占满后,旧的记录就会被覆盖掉;而且数据库重启后,所有的这些ASH信息都会消失。这样,对于长期检测oracle的性能是不可能的
AWR报告不可以跨实例的运行状态进行比较(宕机前后的不可以比较)
快照(snapshots)
快照是特定时间范围内的历史数据集合,再由ADDM进行性能比较。默认情况下,数据库每个小时产生一次快照,并将这些统计信息在工作量仓库中保留8 天。
默认每隔一小时,内存监控进程(MMON)自动地采集一次统计信息,并把这些信息存放到负载库中,一次采样就是一个快照。为了节省空间,采集的数据在7天后自动清除。快照的频率和保留时间可以由用户修改。
查看快照信息:select * from dba_hist_snapshot
AWR的由来:
10g之前的oracle:用户的连接将产生会话,当前会话记录保存在v$session中;处于等待状态的会话会被复制一份放在v$session_wait中。当该连接断开后,其原来的连接信息在v$session和v$session_wait中就会被删除;oracle10g及之后保留下了v$session_wait中的这些信息,并新出现了一个视图:v$session_wait_history。这个视图保存了每个活动session在v$session_wait中最近10次的等待事件。但这对于一段时期内的数据库性能状况的监测是远远不够的,为了解决这个问题,就多出了v$active_session_history(ASH)视图。ASH的采样数据是保存在内存中。而分配给ASH的内存空间是有限的,当所分配空间占满后,旧的记录就会被覆盖掉;而且数据库重启后,所有的这些ASH信息都会消失。这样,对于长期检测oracle的性能是不可能的。在Oracle10g中,提供了永久保留ASH信息的方法,这就是AWR。由于全部保存ASH中的信息是非常耗费时间和空间的,AWR采用的策略是:每小时对v$active_session_history进行采样一次,并将信息保存到磁盘中,并且保留7天,7天后旧的记录才会被覆盖。这些采样信息被保存在视图wrh$_active_session_history中。而这个采样频率(1小时)和保留时间(7天)是可以根据实际情况进行调整的,这就给DBA们提供了更加有效的系统监测工具。AWR永久地保存系统的性能诊断信息,由SYS用户拥有。一段时间后,你可能想清除掉这些信息;有时候为了性能诊断,你可能需要自己定义采样频率来获取系统快照信息。Oracle 10g在包dbms_workload_repository中提供了很多过程,通过这些过程,你可以管理快照并设定基线(baselines)。
ASH(Active Session History)的历史数据主要存储在基础表sys.wrh$_active_session_history和dba_hist_active_sess_history
ASH的特点是:ASH取出抽样数据,并不是对所有数据进行采集
ASH以V$SESSION为基础,每秒采样一次,记录活动会话等待的事件。不活动的会话不会采样,采样工作由新引入的后台进程MMNL来完成。
ASH每秒(默认,受隐含参数_ash_sampling_interval影响)对活动会话进行一次抽样采集,采集到的信息,临时储存于sga区域中的buffer,可以称为ash buffer,v$active_session_history视图这里面所展示的是buffer中所采集到活动会话的统计信息.里面信息量的多少,信息保留时间的长短都与数据库的活跃性相关
ASH 内存记录数据始终是有限的,为了保存历史数据,引入了自动负载信息库(Automatic Workload Repository ,AWR) 由后台进程MMON完成。ASH信息同样被采集写出到AWR负载库中。由于内存不是足够的,所以MMNL进程在ASH写满后会将信息写出到AWR负载库中。ASH全部写出是不可接受的,所以一般只写入收集的10%的数据量
当SYSAUX表空间满后,AWR将自动覆盖掉旧的信息,并在警告日志中记录一条相关信息:
ORA-1688: unable to extend table SYS.WRH$_ACTIVE_SESSION_HISTORY partition WRH$_ACTIVE_3533490838_1522 by 128 in tablespace SYSAUX
WRM$表存储AWR的元数据(awrinfo.sql脚本)
WRH$表存储采样快照的历史数据(awrrpt.sql脚本)
WRI$表存储同数据库建议功能相关的数据(ADDM相关数据)
写出到AWR负载库的ASH信息记录在AWR的基础表wrh$_active_session_history中,wrh$_active_session_history是一个分区表,Oracle会自动进行数据清理
v$session (当前正在发生)
v$session_wait (当前正在发生)
v$session_wait_history (会话最近的10次等待事件)
v$active_session_history (内存中的ASH采集信息,理论为1小时)
wrh$_active_session_history (写入AWR库中的ASH信息,理论为1小时以上)
dba_hist_active_sess_history (根据wrh$_active_session_history生成的视图,每10秒生成一次)

1.查看当前的AWR保存策略、设置:快照间隔、保存时间。
select * from dba_hist_wr_control;
2.AWR配置都是通过dbms_workload_repository包进行配置。
2.1 调整AWR产生snapshot的频率和保留策略,
如将收集间隔时间改为30 分钟一次。并且保留5天时间(单位都是分钟):
SQL>exec dbms_workload_repository.modify_snapshot_settings(interval=>30, retention=>5*24*60);
设置快照时间间隔为 20 分钟,保留时间为两天 -- 您可以发出以下命令。参数以分钟为单位。
SQL> exec dbms_workload_repository.modify_snapshot_settings ( interval => 20, retention => 2*24*60 );
2.2 关闭AWR,把interval设为0则关闭自动捕捉快照
SQL> exec dbms_workload_repository.modify_snapshot_settings(interval=>0);
2.3 手工创建一个快照(加不加括号都可以)
SQL> exec DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT();
SQL> exec dbms_workload_repository.create_snapshot;
2.4 查看快照
SQL> select * from dba_hist_snapshot order by snap_id desc
2.5 手工删除指定范围的快照
SQL> exec DBMS_WORKLOAD_REPOSITORY.DROP_SNAPSHOT_RANGE(low_snap_id => 973, high_snap_id => 999, dbid => 262089084);
2.6 查看基线信息
SQL> select * from dba_hist_baseline
基线(Baselines)
基线包含了一个特定时间范围的性能数据,用来在性能问题发生时,与其他类似的时间段进行比较。基线中的快照会被自动AWR清除进程排除,并无限期保留。一个基线定义在一对快照之间,快照通过他们的快照序列号识别.每个基线有且只有一对快照。
查看基线信息:select * from dba_hist_baseline
4.2.1 创建Baseline
Exec DBMS_WORKLOAD_REPOSITORY.CREATE_BASELINE(start_snap_id=>7550,end_snap_id=>7660,baseline_name=>'am_baseline');
4.2.2 删除Baseline
Exec DBMS_WORKLOAD_REPOSITORY.DROP_BASELINE(baseline_name=>'am_baseline',cascade=>true);
删除Baseline使用DROP_BASELINE过程,删除时可以通过cascade参数选择是否将其关联的Snapshots级别进行删除
通过基线比对
select * from TABLE(DBMS_WORKLOAD_REPOSITORY.awr_diff_report_html(DBID, INSTANCE_NUMBER, startsnapid,endsnapid, DBID, INSTANCE_NUMBER, startsnapid,endsnapid));
执行后把结果粘贴到html格式的文件中,再用ie打开
本机或本实例AWR采集步骤
第一步SQL> @$ORACLE_HOME/rdbms/admin/awrrpt.sql
第二步输入报告格式如html
第三步输入要查看几天之内的信息(默认保存7天在sysaux表空间,如果保存了三天后重启oracle则数据还在sysaux表空间中,因为awr是来自内存,不可以跨实例的运行状态进行比较(宕机前后的不可以比较))
第四步输入开始的snap号(在第三步会展示)
第五步输入结束的snap号(在第三步会展示)
第六步输入报告的名字,报告存放到具体地址中(在sql中输入exit后pwd显示的当前路径)
当然也可以直接通过sql语句来获取
SQL> select * from table(dbms_workload_repository.awr_report_html(DBID, INSTANCE_NUMBER, startsnapid,endsnapid))
awrrpt.sql其实就是dbms_workload_repository.awr_report_html
或dbms_workload_repository.awr_report_text
AWR比对报告((基线比对也是用这个)
SQL>@$ORACLE_HOME/rdbms/admin/awrddrpt.sql
当然也可以直接通过sql语句来获取
SQL>select * from TABLE(DBMS_WORKLOAD_REPOSITORY.awr_diff_report_html(DBID, INSTANCE_NUMBER, startsnapid,endsnapid, DBID, INSTANCE_NUMBER, startsnapid,endsnapid));
awrrpt.sql其实就是DBMS_WORKLOAD_REPOSITORY.AWR_DIFF_REPORT_HTML或DBMS_WORKLOAD_REPOSITORY.AWR_DIFF_REPORT_TEXT
RAC环境下获取AWR报告
获取某个实例的
SQL>@$ORACLE_HOME/rdbms/admin/awrrpti.sql
获取全局的
SQL>@$ORACLE_HOME/rdbms/admin/ awrgrpt.sql
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/30126024/viewspace-2136458/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/30126024/viewspace-2136458/




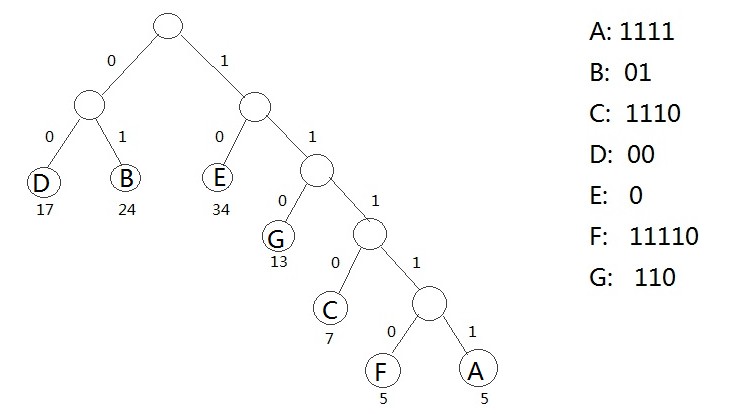




![[基础知识] 霍夫曼编码](https://img-blog.csdnimg.cn/img_convert/4834d96399827c682209c82f6ea87470.gif)