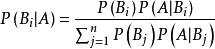贝叶斯分类器做文本分类
文本分类是现代机器学习应用中的一大模块,更是自然语言处理的基础之一。我们可以通过将文字数据处理成数字数据,然后使用贝叶斯来帮助我们判断一段话,或者一篇文章中的主题分类,感情倾向,甚至文章体裁。现在,绝大多数社交媒体数据的自动化采集,都是依靠首先将文本编码成数字,然后按分类结果采集需要的信息。虽然现在自然语言处理领域大部分由深度学习所控制,贝叶斯分类器依然是文本分类中的一颗明珠。现在,我们就来学习一下,贝叶斯分类器是怎样实现文本分类的。
文本编码技术简介
单词计数向量
在开始分类之前,我们必须先将文本编码成数字。一种常用的方法是单词计数向量。在这种技术中,一个样本可以包 含一段话或一篇文章,这个样本中如果出现了10 个单词,就会有 10个 特征
(n=10),每个特征代表一个单词,特征的取值表示这个单词在这个样本中总共出现了几次,是一个离散的,代表次数的,正整数 。
(n=10),每个特征代表一个单词,特征的取值表示这个单词在这个样本中总共出现了几次,是一个离散的,代表次数的,正整数 。
在 sklearn 当中,单词计数向量计数可以通过 feature_extraction.text 模块中的 CountVectorizer 类实现,来看一个简单的例子:
sample = ["Machine learning is fascinating, it is wonderful","Machine learning is a sensational techonology","Elsa is a popular character"]
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
X = vec.fit_transform(sample)
print(X)#使用接口get_feature_names()调用每个列的名称
import pandas as pd
#注意稀疏矩阵是无法输入pandas的
CVresult = pd.DataFrame(X.toarray(),columns = vec.get_feature_names())
CVresult结果:

TF-IDF
TF-IDF全称term frequency-inverse document frequency,词频逆文档频率,是通过单词在文档中出现的频率来衡量其权重,也就是说,IDF的大小与一个词的常见程度成反比,这个词越常见,编码后为它设置的权重会倾向于越小,以此来压制频繁出现的一些无意义的词。在sklearn当中,我们使用feature_extraction.text中类TfidfVectorizer 来执行这种编码。
from sklearn.feature_extraction.text import TfidfVectorizer as TFIDF
vec = TFIDF()
X = vec.fit_transform(sample)
X结果:
#同样使用接口get_feature_names()调用每个列的名称
TFIDFresult = pd.DataFrame(X.toarray(),columns=vec.get_feature_names())
TFIDFresult
结果:

#使用TF-IDF编码之后,出现得多的单词的权重被降低了么?
CVresult.sum(axis=0)/CVresult.sum(axis=0).sum()
结果:
character 0.0625
elsa 0.0625
fascinating 0.0625
is 0.2500
it 0.0625
learning 0.1250
machine 0.1250
popular 0.0625
sensational 0.0625
techonology 0.0625
wonderful 0.0625
dtype: float64TFIDFresult.sum(axis=0) / TFIDFresult.sum(axis=0).sum()结果:
character 0.083071
elsa 0.083071
fascinating 0.064516
is 0.173225
it 0.064516
learning 0.110815
machine 0.110815
popular 0.083071
sensational 0.081192
techonology 0.081192
wonderful 0.064516
dtype: float64案例
探索文本数据
在现实中,文本数据的处理是十分耗时耗力的,尤其是不规则的长文本的处理方式,绝对不是一两句话能够说明白的,因此这里我们使用的数据集是sklearn自带的文本数据集fetch_20newsgroup。这个数据集是20个网络新闻组的语料库,其中包含约2万篇新闻,全部以英文显示,如果大家希望使用中文则处理过程会更加困难,会需要自己加载中文的语料库。在这个例子中,主要目的是为大家展示贝叶斯的用法和效果,因此我们就使用英文的语料库。
from sklearn.datasets import fetch_20newsgroups
#初次使用这个数据集的时候,会在实例化的时候开始下载
data = fetch_20newsgroups()
#通常我们使用data来查看data里面到底包含了什么内容,但由于fetch_20newsgourps这个类加载出的数据巨大,数
#据结构中混杂很多文字,因此很难去看清
#不同类型的新闻
data.target_names
#其实fetch_20newsgroups也是一个类,既然是类,应该就有可以调用的参数
#面对简单数据集,我们往往在实例化的过程中什么都不写,但是现在data中数据量太多,不方便探索
#因此我们需要来看看我们的类fetch_20newsgroups都有什么样的参数可以帮助我们结果:

import numpy as np
import pandas as pd
categories = ["sci.space" #科学技术 - 太空,"rec.sport.hockey" #运动 - 曲棍球,"talk.politics.guns" #政治 - 枪支问题,"talk.politics.mideast"] #政治 - 中东问题
train = fetch_20newsgroups(subset="train",categories = categories)
test = fetch_20newsgroups(subset="test",categories = categories)#可以观察到,里面依然是类字典结构,我们可以通过使用键的方式来提取内容
train.target_names结果:


使用TF-IDF将文本数据编码
from sklearn.feature_extraction.text import TfidfVectorizer as TFIDF
Xtrain = train.data
Xtest = test.data
Ytrain = train.target
Ytest = test.targettfidf = TFIDF().fit(Xtrain)
Xtrain_ = tfidf.transform(Xtrain)
Xtest_ = tfidf.transform(Xtest)Xtrain_结果:
tosee = pd.DataFrame(Xtrain_.toarray(),columns=tfidf.get_feature_names())
tosee.head()结果:
tosee.shape结果:

在贝叶斯上分别建模,查看结果
from sklearn.naive_bayes import MultinomialNB, ComplementNB, BernoulliNB
from sklearn.metrics import brier_score_loss as BS
name = ["Multinomial","Complement","Bournulli"] #注意高斯朴素贝叶斯不接受稀疏矩阵
models = [MultinomialNB(),ComplementNB(),BernoulliNB()]
for name,clf in zip(name,models):clf.fit(Xtrain_,Ytrain)y_pred = clf.predict(Xtest_)proba = clf.predict_proba(Xtest_)score = clf.score(Xtest_,Ytest)print(name)#4个不同的标签取值下的布里尔分数Bscore = []for i in range(len(np.unique(Ytrain))):bs = BS(Ytest,proba[:,i],pos_label=i)Bscore.append(bs)print("\tBrier under {}:{:.3f}".format(train.target_names[i],bs))print("\tAverage Brier:{:.3f}".format(np.mean(Bscore)))print("\tAccuracy:{:.3f}".format(score))print("\n")结果:
Multinomial
Brier under rec.sport.hockey:0.018
Brier under sci.space:0.033
Brier under talk.politics.guns:0.030
Brier under talk.politics.mideast:0.026
Average Brier: 0.027
Accuracy: 0.975Complement
Brier under rec.sport.hockey:0.023
Brier under sci.space:0.039
Brier under talk.politics.guns:0.039
Brier under talk.politics.mideast:0.033
Average Brier:0.033
Accuracy: 0.986Bournulli
Brier under rec.sport.hockey: 0.068
Brier under sci.space:0.025
Brier under talk.politics.guns:0.045
Brier under talk.politics.mideast:0.053
Average Brier: 0.048
Accuracy: 0.902概率校准
from sklearn.calibration import CalibratedClassifierCV
name = ["Multinomial","Multinomial + Isotonic","Multinomial + Sigmoid","Complement","Complement + Isotonic","Complement + Sigmoid","Bernoulli","Bernoulli + Isotonic","Bernoulli + Sigmoid"]
models = [MultinomialNB(),CalibratedClassifierCV(MultinomialNB(), cv=2, method='isotonic'),CalibratedClassifierCV(MultinomialNB(), cv=2, method='sigmoid'),ComplementNB(),CalibratedClassifierCV(ComplementNB(), cv=2, method='isotonic'),CalibratedClassifierCV(ComplementNB(), cv=2, method='sigmoid'),BernoulliNB(),CalibratedClassifierCV(BernoulliNB(), cv=2, method='isotonic'),CalibratedClassifierCV(BernoulliNB(), cv=2, method='sigmoid')]
for name,clf in zip(name,models):clf.fit(Xtrain_,Ytrain)y_pred = clf.predict(Xtest_)proba = clf.predict_proba(Xtest_)score = clf.score(Xtest_,Ytest)print(name)Bscore = []for i in range(len(np.unique(Ytrain))):bs = BS(Ytest,proba[:,i],pos_label=i)Bscore.append(bs)print("\tBrier under {}:{:.3f}".format(train.target_names[i],bs))print("\tAverage Brier:{:.3f}".format(np.mean(Bscore)))print("\tAccuracy:{:.3f}".format(score))print("\n")结果:
Multinomial
Brier under rec.sport.hockey: 0.018
Brier under sci.space:0.033
Brier under talk.politics.guns:0.030
Brier under talk.politics.mideast:0.026
Average Brier: 0.027
Accuracy: 0.975Multinomial + Isotonic
Brier under rec.sport.hockey: 0.006
Brier under sci.space:0.012
Brier under talk.politics.guns: 0.013
Brier under talk.politics.mideast:0.009
Average Brier: 0.010
Accuracy: 0.973Multinomial + Sigmoid
Brier under rec.sport.hockey: 0.006
Brier under sci.space:0.012
Brier under talk.politics.guns:0.013
Brier under talk.politics.mideast:0.009
Average Brier:0.010
Accuracy: 0.973Complement
Brier under rec.sport.hockey:0.023
Brier under sci.space:0.039
Brier under talk.politics.guns:0.039
Brier under talk.politics.mideast:0.033
Average Brier: 0.033
Accurary.0.996Bernoulli
Brier under rec.sport.hockey: 0.068
Brier under sci.space:0.025
Brier under talk.politics.guns:0.045
Brier under talk.politics.mideast:0.053
Average Brier: 0.048
Accuracy: 0.902Bernoulli + Isotonic
Brier under rec.sport.hockey: 0.016
Brier under sci. space: 0. 014
Brier under talk.politics.guns:0.034
Brier under talk.politics.mideast:0.033
Average Brier: 0.024
Accuracy: 0.952Complement + Isotonic
Brier under rec.sport.hockey: 0.004
Brier
under sci.space:0.}e7
Brier under talk.politics.guns:0.009
Brier under talk.politics.mideast:0.006
Average Brier:0.006
Accuracy: 0.985Complement + Sigmoid
Brier under rec.sport.hockey: 0.004
Brier under
sci.space:0.009
Brier under talk.politics.guns:0.010
Brier under talk.politics.mideast:0.007
Average Brier: 0.097
Accuracy:0.986 可以观察到,多项式分布下无论如何调整,算法的效果都不如补集朴素贝叶斯来得好。因此我们在分类的时候,应该选择补集朴素贝叶斯。对于补集朴素贝叶斯来说,使用Sigmoid 进行概率校准的模型综合最优秀:准确率最高,对数损失和布里尔分数都在0.1 以下,可以说是非常理想的模型了。对于机器学习而言,朴素贝叶斯也许不是最常用的分类算法,但作为概率预测算法中唯一一个真正依赖概率来进行计算,并且简单快捷的算法,朴素贝叶斯还是常常被人们提起。并且,朴素贝叶斯在文本分类上的效果的确非常优秀。由此可见,只要我们能够提供足够的数据,合理利用高维数据进行训练,朴素贝叶斯就可以为我们提供意想不到的效果。