虚拟内存页面置换算法
- 虚拟地址空间
- 页表
- 分页式
- 分段式
- 段页式
- 页面置换算法
- 最优置换算法( OPT)
- 先进先出算法(FIFO)
- 最近最久未使用算法(LRU)
虚拟内存是计算机系统内存管理的一种技术。
它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。
目前,大多数操作系统都使用了虚拟内存,如Windows家族的“虚拟内存”;Linux的“交换空间”等
虚拟地址空间
在C语言中我们称之为程序地址空间,而Linux下称之为进程虚拟地址空间。

#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>int main()
{pid_t pid = fork();int g_val = 10;if(pid < 0){perror("fork");return 0;}else if(pid == 0){ //child,子进程肯定先跑完,也就是子进程先修改//完成之后,父进程再读取g_val=100;printf("child [%d]: [%d] : [%p]\n", getpid(), g_val, &g_val);}else{ //parentsleep(3);printf("parent [%d]: [%d] : [%p]\n", getpid(), g_val, &g_val);}sleep(1);return 0;
}
运行之后我们发现变量内容不一样,所以父子进程输出的变量绝对不是同一个变量,但他们的地址值是一样的,说明,该地址绝对不是物理地址!
在Linux地址下,这种地址叫做虚拟地址,而我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理,这块就涉及一个写时拷贝的概念。
- 写时拷贝 : 当数据发生修改的时候,才重新分配一个物理内存,并将页表当中的映射关系改掉
- 物理内存: 存储数据时需要依靠的介质
- 逻辑地址: 进程虚拟地址空间,也就是人为规定的,不能存储数据的.
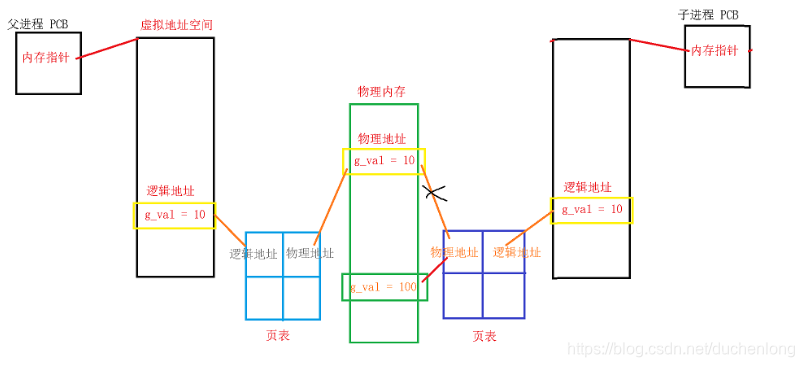
页表
页表的作用是将虚拟地址映射成物理地址
页表的存储在汇编中就是 段基址 * 16 + 偏移量,段基址是页内偏移,块号是偏移量。
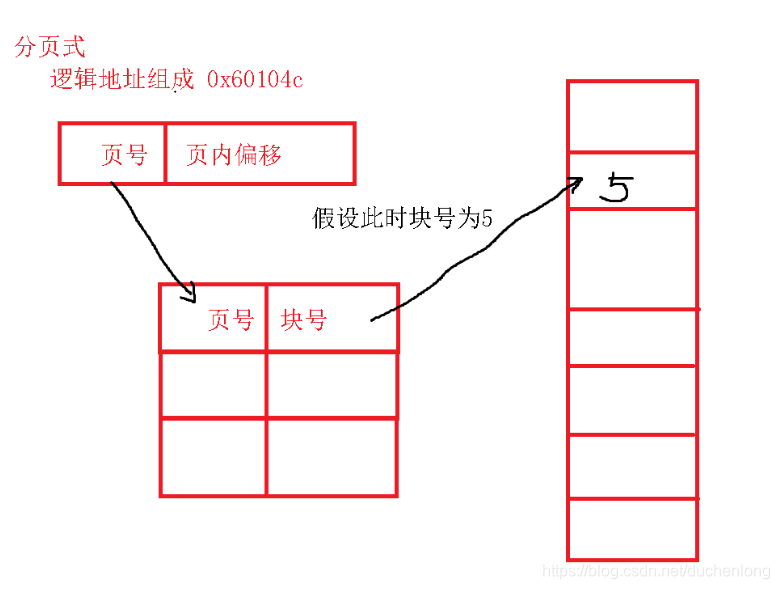
分页式
前提:会将虚拟地址分成一页一页的格式,会将物理内存分成一块一块的格式。
分页的原因:假设我们有一个16M大小的存储空间,因为计算机存储的时候,地址都是随机分配的,如果很不凑巧,这段空间的正中间的位置分配一个8M大小的数据,那么之后要是再存储一个5M大小的数据就会出现存不下的问题,这就造成了内存的浪费。
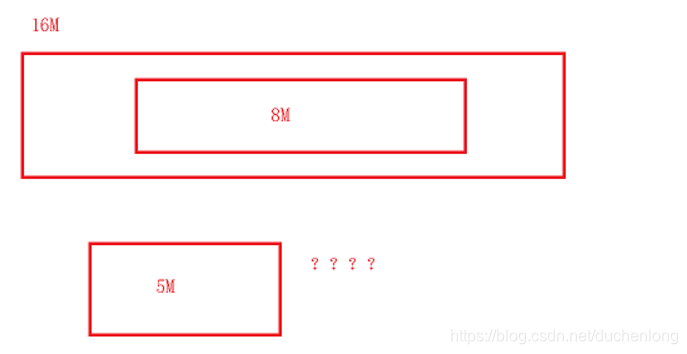
分页式的存储就和书差不多,把知识点都分成一页一页的,然后每一块知识点都有一个目录,可以通过目录很快的找到这一块的位置,然后在这一页中找知识点,唯一有区别的就是,在计算机中,每一块物理内存的大小都是一样的。
- 块号: 根据页号在页表中的映射去查找的块的标号
假设虚拟地址为5000,块的大小是4096,如何计算物理地址? - 页号 = 虚拟地址 / 块大小
- 页内偏移 = 虚拟地址 % 块的大小
- 块的起始地址 = 块号 * 大小
- 物理地址 = 块的起始地址 + 页内偏移
页号 : 5000 / 4096 = 1
页内偏移 :5000 % 4096 = 904
块的起始地址 :5 * 4096
物理地址 : 5 * 4096 +904`
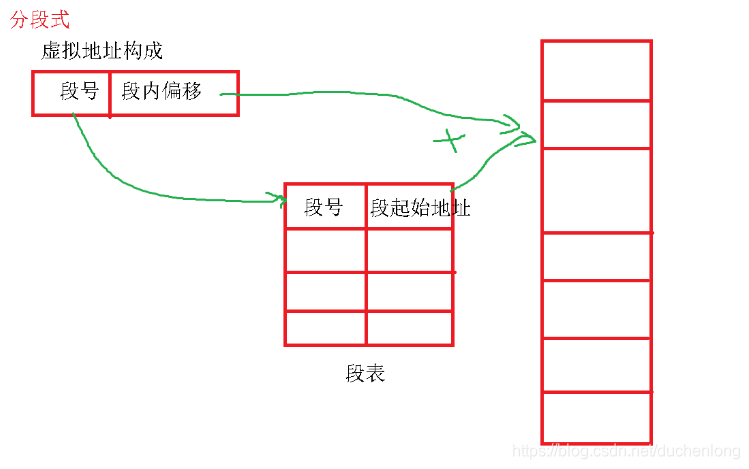
分段式
将虚拟地址映射成物理地址的结构不是页表了,而是段表。它的存储是将一个数据段直接放在物理内存中。
先根据段号从段表中找到对应的段的起始地址,再通过 段内偏移 + 段的起始地址 =物理地址。
分段式和分页式对比
分页式数据存储效率高,分段式效率低。
分段式对程序很友好,可以通过段表的结构,找到虚拟地址空间当中的一段。
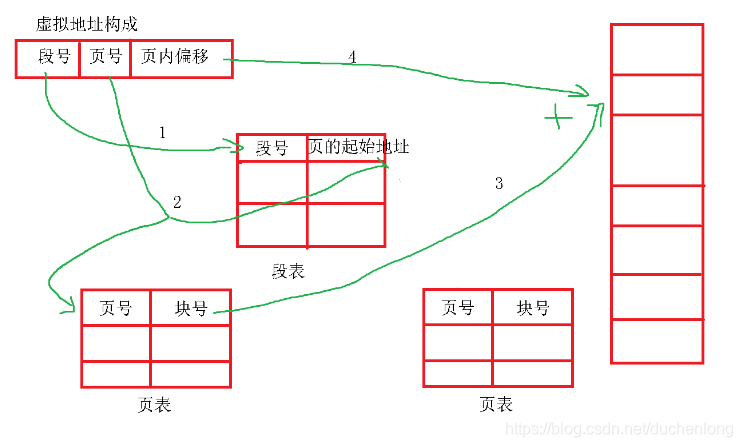
段页式
存储时采取了段表结构和页表结构。
先根据段号来找到段表中页的起始地址,然后找到对应是那一页,再根据页号找到该页表中的块号,最后通过块号算出块的起始地址,块的起始地址 + 页内偏移 = 物理地址。
页面置换算法
源码地址:https://github.com/duchenlong/linux-text/tree/master/page
页面置换算法产生的原因:由于虚拟地址空间中,他本身并不具备存储数据的能力,只是将部分数据存储在外存中,当使用该数据的时候,才将他加载到内存中;
但因为内存空间有限,所以说终究会出现内存已满的情况,这个时候就需要将内存中的部分空间转移到外存中,再将该页面加载到内存
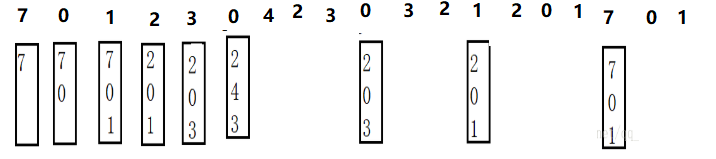
最优置换算法( OPT)
缺页中断发生时,对保存在内存中的每一个逻辑页面,计算在他下一次访问之前还需等待多长时间,从中选择等待时间最长的那个,作为被置换。
这是理想情况,需要预知未来,一般用于其他算法性能评估
#include <list>
#include <vector>
#include <iostream>
#include <unordered_map>
#include <algorithm>
#include <string>using namespace std;class MyOpt{private:vector<int> _vec;list<int> _list;int _capacity;unordered_map<int,list<int>::iterator> _hash;public:MyOpt(vector<int>& vec,int num) {_vec = vec;_capacity = num;}bool get(int value);void put(int value,int pos);void show();int find(int value,int pos);
};int MyOpt::find(int value,int pos) {int n = _vec.size();for(int i = pos; i < n; i++) {if(_vec[i] == value) return i;}return -1;
}bool MyOpt::get(int value) {if(_hash.count(value) == 0) return false;return true;
}void MyOpt::put(int value,int pos) {if(get(value))return ;if((int)_hash.size() == _capacity) {// 删除auto it = _list.begin();auto del = it;auto span = _vec.begin() + pos;for(; it != _list.end(); it++) {auto it_e = std::find(_vec.begin() + pos,_vec.end(),*it);if(it_e == _vec.end()) {del = it;break;} else if(it_e > span){span = it_e;del = it;}}_hash.erase(*del);_list.erase(del);}_list.push_back(value);_hash[value] = _list.end()--;
}void MyOpt::show() {for(auto& e : _list)cout << e << " ";cout << endl;
}先进先出算法(FIFO)
缺页中断发生时,系统选择在内存中驻留时间最长的页面淘汰。通常采用链表记录进入物理内存中的逻辑页面,链首时间最长。
该算法实现简单,但性能较差,调出的页面可能是经常访问的页面,而且进程分配物理页面数增加时,缺页并不一定减少(Belady现象)
#include <list>
#include <iostream>
#include <unordered_map>using namespace std;class MyFifo{private:unordered_map<int,list<int>::iterator> _hash;list<int> _list;int _capacity;public:MyFifo(int num){_capacity = num;}bool get(int value);void put(int value);void show();
};bool MyFifo::get(int value){if(_hash.count(value) == 0) return false;return true;
}void MyFifo::put(int value) {if(get(value) == true) return ;if((int)_hash.size() == _capacity) {// 头删auto f = _list.front();_hash.erase(f);_list.pop_front();}_list.push_back(value);_hash[value] = _list.end()--;
}void MyFifo::show() {for(auto& e : _list) {cout << e << " ";}cout << endl;
}最近最久未使用算法(LRU)
算法思想是缺页发生时,选择最长时间没有被引用的页面进行置换,如某些页面长时间未被访问,则它们在将来还可能会长时间不会访问。

使用的方法:一个带头结点的双向循环链表
- 每次插入数据,都在链表的头部插入,表示近期被使用
- 查找数据的时候,把该数据移动到链表的头部,近期被使用
- 需要替换的时候,就删除掉链表的尾部数据,他是近期使用次数最少的
#include <list>
#include <unordered_map>
#include <iostream>using namespace std;class MyLRU{private:unordered_map<int,list<int>::iterator> _hash;list<int> _list;int _capacity;public:MyLRU(int num){_capacity = num;}bool get(int value);void put(int value);void show();
};bool MyLRU::get(int value) {if(_hash.count(value) == 0) return false;auto node = _hash[value];_list.erase(node);_list.push_front(value);_hash[value] = _list.begin();return true;
}void MyLRU::put(int value) {if(get(value)) return ;if((int)_hash.size() == _capacity) {// 尾删auto del = _list.back();_hash.erase(del);_list.pop_back();}_list.push_front(value);_hash[value] = _list.begin();
}void MyLRU::show() {for(auto& e : _list) {cout << e << " ";}cout << endl;
}