这是WinPcap的NPF驱动核心指南原文的翻译,英语水平有限,翻译得可能不是很准确。
这个章节说明网络组包过滤(NPF)组件-WinPcap的核心部分。一般用户可能只对WinPcap的使用感兴趣,但不一定想了解它的组件结构。因此这些信息只要是提供给WinPcap的开发者和维护者,或是对驱动是如何运行有兴趣的人所参考。尤其是,对操作系统、网络和Win32核心编程、设备驱动开发比较熟悉的话对于阅读这个章节比较有帮助。
NPF作为WinPcap组件的一部分,它向用户层提供了处理在网络上传输的数据包,对数据包进行捕获,发送和分析的能力。
下面的段落将会阐述NPF同操作系统和它的基本结构的相互配合。
一、NPF 与 NDIS 区别
NDIS(网络驱动接口规范)这个标准规定了网络适配器和协议驱动之间如何通信。
NDIS的主要目的是扮演一个包装器的角色,让协议驱动可以在网络(LAN或WAN)上发送和接收包,且不用关心具体的适配器和具体的Win32操作系统。
NDIS支持下面三种类型的网络驱动:
1.网络接口卡或NIC驱动
NIC驱动直接管理网络接口卡,被称为NICs。NIC驱动下边与硬件连接,从上边表现为一个接口,该接口允许高层发送数据包到网络上,处理中断,重设NIC,中止NIC,查询和设置驱动的运行特征。NIC驱动可以是小端口(miniports)或是传统的完全的NIC驱动。
1)迷你端口驱动仅仅实现了管理NIC所必需的硬件具体操作,包含在NIC上发送和接收数据。对于所有的最底层的NIC驱动来说,如NDIS提供的同步,所有的操作都是相同的。迷你端口并不直接调用系统调用;它们面向操作系统的接口是NDIS。
迷你端口仅仅向上传送数据包给NDIS,而NDIS要保证这些数据包都能被传送给正确的协议。
2)完全的NIC驱动完成硬件细节的操作和所有由NDIS完成的同步和查询操作。例如,完全NIC驱动维持接收到的数据的绑定信息。
2.中间层驱动
中间层驱动接口位于高层驱动(例如协议驱动)和迷你端口之间。对于高层驱动来说,中间层驱动就像是迷你端口;但对于迷你端口来说,中间层驱动就像协议驱动。一个中间层协议驱动可以位于另一个中间层驱动之上,尽管这种分层可以对系统性能产生负面影响。开发中间层驱动的一个关键原因是在现存的传统协议驱动(legacy protocol driver)和小端口之间形成媒体的转化。例如,中间层驱动可以将LAN协议转换成ATM协议。中间层驱动不能与用户模式的应用程序通信,只能与其他的NDIS驱动通信。
3.传输驱动或协议驱动
一个协议驱动实现了一个网络驱动栈,就如IPX/SPX或是TCP/IP,在一个或者多个网络接口卡上提供服务。在协议驱动的上面,它为应用层客户程序服务;在它的下面,它与一个或多个NIC驱动或中间层NDIS驱动连接。
NPF被实现为一个协议驱动。
从性能的观点上来说这不是最好的选择,但允许跟MAC层保持合理的独立性,以及对raw traffic的完全访问。注意不同的Win32操作系统有不同的NDIS版本:NDIS 5在Windows 2000以及它的衍生版本(如Windows XP)上兼容,NDIS 3兼容其它的Win 32平台。
下图显示了NPF在NDIS栈里的位置:
图1:NPF在NDIS中
与操作系统地交互通常是异步的。
这意味着驱动提供了一系统的回调函数,让某些操作需要NPF时供系统调用。NPF为所有应用程序的I/O操作导出了回调函数:open, close, read, write,ioctl等。
与NDIS的交互也是异步的。
新包的到达作为一个事件通过回调函数(在这里是Packet_tap())通知NPF。此外,NDIS和NIC驱动的交互总是通过非阻塞函数进行的:当NPF调用一个NDIS函数时,调用立即返回;当处理结束时,NDIS调用一个具体的NPF回调来通知函数已经完成了。驱动为所有的低层操作(如发送数据包,在NIC上设置或是请求参数等)导出了一个回调。
NPF基本结构
下图展示了WinpCap的结构,特别是NPF驱动的说明。

图2:NPF设备驱动
NPF能够执行几个不同的操作:捕获、监测、转储到磁盘和数据包发送。下面的段落会对各个操作进行简短地介绍。
数据包捕获
NPF最重要的操作就是数据包捕获了。在捕获时,驱动使用网络接口嗅探数据包,并把它们完好地转交给用户层应用程序。
捕获过程依赖于两个主要的组件:
1.数据包过滤器决定一个进来的数据包是否要被接受和拷贝给监听应用程序。大多数使用NPF的应用程序拒绝的数组包远多于那些被接受的,因此一个多功能和高效率的数据包过滤器起着关键性的作用。数据包过滤器是一个应用在数据包上,最终返回布尔值的函数。如果函数返回true的话,捕获驱动会把数据包拷贝给应用程序;否则就直接丢弃数据包。NPF数据包过滤器有点复杂,因为它不仅仅要决定数据包是否要被保存下来,还要决定数据包保存下来的比特数(即只保存数组包的一部分)。NPF设备采用的过滤系统源于BSD Packet Filter(BPF)--一个能够运行创建在用户级上、用汇编语言编写的过滤程序的虚拟处理机。应用程序需要一个用户定义的过滤器(例如"pick up all UDP packets")并使用wpcap.dll将它们编译成一个BPF程序(例如“if the packet is IP and the protocol type field is equal to 17, then return true” )。然后,应用程序使用BIOCSETF IOCTL在内核里注入过滤器。从这点上看,每进入一个数据包,程序就执行一次,且只有conformant 的数据包被接收。不像传统的解决方法,NPF并不解释过滤器,而是执行它们。由于性能的原因,在使用过滤器前,NPF把它传送给一个JIT编译器,以便把它转化成一个本地的80x86函数。当捕获到一个数据包时,NPF调用这个本地函数取代使用翻译器,这使得速度非常快。这背后的优化概念非常类似于JAVA的一个jitter。
2.一个用来保存数据包和避免丢包的循环缓冲区。一个数据包连同一个头部保存在缓冲区,头部主要是维护像时间戳和数据包的大小之类的信息。此外,为了加速应用程序访问数据包的数据,在不同数据包之间插入了一些对齐填充。仅用一个操作就可以把一组数据包从NPF缓冲区中拷贝到应用程序里。这提高了性能,因为它最小化了读取的次数。当缓冲区满时,恰好又有一个新的数据包到达,就仅仅是简单地丢弃它。为了达到最大化动态性,内核和用户缓冲区的大小都可以在运行时刻改变:packet.dll和wpcap.dll提供了这个用途的相关函数。
用户缓冲区的大小是非常重要的,这决定着一个系统调用一次可以从内核空间拷贝到用户空间的数据的最大数量。从另一方面说,要注意系统调用一次能够从内核空间拷贝到用户空间的数据的最小数量也是极其重要的。这个变量的值取得比较大时,内核需要等待若干个数据包到达时才把数据拷贝到用户空间。这样就保存比较少次数的系统调用,换言之就是比较低的CPU使用率了,这对于像嗅探器之类的应用程序是比较好的设置。在另一方面,取值较小意味着一旦应用程序准备就绪,内核就会马上复制数据包。这对于那些需要从内核得到快速响应的实时应用来说是非常有效的。从这点来看,NPF拥有配置的能力,使用户可以从高效率和高响应性(或任何中间情况)之间作出抉择。
winpcap库包含一对可用来设置一个读操作超时时间和可以传递给应用程序的数据量的最小值的系统调用。默认情况下,读操作的超时时间为1秒,内核复制给应用程序的数据量的最小值为16K。
数据包发送
NPF允许写一个原始的数据包并发送到网络上。为了发送数据,用户层应用程序需要在NPF设备文件上执行一个WriteFile()的系统调用。数据发送到网络上时并不会进行任何协议的封装,因此应用程序必须亲自为各个数据包包装好各个头部。应用程序通常并不需要生成FCS,因为在数据包被发送到网络上前网络适配器硬件会进行计算并自动附在数据包的尾部。
在正常的情况下,数据包的发送速率并不是很高,因为每个数据包都需要一次系统调用。由于这个原因,通过一次写操作的系统调用来多次发送同一个数据包的可能性增加。用户层应用程序能够通过调用一个IOCTL来设置重复发送同一个数据包的次数:例如,如果设置为1000,应用程序写入到系统设备文件的每个原始数据包都会被发送1000次。这个特点能够被用来产生高速流量从而达到测试的目的:上下文切换的负荷不再是个问题,因此性能非常好。
网络监测
WinPcap提供了一个内核层的可编程的监测模块,它能够对网络流量进行简单的统计计算。模块背后的构思在图2展示了:不需要复制数据包到应用层空间就能够收集到统计资料,只需要简单地接收和显示从监测引擎获得的结果即可。这避免了捕获过程需要耗费很多的内存空间和CPU时间。
这个监测引擎由一个带着计数器的分类器构成。数据包被一个NPF的过滤引擎进行分类,过滤引擎提供了选择一个流量的子集的配置方式。没被过滤掉的数据会进入计数器,计数器拥有一些变量,一个用来保存数据包的数量,一个用来保存过滤器接收的字节数,并通过新进入的数据包进行不断更新。这些变量会定期传递给用户层应用程序,时间可以由用户自行配置。在内核层和用户层没有分配缓冲区。
转储到磁盘
转储到磁盘的能力可以让我们直接从内核模式下保存网络数据到磁盘上。
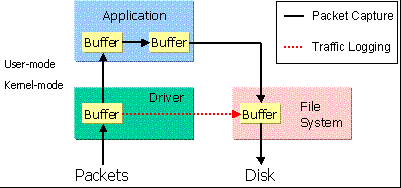
在传统的系统里,数据包保存到磁盘里的路径如图3的黑色箭头所指:每个数据包都被复制了几次,通常分配了四个缓冲区:一个处于捕获驱动里,一个在捕获数据的应用程序里,一个在应用程序用来进行写文件的标准输入输出函数里,最后一个在文件系统里。
当处于内核级的NPF流量记录功能被启用时,捕获驱动直接同文件系统进行通信,因此数据包保存到磁盘里的路径是红色箭头所指向的:仅需要两个缓冲区,并且只需复制一次,系统调用的次数锐减,因此性能更好。
当前转储到磁盘的实现是广泛使用libpcap格式。它可以在转储前过滤数据包,以便只选择那些需要保存到磁盘的数据包。
【本文摘自 感谢作者】
http://www.cnblogs.com/coolzgx/archive/2010/01/23/1654537.html