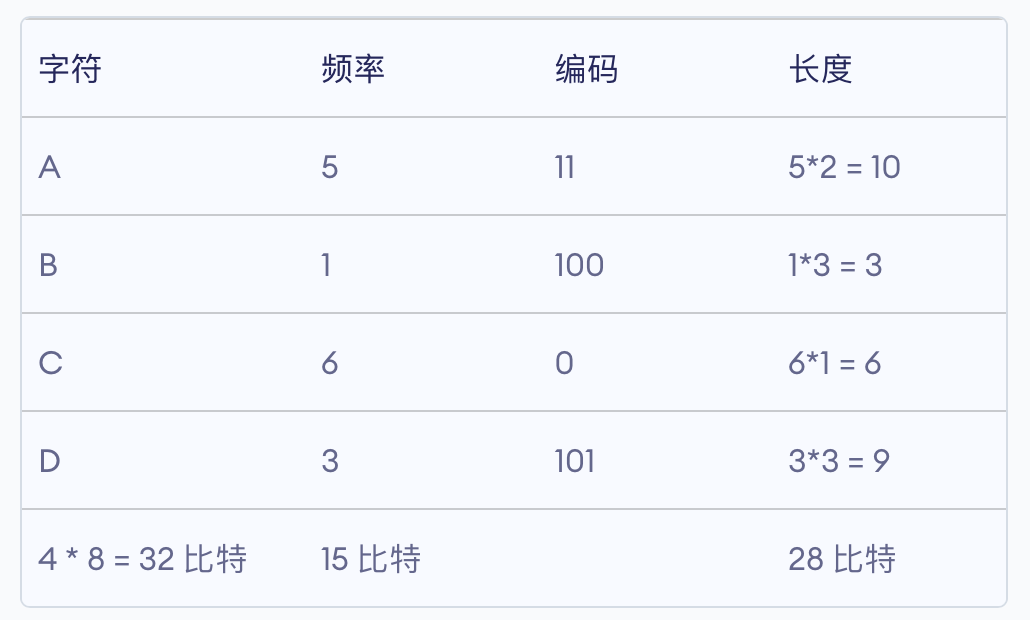
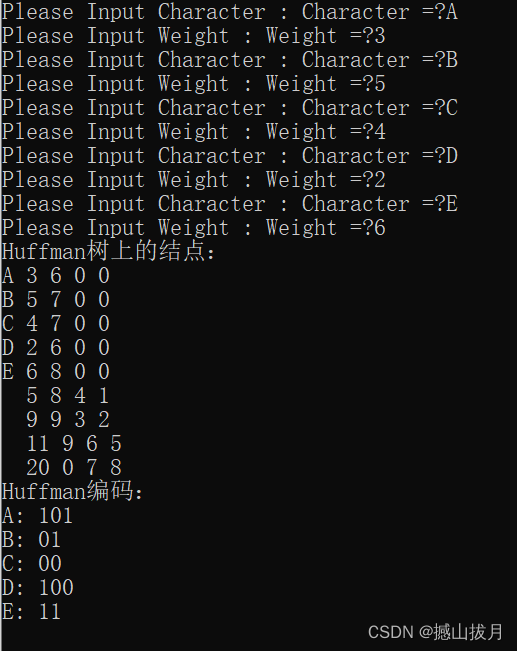
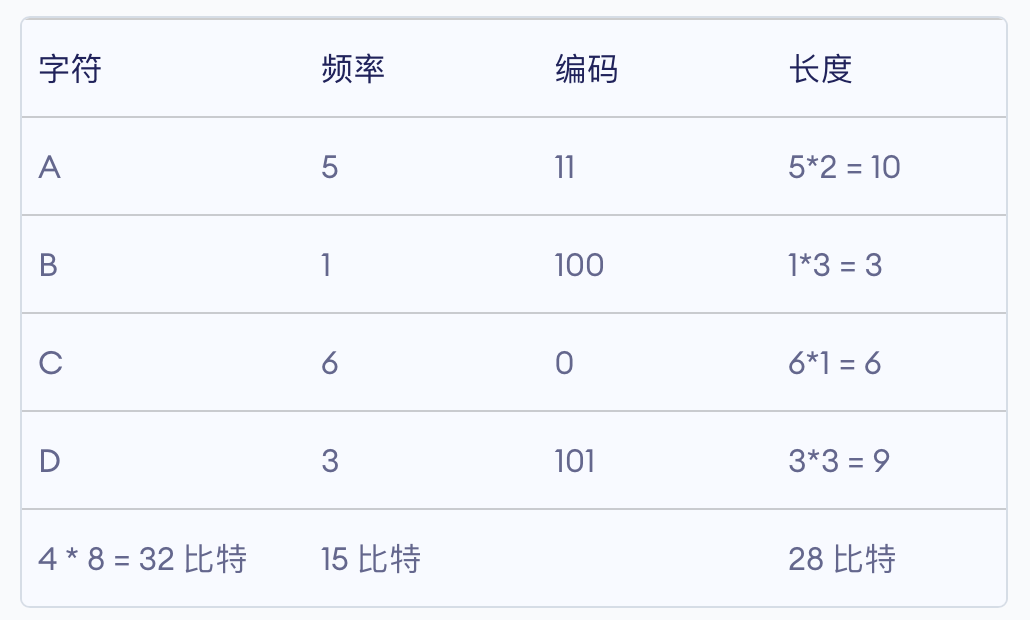
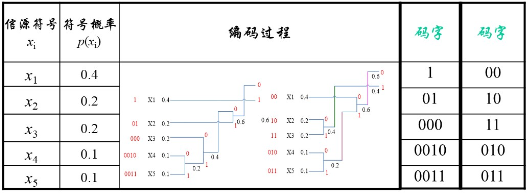
霍夫曼编码是一种编码方式,属于一种程序算法 霍夫曼编码是霍夫曼树在通讯领域的经典应用之一 霍夫曼编码广泛用于数据文件的压缩,压缩率通常在20% 到90%,通常数据的重复率越高,那么压缩率就越高 霍夫曼编码是可变字长编码(VLC)的一种,由霍夫曼提出,又称之为最佳编码 定长编码 对原始数据不加任何的修改,原原本本按照对应的编码集,转成二进制代码进行存储。占用空间大。 变长编码 按照字符出现的次数进行编码,原则上是出现的次数越多,则编码越小。 是比较简洁,但是会出现多义性,因为代码彼此之间有重复。 前缀编码:字符的编码不是其余字符编码的前缀。 霍夫曼编码 对所给字符串的各个字符出现的个数进行统计 按照上面字符出现的次数构建霍夫曼树,次数作为权值,同时你的节点上要有所代表的字符。 根据霍夫曼树给各个字符进行编码: 向左的路径为0,向右的路径为1 根据到达给节点的路径确定该节点代表字符的编码 生成的编码是前缀的编码,每一个编码都不会是另外一个字符的前缀。致使在匹配的时候不会出现多义性 按照上面的霍夫曼编码,将原先的字符换转换成编码。此编码是前缀编码,不会出现多义性,同时又对在定长编码编译情况下原长码进行压缩处理,是无损压缩。 问题:当有大量的字符是相同的出现次数时,相同权值的不同叶子节点可能排在不同的位置,形成不同的霍夫曼树,故而形成不同的代码,但是WPL始终是相同的,所以没有必要担心。最终形成的压缩文件的大小一定相同,因为WPL始终是相同的。 梗概:将每一个字符本身的ASCII码和其出现的次数两者结合,以出现的次数为权构建霍夫曼树,再根据到达对应节点的路径生成对应的霍夫曼编码。 总体步骤:构建相应的霍夫曼树——》遍历读取生成相应的霍夫曼编码 具体分析 节点类:在满足基本节点的特征的基础上,必须把出现的次数作为权值,结点必须包含其本身代表的字符的ASCII码值。同时涉及到构建霍夫曼值,所以必须实现Comparable接口 主类中: 将所给的字符串生成字节型数组 将字节型数组根据自身的内容和出现的次数,生成对应的Node结点(用Map类处理计数),然后转成包含Node的集合类对象list 生成霍夫曼树 遍历霍夫曼树生成对应的霍夫曼编码 Code类: class Node implements Comparable < Node> { Byte date; int weight; Node left; Node right; public Node ( Byte date, int weight) { this . date = date; this . weight = weight; } @Override public int compareTo ( Node o) { return this . weight - o. weight; } @Override public String toString ( ) { return "Node{" + "date=" + date + ", weight=" + weight + '}' ; } public void preOrder ( ) { if ( this != null) { System. out. println ( this ) ; } if ( this . left != null) { this . left. preOrder ( ) ; } if ( this . right != null) { this . right. preOrder ( ) ; } }
}
主类中 private static List< Node> getNodes ( byte [ ] bytes) { List< Node> = new ArrayList < Node> ( ) ; Map< Byte, Integer> = new HashMap < Byte, Integer> ( ) ; for ( byte ch : bytes) { Integer count = counts. get ( ch) ; if ( count == null) { counts. put ( ch, 1 ) ; } else { counts. put ( ch, count + 1 ) ; } } for ( Map. Entry< Byte, Integer> : counts. entrySet ( ) ) { list. add ( new Node ( entry. getKey ( ) , entry. getValue ( ) ) ) ; } return list; }
private static Node huffmanTree ( byte [ ] bytes) { List< Node> = getNodes ( bytes) ; Node left; Node right; while ( list. size ( ) > 1 ) { Collections. sort ( list) ; left = list. get ( 0 ) ; list. remove ( left) ; right = list. get ( 0 ) ; list. remove ( right) ; Node parent = new Node ( null, left. weight + right. weight) ; parent. left = left; parent. right = right; list. add ( parent) ; } return list. get ( 0 ) ; }
static Map< Byte, String> = new HashMap < Byte, String> ( ) ;
static StringBuilder stringBuilder = new StringBuilder ( ) ;
private static void getCodes ( Node node, String code, StringBuilder stringBuilder) { StringBuilder stringBuilder1 = new StringBuilder ( stringBuilder) ; stringBuilder1. append ( code) ; if ( node != null) { if ( node. date == null) { getCodes ( node. left, "0" , stringBuilder1) ; getCodes ( node. right, "1" , stringBuilder1) ; } else { huffmanCodes. put ( node. date, stringBuilder1. toString ( ) ) ; } } }
public static void main ( String[ ] args) { String content = "I like Java.Do you like Java?" ; byte [ ] contentBytes = content. getBytes ( ) ; getCodes ( huffmanTree ( contentBytes) , "" , stringBuilder) ; System. out. println ( "生成的霍夫曼编码表" + huffmanCodes) ;
}
处理处理存在映射关系的两组数据,用Map类,既便于计算出现次数,又便于形成一一对应的关系,用于翻译输出,所以整个过程有两次转换,第一次是在统计各个字符出现的次数,将字节型数组转成Map类;第二次是在由霍夫曼树生成霍夫曼编码时,由树生成Map的编码。 在形成编码的过程中,“边走边成路!”,每一次走不同的结点都会迭代之前的路径生成对应的不同的路径,而路径本身又生成对应的编码。关键点还是还设置一个共有的起点Stringbuilder,共有的记录册HashMap HuffmanCode 总的过程:字符串 —— 》字节型数组——》HashMap<Byte,String>——》ArrayList list——》霍夫曼树——》霍夫曼编码 对于集合类的操作很不流畅,都忘得差不多了,尤其是在遍历键值对的部分关于entry。 package huffmancode; import java. util. *; public class HuffmanCode2 { public static void main ( String[ ] args) { String str = "I have no choice but I have to do!I believe in myself!" ; byte [ ] bytes = str. getBytes ( ) ; System. out. println ( acquireHuffmanCode ( bytes) ) ; } public static Map< Byte, String> acquireHuffmanCode ( byte [ ] bytes) { getHuffmanCode ( getHuffmanTree ( getNode ( bytes) ) , "" , stringBuilder) ; return HuffmanCode; } static Map< Byte, String> = new HashMap < Byte, String> ( ) ; static StringBuilder stringBuilder = new StringBuilder ( ) ; private static void getHuffmanCode ( Node2 node2, String code, StringBuilder stringBuilder) { StringBuilder stringBuilder1 = new StringBuilder ( stringBuilder) ; stringBuilder1. append ( code) ; if ( node2 != null) { if ( node2. ch == null) { getHuffmanCode ( node2. left, "0" , stringBuilder1) ; getHuffmanCode ( node2. right, "1" , stringBuilder1) ; } else { HuffmanCode. put ( node2. ch, stringBuilder1. toString ( ) ) ; } } } private static Node2 getHuffmanTree ( List< Node2> ) { while ( list. size ( ) > 1 ) { Collections. sort ( list) ; Node2 left = list. get ( 0 ) ; Node2 right = list. get ( 1 ) ; list. remove ( left) ; list. remove ( right) ; Node2 parent = new Node2 ( null, left. val + right. val) ; parent. left = left; parent. right = right; list. add ( parent) ; } return list. get ( 0 ) ; } private static List< Node2> getNode ( byte [ ] bytes) { List< Node2> = new ArrayList < Node2> ( ) ; Map< Byte, Integer> = new HashMap < Byte, Integer> ( ) ; for ( byte ch: bytes) { Integer count = counts. get ( ch) ; if ( count != null) { counts. put ( ch, count + 1 ) ; } else { counts. put ( ch, 1 ) ; } } for ( Map. Entry< Byte, Integer> : counts. entrySet ( ) ) { list. add ( new Node2 ( enty. getKey ( ) , enty. getValue ( ) ) ) ; } return list; } }
class Node2 implements Comparable < Node2> { public Byte ch; int val; Node2 left; Node2 right; public Node2 ( Byte ch, int val) { this . ch = ch; this . val = val; } @Override public String toString ( ) { return "Node2{" + "ch=" + ch + ", val=" + val + '}' ; } @Override public int compareTo ( Node2 o) { return this . val - o. val; }
}