文章同步更新在公众号 AIPlayer,欢迎扫码关注,共同进步

目录
一、TVM的工作流程
1、整体流程
2、关键数据结构
3、Transformations
4、搜索空间和基于机器学习的转换
5、目标代码转化
二、逻辑架构组件
三、运行TVM实例
1、交叉编译runtime
2、编译模型
3、运行模型
四、总结
一、TVM的工作流程
TVM主要由两个部分组成:
(1)TVM编译器:负责编译和优化模型
(2)TVM runtime:提供目标设备上运行模型的API
1、整体流程
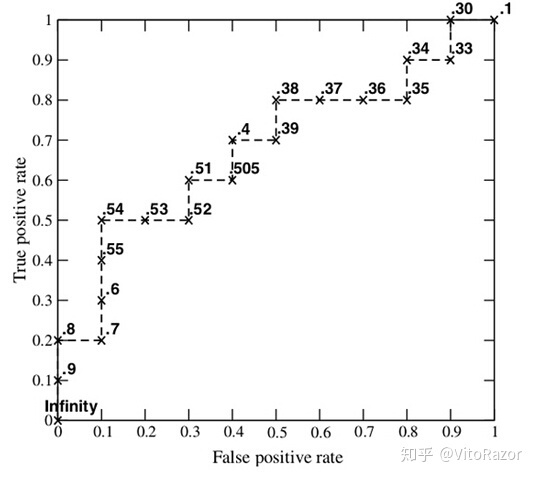
如图所示,TVM的工作流程包括4个主要部分:
-
前端导入(Import):前端部件将不同神经网络框架所训练得到的模型文件转化为IRModule,IRModule是TVM核心的数据结构之一,它包含了可以表述模型的函数集合。
-
编译转化(Transformation):编译器对IRModule通过各种Relay Passes的优化规则进行优化,比如对模型进行量化等。
-
目标代码转换(Target Translation):既然IRModule是一个函数集合,那编译器就可以将IRModule交叉编译为目标设备可运行的格式,并提供了导出,加载和执行的API给目标设备调用。
-
运行(Runtime Execution):用户将交叉编译得到的Module加载到设备上并执行其中的函数集合。
2、关键数据结构
IRModule (intermediate representation module)是贯穿整个TVM的数据结构,重要性不言而喻。它是一系列Function的集合,用于表述一个神经网络模型,目前TVM支持两种主要的变体函数:
-
relay::Function 是高层级的函数编程表示,一个relay.Function通常对应一个端到端的模型。可以将它理解为一个支持控制流、递归和复杂数据结构的计算图。
-
tir::PrimFunc 是低层级的函数编程表示,它包括循环嵌套、多维加载与存储,线程处理以及向量和张量操作指令。它通常用以定义一个算子的操作,对应一个模型中的某一层。
在整个编译过程中,一个relay function可能会被优化为多个tir::PrimFunc。
3、Transformations
transformation的作用有两个:
(1)优化(optimization):将程序转换为等效的、或者更优化的版本;
(2)底层表示(lowering):将程序转换为更接近目标设备的低层级表示。
relay/transform 包含一组优化模型的passes。优化包括constant folding和dead-code消除,以及针对张量计算的优化,如layout转换和scaling factor folding。
在relay优化的pipeline的最后,会运行一个 FuseOps的pass,将一个完整的Function(对应一个端到端的模型如 MobileNet)分解为多个子Funcions(例如 conv2d-relu)段。这样做的好处是将问题分成了两个子问题:
-
编译和优化可以针对每个子Function。TVM使用低层级的 tir 来编译和优化每个子功能。对于特定目标设备,也可以直接使用外部代码生成器进行目标代码转换。
-
整体运行时需要调用所有的子Function。TVM支持几种运行方式,所有运行模式都封装在一个统一的 runtime.Module 接口中:
-
对于形状已知且没有控制流的简单模型,我们可以降级为将执行结构存储在图中的图执行器;
-
支持用于动态执行的虚拟机后端;
-
后续计划支持提前编译,将高层级的运行结构编译为可运行的原始functions。
-
tir/transform 包含 TIR 层级functions的转换passes。例如,将multi-dimensional access flatten到一维访问,将内在函数扩展为特定于目标的函数,以及修饰函数入口以满足运行时调用约束。除此之外,也有优化passes,如access index简化和dead-code消除。
4、搜索空间和基于机器学习的转换
前面描述的转换都是基于规则和确定的,而TVM的设计目标之一是支持对于不同的硬件平台都可以进行高性能的代码优化。因此,需要对尽可能多的优化进行选择,每个优化又需要选择最优的参数,从这个角度来看,这个的工作量无疑是巨大的。TVM采用了基于空间搜索和机器学习的方法来解决这个优化选择与调参的问题。
顾名思义,空间搜索需要在特定的空间,所以首先需要定义一系列的转换操作,比如循环转换、内联、矢量化等。这些操作称为调度原语(scheduling primitives)。调度原语的集合定义了可以对程序进行优化的搜索空间,然后TVM搜索不同的调度顺序以挑选最佳调度组合。这个搜索过程通常由机器学习算法完成,TVM使用的是xgboost算法。在搜索完成后,记录下每个算子最优的调度顺序,然后编译器就可以将此调度序列应用到程序中。TVM使用基于搜索的优化方法来处理初始 tir function生成问题。这部分模块称为 AutoTVM(auto_scheduler)。
5、目标代码转化
目标代码转换阶段主要是将 IRModule 转换为可以相应的目标设备上运行的格式:
-
对于 x86 和 ARM 等后端,使用 LLVM IRBuilder 来构建 LLVM IR;
-
支持生成例如 CUDA C 和 OpenCL等源码级的代码;
-
支持通过外部代码生成器将Relay function(子图)直接转换为特定目标代码。
代码生成阶段需要尽可能地轻量化,所以绝大多数的转换和降层级都应该放在目标代码转换之前执行。
二、逻辑架构组件
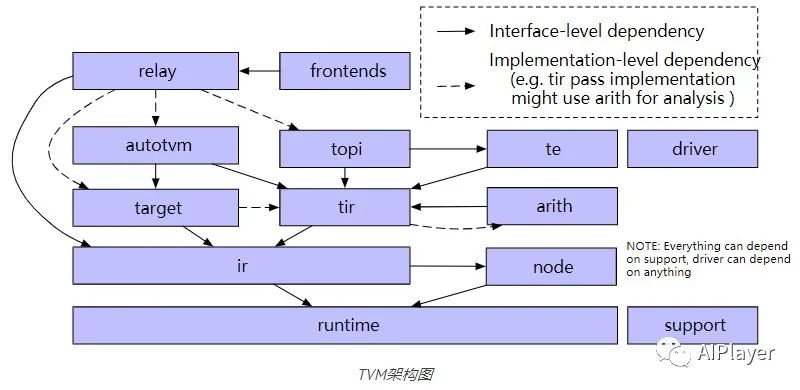
上图显示了TVM中的主要逻辑组件:
-
tvm/support
包含tvm最常用的实用工具函数,例如通用的 arena 分配器、套接字和日志记录等。
-
tvm/runtime
runtime作为tvm的基础组件,提供了加载和执行编译的机制,它定义了一组标准的C API与前端高级语言如Python和Rust进行交互。在runtime中,runtime::Object是主要的数据结构之一,它是一个带有类型索引的引用计数基类,用于支持运行时类型检查和向下类型转换。通过它可以向runtime引入新的数据结构,如 Array、Map 和新的 IR 数据结构。
编译器本身也大量使用了 TVM 的runtime机制。所有 IR 数据结构都是runtime::Object 的子类,因此,它们可以直接通过 Python 前端进行操作,tvm使用 PackedFunc 机制向前端公开各种 API。
runtime/rpc实现了对 PackedFunc 的 RPC 支持,由此可以将交叉编译的库发送到远程设备并测试性能。因为rpc架构支持从各种远程硬件后端收集数据,所以它是基于机器学习优化方法的基础。
-
tvm/node
node 模块在runtime::Object之上为 IR 数据结构添加了附加功能。主要功能包括反射、序列化、结构等价和散列。还可以将任意 IR 节点序列化为 JSON 格式,然后将它们加载回来。保存/存储和检查 IR 节点的能力为使编译器更易于访问奠定了基础。
-
tvm/ir
在tvm/ir文件夹中包含跨所有IR功能变异体的统一的数据结构和接口。tvm/ir中的组件由tvm/relay和tvm/tir共享,包括IRModule、Type、PassContext 和 Pass、OP。
-
tvm/target
target模块包含将 IRModule 转换为目标 runtime.Module 的所有代码生成器。它还提供了一个通用的Target类来描述目标。通过查询target中的属性信息和注册到每个target id(cuda, opencl)的内置信息,可以根据target定制编译流水线。
-
tvm/tir
tir 包含低层级程序表示的定义,使用tir::PrimFunc来表示可以通过 tir 通道转换的函数。除了 IR 数据结构之外,tir 模块还通过公共 Op 注册表定义了一组内置函数及属性,以及tir/transform 中的转换passes。
-
tvm/arith
该模块与 tir 密切相关。低层级代码生成中的关键问题之一是对索引算术属性的分析。arith 模块提供了一组(主要是整数)分析工具。tir 通过可以使用这些分析来简化和优化代码。
-
tvm/te
te 代表“张量表达式”,通过编写张量表达式可以快速构建tir::PrimFunc变体。te/schedule提供了一组调度原语来控制正在生成的函数。
-
tvm/topi
虽然可以为每个用例直接通过 TIR 或张量表达式 (TE) 构造运算符,但这样做很乏味。topi(张量运算符清单)提供了一组由 numpy 定义并在常见深度学习工作负载中找到的预定义运算符(在 TE 或 TIR 中)。我们还提供了一组通用计划模板,以获得跨不同目标平台的高性能实现。
-
tvm/relay
relay 是用于表示完整模型的高级功能 IR。在relay.transform中定义了各种优化。relay 编译器定义了多种优化策略,每种策略都旨在支持特定的优化方式。
-
tvm/autotvm
AutoTVM和AutoScheduler是自动搜索优化所必须的两个组件。主要包括:cost models和特征提取;用于存储运行cost models性能结果的格式以及一组变换搜索策略。
三、运行TVM实例
1、交叉编译runtime
想要在目标设备上运行模型的前提是交叉编译模型和runtime库。以Raspberry Pi为例,首先需要在主机安装Raspberry Pi的编译工具链:
sudo apt-get update
sudo apt-get install gcc-aarch64-linux-gnu g++-aarch64-linux-gnu
sudo apt-get install gcc-multilib-arm-linux-gnueabihf g++-multilib-arm-linux-gnueabihf然后交叉编译TVM runtime库:
cmake .. \-DCMAKE_SYSTEM_NAME=Linux \-DCMAKE_SYSTEM_VERSION=1 \-DCMAKE_C_COMPILER=/usr/bin/aarch64-linux-gnu-gcc \-DCMAKE_CXX_COMPILER=/usr/bin/aarch64-linux-gnu-g++ \-DCMAKE_FIND_ROOT_PATH=/usr/aarch64-linux-gnu \-DCMAKE_FIND_ROOT_PATH_MODE_PROGRAM=NEVER \-DCMAKE_FIND_ROOT_PATH_MODE_LIBRARY=ONLY \-DMACHINE_NAME=aarch64-linux-gnu
make -j2 runtime编译完成后使用file命令查看编译出来的runtime库是否OK:

2、编译模型
在主机上构造一个简单的kernel,并在主机上编译,示例代码如下:
import numpy as np
import tvm
from tvm import te
from tvm import rpc
from tvm.contrib import utils
# 构造计算核
n = tvm.runtime.convert(1024)
A = te.placeholder((n,), name="A")
B = te.compute((n,), lambda i: A[i] + 1.0, name="B")
s = te.create_schedule(B.op)
# 编译并保存结果:local_demo为True表示编译target为主机端运行,否则为raspbarry pi
local_demo = True
if local_demo:target = "llvm"
else:target = "llvm -mtriple=armv7l-linux-gnueabihf"
func = tvm.build(s, [A, B], target=target, name="add_one") # 为目标设备生成代码
print(func)
path = "./tvm_test_lib.tar"
func.export_library(path)运行代码后会得到tvm_test_lib.tar的编译结果,func的打印输出为:
Module(llvm, 56334d7e8738)它是一个 tvm.runtime.PackedFunc 类型,TVM使用Function开作为前后端的黏合,一个编译后的module返回Function,TVM后端同样也以Functions的方式注册和暴露API。
3、运行模型
将它用rpc的方式运行在设备上,需要将编译的lib上传到设备,然后使用设备端的编译器重新链接之后,func就是一个设备端的模型对象了。
if local_demo:remote = rpc.LocalSession()
else:host = "192.168.1.111"port = 9090remote = rpc.connect(host, port)
remote.upload(path)
func = remote.load_module("tvm_test_lib.tar")
print(func)
dev = remote.cpu()
a = tvm.nd.array(np.random.uniform(size=1024).astype(A.dtype), dev)
b = tvm.nd.array(np.zeros(1024, dtype=A.dtype), dev)
func(a, b)
np.testing.assert_equal(b.numpy(), a.numpy() + 1)
time_f = func.time_evaluator(func.entry_name, dev, number=10)
cost = time_f(a, b).mean
print("%g secs/op" % cost)此时的func打印输出是:
Module(rpc, 56334d6d7148)四、总结
本文介绍了TVM的工作流程和内部的逻辑框架组件,通过运行TVM的一个实例了解和熟悉TVM的Python API使用。
往期推荐
【TVM系列一】开发环境搭建



![TVM[2] —— TVM简介和发展](https://img-blog.csdnimg.cn/02bb2422b78142aba58da82e9fe1b568.png#pic_center)