1. ESN的任务
给定一段信号: u ( 0 ) , u ( 1 ) , ⋅ ⋅ ⋅ , u ( N t − 1 ) u(0),u(1),···,u(N_t-1) u(0),u(1),⋅⋅⋅,u(Nt−1)
和目标值: v ( 1 ) , v ( 2 ) , ⋅ ⋅ ⋅ , v ( N t ) v(1),v(2),···,v(N_t) v(1),v(2),⋅⋅⋅,v(Nt)
学习一个黑箱模型M使得我们可以预测 v ( N t + 1 ) , v ( N t + 2 ) , ⋅ ⋅ ⋅ v(N_t+1),v(N_t+2),··· v(Nt+1),v(Nt+2),⋅⋅⋅
优势:与传统的递归神经网络相比,ESN最大的优势是简化了网络的训练过程,解决了传统递归神经网络结构难以确定、训练算法过于复杂的问题,同时也可以克服递归网络存在的记忆消减等问题(ESN的训练方法与传统的递归神经网络有本质不同)。
ESN解决问题的思想:使用大规模随机稀疏网络(储备池)作为信息处理媒介,将输入信号从低维的输入空间映射到高维的状态空间,在高维的状态空间采用线性回归方法对网络的部分连接权进行训练,而其他连接权随机产生,并在网络训练过程中保持不变。这种思想在Steil关于传统递归神经网络的经典算法(Atiya-Parlos)的研究中也得到了验证:递归神经网络输出连接权改变迅速,而内部连接权则以高度耦合的方式缓慢改变。也就是说,如果递归神经网络内部连接权选择合适,在对网络进行训练时可以忽略内部连接权的改变。
2. ESN的结构和训练步骤
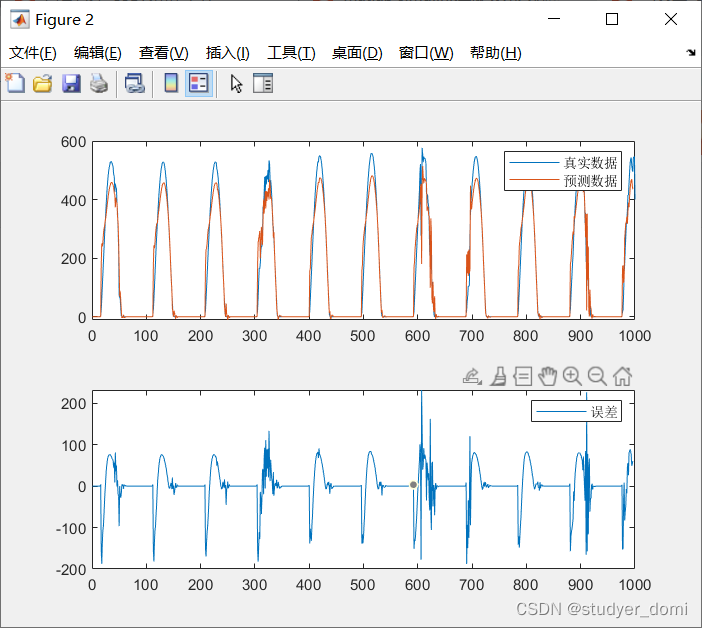
 ESN的结构如上图所示,其中:
ESN的结构如上图所示,其中:
中间的大圆圈叫做“储备池”,它有以下特点:
(1)包含数目较多的神经元(与经典神经网络相比);
(2)神经元之间的连接关系随机产生;
(3)神经元之间的连接具有稀疏性。
u ∈ R M ∗ 1 u\in R^{M*1} u∈RM∗1, W I R ∈ R N ∗ M W_{IR}\in R^{N*M} WIR∈RN∗M, W r e s ∈ R N ∗ N W_{res}\in R^{N*N} Wres∈RN∗N, r ∈ R N ∗ 1 r\in R^{N*1} r∈RN∗1, W R O ∈ R L ∗ N W_{RO}\in R^{L*N} WRO∈RL∗N, v ∈ R L ∗ 1 v\in R^{L*1} v∈RL∗1
上面的两个参数矩阵 W I R ∈ R N ∗ M W_{IR}\in R^{N*M} WIR∈RN∗M和 W r e s ∈ R N ∗ N W_{res}\in R^{N*N} Wres∈RN∗N都是事先给定的数值,在训练的过程中只需要计算 W R O ∈ R L ∗ N W_{RO}\in R^{L*N} WRO∈RL∗N即可。
整个计算过程如下所示:
(1)从输入到储备池(reservoir)的运算: W I R ∗ u ( t ) W_{IR}*u(t) WIR∗u(t)
(2)储备池中 r ( t ) r(t) r(t)的更新: r ( t + Δ t ) = f [ W r e s ∗ r ( t ) + W I R ∗ u ( t ) ] r(t+\Delta t)=f[W_{res}*r(t)+W_{IR}*u(t)] r(t+Δt)=f[Wres∗r(t)+WIR∗u(t)]
(3)从储备池到输出: W R O ∗ r ( t ) W_{RO}*r(t) WRO∗r(t)
(4)损失函数: L = ∑ t = d + 1 N t ∣ v ( t ) − W R O ∗ r ( t ) ∣ 2 L=\sum_{t=d+1}^{N_t}|v(t)-W_{RO}*r(t)|^2 L=∑t=d+1Nt∣v(t)−WRO∗r(t)∣2
(6)使损失函数最小化的推导过程:



3. ESN的预测步骤
当 W R O W_{RO} WRO确定之后,库的输出为:
u ( t ) = W R O ∗ r ( t ) u(t)=W_{RO}*r(t) u(t)=WRO∗r(t)
r ( t + Δ t ) = f [ W r e s ∗ r ( t ) + W I R ∗ u ( t ) ] r(t+\Delta t)=f[W_{res}*r(t)+W_{IR}*u(t)] r(t+Δt)=f[Wres∗r(t)+WIR∗u(t)]
u ( t + Δ t ) = W R O ∗ r ( t + Δ t ) u(t+\Delta t)=W_{RO}*r(t+\Delta t) u(t+Δt)=WRO∗r(t+Δt)
···
热启动方式:使用训练步中最后一个阶段的库状态作为预测中的 r ( t ) r(t) r(t);
冷启动方式:使用一个新的数据作为库的初始值

预测的时候不会再给单独的输入了,而是会将输出作为输入进行递推计算。
一般 W I R W_{IR} WIR各元素会初始化为 [ − α , α ] [-\alpha,\alpha] [−α,α]之间的均匀分布。
每个输入 u ( t ) u(t) u(t)都会和 N / M N/M N/M个库中的节点相连,因为输入个数时M,库中有N个节点,
即: u ∈ R M ∗ 1 u\in R^{M*1} u∈RM∗1, r ∈ R N ∗ 1 r\in R^{N*1} r∈RN∗1
W r e s W_{res} Wres通常是一个大型,稀疏,有向或无向的随机网络,平均度为k,谱半径 ρ ( W r e s ) \rho (W_{res}) ρ(Wres)是 W r e s W_{res} Wres最大的特征值。
W r e s W_{res} Wres会初始化为一个稀疏矩阵。
4. ESN的代码
import pickle
import numpy as np
import matplotlib.pyplot as pltclass ESN():def __init__(self, data, N=1000, rho=1, sparsity=3, T_train=2000, T_predict=1000, T_discard=200, eta=1e-4, seed=2050):self.data = dataself.N = N # reservoir size 库的大小self.rho = rho # spectral radius 谱半径self.sparsity = sparsity # average degree 平均度 sparsity:稀疏性self.T_train = T_train # training stepsself.T_predict = T_predict # prediction stepsself.T_discard = T_discard # discard first T_discard steps discard:丢弃self.eta = eta # regularization constant 正则化常数self.seed = seed # random seeddef initialize(self):"""对连接权矩阵W_IR和W_res进行初始化其中W_IR(N*1)是从输入到库的连接权矩阵,W_res(N*N)是从库到输出的连接权矩阵"""if self.seed > 0:np.random.seed(self.seed)# 生成形状为N * 1的,元素为[-1, 1]之间的随机值的矩阵self.W_IR = np.random.rand(self.N, 1) * 2 - 1 # [-1, 1] uniform# 生成形状为N * N的,元素为[0, 1]之间的随机值的矩阵W_res = np.random.rand(self.N, self.N)# 将W_res中大于self.sparsity / self.N的元素置0W_res[W_res > self.sparsity / self.N] = 0\# np.linalg.eigvals(W_res)求出W_res的特征值,W_res矩阵除以自身模最大的特征值的模W_res /= np.max(np.abs(np.linalg.eigvals(W_res)))# 在乘以谱半径W_res *= self.rho # set spectral radius = rhoself.W_res = W_resdef train(self):u = self.data[:, :self.T_train] # traning data T_train = 2000assert u.shape == (1, self.T_train)r = np.zeros((self.N, self.T_train + 1)) # initialize reservoir state r(N*(T_train + 1))for t in range(self.T_train):# @是Python3.5之后加入的矩阵乘法运算符r[:, t+1] = np.tanh(self.W_res @ r[:, t] + self.W_IR @ u[:, t])# disgard first T_discard steps r丢弃前T_discard步变成r_pself.r_p = r[:, self.T_discard+1:] # length=T_train-T_discardv = self.data[:, self.T_discard+1:self.T_train+1] # targetself.W_RO = v @ self.r_p.T @ np.linalg.pinv(self.r_p @ self.r_p.T + self.eta * np.identity(self.N))train_error = np.sum((self.W_RO @ self.r_p - v) ** 2)print('Training error: %.4g' % train_error)def predict(self):u_pred = np.zeros((1, self.T_predict)) # u_pred是形状为(1, self.T_predict)的全零矩阵r_pred = np.zeros((self.N, self.T_predict)) # r_pred是形状为(N, self.T_predict)的全零矩阵r_pred[:, 0] = self.r_p[:, -1] # warm start 热启动for step in range(self.T_predict - 1):u_pred[:, step] = self.W_RO @ r_pred[:, step]r_pred[:, step + 1] = np.tanh(self.W_res @r_pred[:, step] + self.W_IR @ u_pred[:, step])u_pred[:, -1] = self.W_RO @ r_pred[:, -1]self.pred = u_preddef plot_predict(self):ground_truth = self.data[:,self.T_train: self.T_train + self.T_predict]plt.figure(figsize=(12, 4))plt.plot(self.pred.T, 'r', label='predict', alpha=0.6)plt.plot(ground_truth.T, 'b', label='True', alpha=0.6)plt.show()def calc_error(self):ground_truth = self.data[:,self.T_train: self.T_train + self.T_predict]rmse_list = []for step in range(1, self.T_predict+1):error = np.sqrt(np.mean((self.pred[:, :step] - ground_truth[:, :step]) ** 2))rmse_list.append(error)return rmse_listif __name__ == "__main__":# http://minds.jacobs-university.de/mantas/codedata = np.load('mackey_glass_t17.npy') # data.shape = (10000,)data = np.reshape(data, (1, data.shape[0])) # data.shape = (1, 10000)print(data.shape)esn = ESN(data)esn.initialize()esn.train()esn.predict()esn.plot_predict()
上面所用到的mackey_glass_t17.npy数据集可在下面的链接中找到:
链接:https://pan.baidu.com/s/1UX3ZAMjF1pQFMe6Ru8dqsQ
提取码:uf8y
复制这段内容后打开百度网盘手机App,操作更方便哦
参考