概述
贝叶斯属于生成模型的一种,其实现很简单,就是应用贝叶斯公式。这是一种指定先验分布,求后验的方法。
概率论课本里著名的贝叶斯公式如下
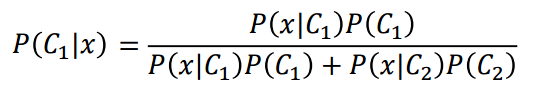
p(ci)是i类在数据集的占比,(数一下就可,易)
p(x|ci)是从数据集所有的标记为i的数据中,抽出x的概率(核心)
p(ci|x)即x属于ci的概率
通过argmax(p(ci|x))就可分类了。
所以只要解决p(x|ci)的计算,就ok了。我们假定p(x|ci)是服从多元高斯分布的。如下。其中D为feature数,Σ是(nfeature*nfeature)的协方差矩阵,μ是(nfeature)均值。当然也可以取别的分布。
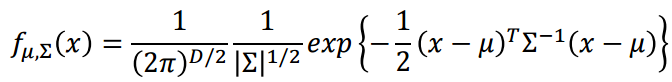
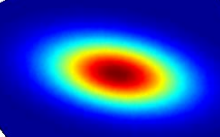
高斯分布的密度图如上所示,μ决定中心位置,Σ的对角线元素就是维度上的方差,决定了上面椭圆状密度图的长轴短轴比,Σ其余元素是协方差,决定椭圆状密度图的倾斜。
为得到每个类的Σ,μ,可以用极大似然估计来做。已经证明了估计结果就是data的mean 和 cov。故至此,我们就可算出数据集每一类的p(x|ci)函数,p(ci|x)自然也就得到了。
预测新点很简单,只需要计算对每个类的p(ci|x),最大的就是其归类。
实现
关于测试数据
使用sklearn的鸢尾花数据集
https://www.cnblogs.com/meelo/p/4272036.html
鸢尾花数据集背景:鸢尾花数据集是原则20世纪30年代的经典数据集。它是用统计进行分类的鼻祖。样本数目150,特征数目4,分别是花萼长度(cm)、花萼宽度(cm)、花瓣长度(cm)、花瓣宽度(cm)。类数为3,是花的名字,每类正好50样本。对前三维可视化如下,可见还是很好分的

code
代码如下,采用120训练集,30测试集
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
from sklearn.naive_bayes import GaussianNB
data=iris.data.copy()
target=iris.target.copy().reshape(-1,1)
np.random.seed(1)#!!!seed值的有效次数仅为一次
np.random.shuffle(data)
np.random.seed(1)
np.random.shuffle(target)train_x=data[0:120]#120*4
test_x=data[120:150]#30*4
train_tar=target[0:120].reshape(-1,1)#(120, 1)
test_tar=target[120:150].reshape(-1,1)#(30 ,1)
print(train_x[0])class Native_Bayes:def __init__(self):#这几个变量由fit函数写,predict函数取用self.P_x_c_fun=Noneself.c_num=Noneself.P_c=Nonedef fit(self,train_x,train_tar):#计算P(c)n=len(train_x)c_num=len(np.unique(train_tar))#分类数self.c_num=c_numP_c=[sum(train_tar==i)/n for i in range(c_num)]P_c=np.array(P_c).reshape(1,-1)#1*c_numself.P_c=P_c#计算P(x|c)P_x_c_fun=[]#计算分布参数,给出概率计算函数for i in range(c_num):data=train_x[(train_tar==i).flatten()]mu=data.mean(axis=0)#(nfeature,)sigma=np.cov(data.T)#(nfeature,nfeature)sigma_det=(np.linalg.det(sigma))sigma_inv=(np.linalg.inv(sigma))temp=(1/(((2*np.pi)**(c_num/2))*(sigma_det**0.5)))#小心闭包错误def g(mu,sigma,sigma_det,sigma_inv,temp):def fun(x):nonlocal temp,mu,sigma_invx=x.reshape(1,-1)res=float(temp*(np.exp(-0.5*(x-mu).dot(sigma_inv).dot((x-mu).T))))return resreturn funP_x_c_fun.append(g(mu,sigma,sigma_det,sigma_inv,temp))self.P_x_c_fun=P_x_c_funP_x_c=np.empty((n,c_num))for i in range(n):for j in range(c_num):P_x_c[i,j]=P_x_c_fun[j](train_x[i])#计算p(c|x)PP=P_x_c*P_cPP=PP/PP.sum(axis=1,keepdims=True)#注意keepdims,不然无法自动扩展c_head=np.argmax(PP,axis=1)return c_headdef predict(self,test_x):n=len(test_x)P_x_c_fun=self.P_x_c_funP_x_c=np.empty((n,self.c_num))for i in range(n):for j in range(self.c_num):P_x_c[i,j]=P_x_c_fun[j](test_x[i])PP=P_x_c*self.P_cPP=PP/PP.sum(axis=1,keepdims=True)c_head=np.argmax(PP,axis=1)return c_head
model=Native_Bayes()
res=model.fit(train_x,train_tar)
print('训练集正确率:{}/120'.format(np.sum(res==train_tar.flatten())))
res=model.predict(test_x)
print('测试集正确率:{}/30'.format(np.sum(res==test_tar.flatten())))
#对比工业实现
gnb = GaussianNB()
res=gnb.fit(train_x, train_tar.flatten()).predict(test_x)
np.sum(res==test_tar.flatten())
结果:
训练集正确率:118/120
测试集正确率:28/30
总结
踩坑:
np.random.seed(1)#!!!seed值的有效次数仅为一次
np.cov输入(nfeaturen)->(nfeaturenfeature)的cov矩阵
其他:
通常这种简单生成模型的效果不会好于逻辑回归之类的方法,但当数据集数量很少时,优势就较为明显,故在数据集比较小时可以考虑。同时可以看到生成模型的空间占用和计算速度都很不错。