TVM系列 - 图优化 - 算子融合
图优化综述
声明一下,本文所有的理解都是基于个人理解。
图优化算是一个推理框架前端比较成熟的操作了,一般来说,针对模型做图优化有两个目的(对于通用框架来说,就加速减少计算一个目的了):
- 减少Node的数量, 不管是算子融合,还是无效节点去除,共同的目的就是减少整个graph中node的数量,因为对于框架来说,从一个node到另一个node之间就意味着数据的搬运。举个例子,我们知道算子合并最经典的就是将BN层融合到Conv层,我们姑且不论融合后计算量的减少,单单是减少了将原Conv层输出数据搬运给Bn层输入这一步操作就有足够的理由让我们去实现他
- match硬件的限制,可能对于通用硬件来说还好,很多硬件对于算子的支持都非常少,有各种各样的限制,这时候就需要进行图优化来将算子转换到硬件支持的算子,常见的就是将各种算子转成卷积 😃
TVM算子融合算法介绍
首先,我们先看一种非常常见的网络子结构:

第一种如图,是我自己使用onnx生成的,可以看做是一种变形的残差模块吧,那么对于一般的框架来说,这部分可以融合吗?答案是否定的
把这部分写成公式可以表示为:

看上去似乎很简单,但是对于底层硬件来说,由于是流式处理数据,步骤就可以解析成:



这里要明确一点,每一个步骤都是把数据从ddr搬运到专用的处理器(cpu的话就是cache,寄存器这些),比如SDP上,进行运算后,再吐出到ddr上的。所以,如果要一次性将这三个步骤在一个cycle中全部算完再吐出的话,首先要存张量x, 要存张量a, b,要存中间量或者说最终输出量y,而这个y你还不能复用x的空间,因为等下还要加x,这对专用硬件的要求是挺高的,同时对于框架也要求有所提升。
所以一般的框架对于算子融合其实能够做的非常有限,总不过就是卷积和BN融合,再把relu算上这些基础的做法,以Tengine为例:

我们看到Tengine拢共做的图优化也不过就5种,大家有兴趣可以去看下。
Tengine/Convert_Tool
但是TVM在算子融合上显然要做的更多,当然这主要得益于TVM强大的code generator,也就是编译器后端。
支配树
TVM整体的算子融合是基于支配树来做的。那么什么是支配树呢?
简单来说,支配树就是由各个点的支配点构成的树,那么什么又是支配点呢?支配点在神经网络结构上可以理解为:所有能够到达当前节点的路径的公共祖先点(LCA)。
以图为例:

上面是我截取的resnet的一部分,那么我们从下往上看,以Node37为例,能够到达他的一共有两条路径,38-39, 40-71,那么这两条路径的LCA是谁呢,就是最后一个Node,所以它就是Node37的支配点。同理,图中所有点的支配点所构成的树就是支配树。
支配树的作用
TVM的算子融合策略就是检查每个Node到其支配点的这些Node是否符合融合条件,如果符合就对其进行融合。举例来说,比如上图Node55的支配点就是他下面的BN层,就检查它俩能不能融合,一看可以融合,就用新的Func去替代原来的这俩算子。同理,检查Node37到他的支配点之间所有路径是否符合融合规则。
那么,为什么要基于支配树去做呢?试想一下,如果不按照上述规则去做,你将Node37与其中一条路径合并了,那么另外一条咋办?
融合的基本规则就是融合掉的Node节点不会对剩下的节点产生影响。
支配树的生成
我们都知道,神经网络结构可以看做是一个有向无环图(DAG),根据这个有向无环图我们可以生成对应的支配树。
具体步骤如下:
- 首先根据DAG进行深度优先遍历,生成DFS树,需要注意的是,这个DFS树是要倒序的,也就是最后一个节点是节点0,然后依次深度递增,如下图:

除了单纯的记录每个Node的深度之外,我们还需要为每个节点保存与他相连的边,注意这个边是与的父节点(也就是真正网络中他的输出节点,倒序就变成了他的父节点了)组成的

之所以这里需要保存这个边和他对应的index,就是为了后面找LCA用的 - 根据DFS树及对应的边(link)生成DOM树
def LeastCommonAncestor(self, edges, edge_pattern, index):if len(edges) <= index:return Nonelink_head = edges[index]def get_node(father_node):oindex = father_node.indexreturn self.tree_nodes[oindex]parent = get_node(link_head.value)edge_pattern = link_head.value.patternindex = index + 1for i in range(index, len(edges)):link = edges[index]parent = self.LeastCommonAncestorMulEdges(parent, get_node(link.value), edge_pattern);edge_pattern = self.CombinePattern(edge_pattern, link.value.pattern);return parent
说白了,生成支配树就是找每个节点的LCA的过程,看上面代码,是我用python按照TVM的思路重写的,首先看与当前Node有几条边相连,如果只有一条边(这里的边,就是前面我们存的每个Node的link),那么他的支配点就是他的父节点,这点很容易理解。
但是如果len(edges)大于1,那么就会走到for循环里,调用函数self.LeastCommonAncestorMulEdges
def LeastCommonAncestorMulEdges(self, lhs, rhs, edge_pattern):while (lhs != rhs):if (lhs == None):return nullptr;if (rhs == None):return nullptr;if (lhs.depth < rhs.depth):edge_pattern = self.CombinePattern(edge_pattern, rhs.pattern)rhs = rhs.parent;elif (rhs.depth < lhs.depth):edge_pattern = self.CombinePattern(edge_pattern, lhs.pattern)lhs = lhs.parentelse:edge_pattern = self.CombinePattern(edge_pattern, lhs.pattern)edge_pattern = self.CombinePattern(edge_pattern, rhs.pattern)lhs = lhs.parent;rhs = rhs.parent;return lhs;
如果多条边,就要找这些边的LCA了,所以while循环唯一的break条件就是lhs == rhs。这里面的depth就是DFS树中的index。

- TVM是使用group这个概念来描述几个Node能否融合的,如果一个算子不能和任何其他算子融合,那么这个group就只有他自己,同样如果几个算子能够融合,他们几个就是一个group。当然,TVM对于group的描述并不是这么简单,他是通过group中每个节点的master_ref来标识他的融合目标点的。
首先,初始化出一个和dfs同样的树,你也可以理解成一个list,由于开始我们不知道当前Node能不能够和支配点融合,所以init阶段,要将groups中每个节点的master_ref设为自己。
开始融合
TVM将所有的算子进行了分类,conv和pooling一般是不能够当做被融合对象的,也就是他们不能够融合到别的算子上去,所以就是OutEwiseFusable,add就是broadcast等等。
ONNX_OPPATTERN = {"Conv": OpPatternKind.kOutEWiseFusable,"MaxPool": OpPatternKind.kOutEWiseFusable,"Relu": OpPatternKind.kElemWise,"BatchNormalization": OpPatternKind.kBroadcast,"Add": OpPatternKind.kBroadcast,"sqrt": OpPatternKind.kElemWise,"divide": OpPatternKind.kBroadcast,"Sqrt": OpPatternKind.kBroadcast,"Mul": OpPatternKind.kBroadcast,"expand_dims": OpPatternKind.kBroadcast,"negative": OpPatternKind.kElemWise,"Constant": OpPatternKind.kOpaque,
}
大致算子的分类就是上述几种。笔者之前做算子融合都是非常具体的判断,例如if current.op_type == “add” && next.op_type == "mul"这样作融合判断的,那么你遇到一种就支持一种,后面代码会非常臃肿,而且如果图优化的顺序有错误的话,会发生各种错误的。受益于TVM强大的后端,他这种把算子进行分类后再根据类别去做融合真的让人喜欢!
融合阶段就是遍历每个Node到他支配点的所有路径是否符合融合规则了。目前TVM支持的算子融合有三种,代码里也是通过for循环phase0,1,2来循环判断的。

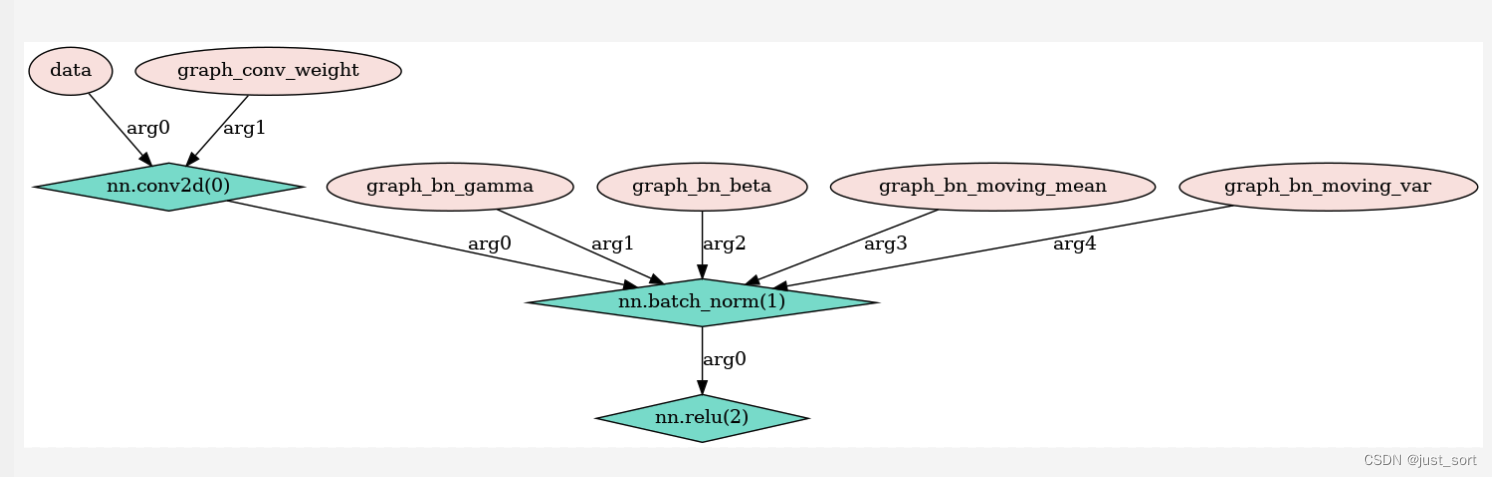
我们单纯看第一种吧,这种最具有代表性。一眼看上去好像就是conv+bn+relu融合,但是要注意一下,在Fuse Rule哪里,右边那条线可以从别的地方来,当然也可以从conv来,就是res残差模块。
还是回到我自己生成的onnx模型,

TVM认为蓝色框这种结构是符合第一种融和规则的,可以进行融合。我们看下,TVM的输出

%4,%5,%6及最后一步就是上图蓝色框那里,可以非常清晰的看到他们的group号都是一样的。
TVM算子融合总结
对于其他框架来说,如果没有根据融合后的Func去生成机器码的编译器后端,TVM算子融合是不能用的,也就是基本不能用哈哈。
然后如果需要TVM算子融合我自己写的python版的话,可以联系我,要比c++代码看起来结构和语法都友好很多
TVM算子融合python版代码
算子融合python代码


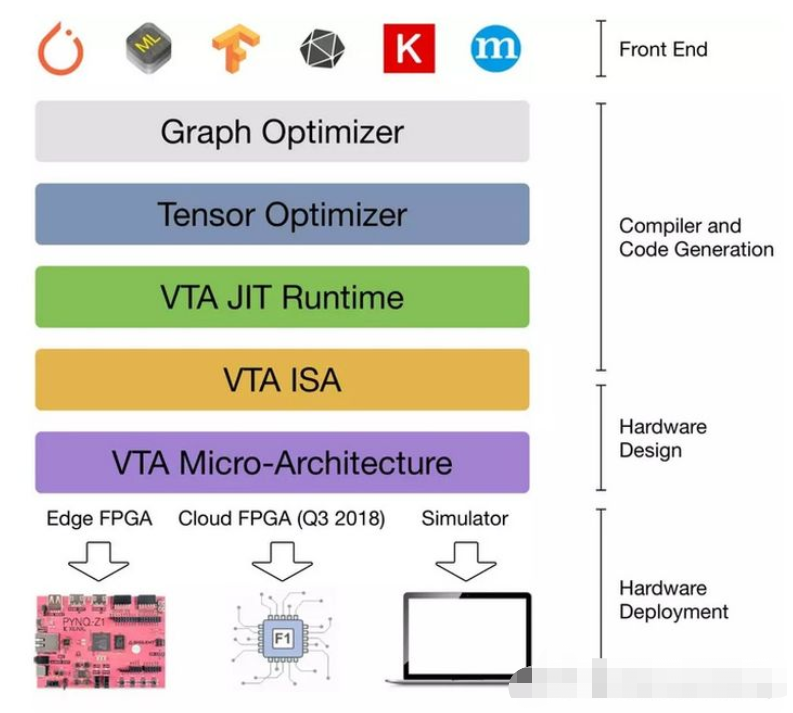


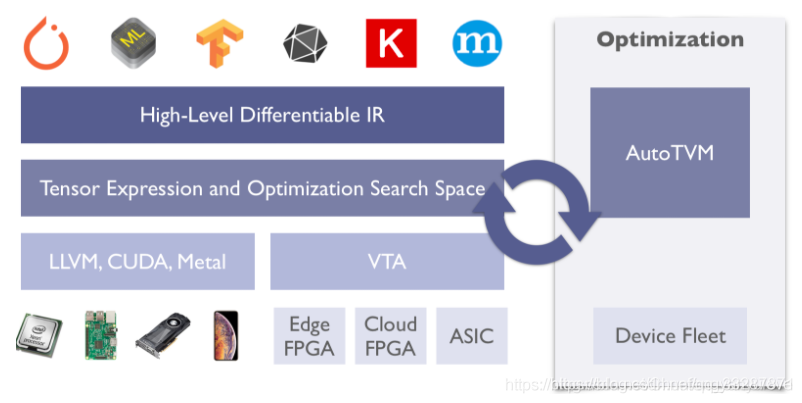




![TVM[2] —— TVM简介和发展](https://img-blog.csdnimg.cn/02bb2422b78142aba58da82e9fe1b568.png#pic_center)