TVM与LLVM的架构非常相似。TVM针对不同的深度学习框架和硬件平台,实现了统一的软件栈,以尽可能高效的方式,将不同框架下的深度学习模型部署到硬件平台上。
如果从编译器的视角来看待如何解决这个问题,各种框架写的网络可以根据特定的规则转化成某种统一的表示形式,在统一表示的基础上进行一些可重用的图优化,之后再用不同的后端来生成对应不同设备的代码,这就是目前各家都在尝试的设计思路了。
TensorFlow 的 XLA 会把高级代码抽象成 XLA HLO 的表示,做目标无关优化之后再用对应后端来生成更深一层的代码。
NVIDIA 的 TensorRT 的优化策略也是在图转化之后的统一表示上做,例如根据设定好的规则来做一些相邻计算单元的合并(Kernel Fusion)等等,但TensorRT最重要的Kernel部分的实现未开源。
TVM软件栈

工作流程
- 从已有的深度学习框架中获取一个模型并将此模型转换为计算图表示(深度学习框架的前端主要提供计算图表示以及自动梯度的功能);
- 图中 Section 3 使用一些方法优化当前的计算图得到优化后的计算图;
- 图中 Section 4 针对计算图中每个融合的算子生成有效的代码,生成过程中结合了张量表达式以及硬件优化原语,在算子级进行优化;
- 由于优化空间非常大,图中 Section 5 基于机器学习技术实现自动优化;
- 系统打包生成的代码到部署模块中。
Optimizing Computational Graphs(计算图级优化)

Operator Fusion
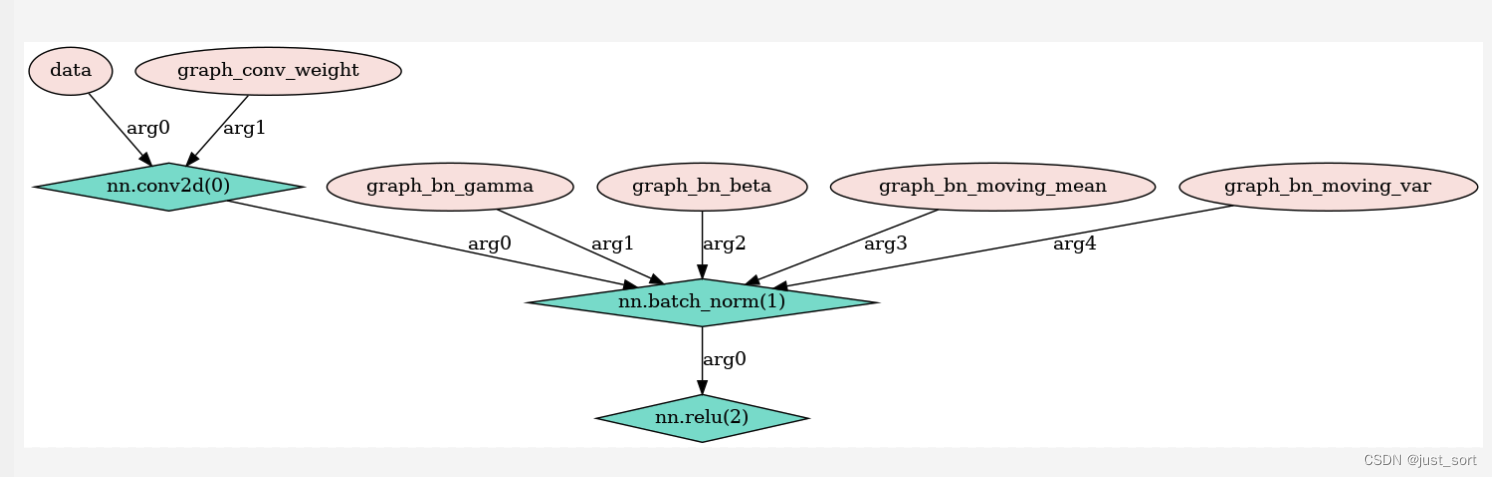
Operator Fusion,可以将多个算子合并为一个kernel,以此节省存储中间结果的空间。例如,卷积、BN以及激活函数算子之间的融合,本质上是将三个算子的数学表达式代入并化简。
卷积: y c o n v = w ∗ x + b y_{conv} = w * x + b yconv=w∗x+b
BN: y b n = γ ∗ ( y c o n v − m e a n ) / v a r + β y_{bn} = \gamma * (y_{conv} - mean) / \sqrt{var} + \beta ybn=γ∗(yconv−mean)/var+β
代入表达式,融合后的新卷积:
w ′ = γ / v a r ∗ w w^{'} = \gamma / \sqrt{var} * w w′=γ/var∗w
b ′ = γ / v a r ∗ ( b − m e a n ) + β b^{'} = \gamma / \sqrt{var} * (b - mean) + \beta b′=γ/var∗(b−mean)+β
新的卷积就可以完成BN的工作。
Data Layout Transformation
不同的硬件设备可能具有截然不同的内存层次结构,因此,融合算子与优化数据布局的策略对于优化内存访问至关重要。
在目标硬件平台中,给定内存层次结构的约束,为每个操作符指定首选的数据布局,若数据布局不匹配,改变计算图中张量的数据布局方式以适应目标硬件设备并提升执行效率。
常见的速数据布局方式有行式存储和列式存储,实际场景下,会使用一个更加复杂的数据布局,以达到深度学习加速器的数据布局要求,更好地在目标硬件平台上执行。

数据布局对性能影响巨大。
在 NCHW 的布局下,利用 SIMD 加速 3x3 的 depth-wise 卷积。首先,读取数据时,需要一次性读取四个 float 作为第一行的数据,后两行的读取也是相似的;此时,读取出的三行数据已经足够计算两列输出,即,可以复用部分数据;而后,为了提高数据复用,会再读取出第四行数据,一次计算两行两列,即,可以引入循环展开;然而,残留的 5~25 和 21~25 亮度眼边界无法利用 SIMD 计算,只能逐一循环读写完成计算;按照这样的方式,就可以相应完成后几个通道的计算。
但是, NCHW 布局下,无法充分利用 SIMD 进行加速,同时,实现优化分支越多,占用包大小也就越多。

在 NC/4HW4 布局下,利用 SIMD 加速的情况。这里的 “C/4” 指的是按照 4 个通道对齐的方式重排数据。重排所有输入和权重数据后,每次 SIMD 读写都天然是 4 个通道的输入数据和 4 个通道的权重数据。这样,不论 kernel、stride、dilation 怎么变化,我们都可以简单地使用 for 循环和 SIMD 的一套通用优化完成卷积计算。既不会有边缘数据无法加速的问题,也不会对包大小造成影响。
Generating Tensor Operations(算子级优化)
Tensor Expression and Schedule Space
Tensor Expression 支持常见的算术运算和数学运算,并涵盖了常见的算子。该语言没有指定循环结构和许多其他执行细节,并且它提供了为各种后端添加硬件感知优化的灵活性。根据解耦计算和调度的原则,用调度表示从张量表达式到底层代码的映射。
Tensor Expression的最初的想法来源于 Halide,核心在于把代码的计算和调度分开。
为了在硬件后端实现高性能,必须支持足够的调度原语,以涵盖在不同硬件后端上的各种优化。
| 用于不同硬件后端的调度原语 | CPU调度 | GPU调度 | 加速器调度 |
|---|---|---|---|
| [Halide] Loop Transformations | Yes | Yes | Yes |
| [Halide] Thread Binding | Yes | Yes | Yes |
| [Halide] Compute Locality | Yes | Yes | Yes |
| [TVM] Special Memory Scope | No | Yes | Yes |
| [TVM] Tensorization | Yes | Yes | Yes |
| [TVM] Latency Hiding | No | No | Yes |
例如一段最原始的 TVM 代码:
C = tvm.compute((n,), lambda i: A[i] + B[i])
s = tvm.create_schedule(C.op)
生成得到的 C 代码是:
for (int i = 0; i < n; ++i)
{C[i] = A[i] + B[i];
}
加上额外的调度控制:
C = tvm.compute((n,), lambda i: A[i] + B[i])
s = tvm.create_schedule(C.op)
xo, xi = s[C].split(s[C].axis[0], factor=32)
再生成的代码就变成了:
for (int xo = 0; xo < ceil(n / 32); ++xo)
{for (int xi = 0; xi < 32; ++xi){int i = xo * 32 + xi;if (i < n){C[i] = A[i] + B[i];}}
}
甚至于还可以支持绑定中间的 xo 和 xi 到特定的变量上:
C = tvm.compute((n,), lambda i: A[i] + B[i])
s = tvm.create_schedule(C.op)
xo, xi = s[C].split(s[C].axis[0], factor=32)
s[C].recorder(xi, xo)
s[C].bind(xo, tvm.thread_axis(“blockIdx.x”)
s[C].bind(xi, tvm.thread_axis(“threadIdx.x”)
这样出来的代码就可以用在 CUDA kernel 里面了:
int i = threadIdx.x * 32 + blockIdx.x;
if (i < n)
{C[i] = A[i] + B[i];
}
Nested Parallelism with Cooperation
现代 GPU 与专用加速器的内存可被多个计算核心共享,传统的无共享嵌套并行模式已不再是最优方法。为优化内核,在共享内存负载上的线程合作很有必要。
将Memory Scopes的概念引入调度空间,以便将计算阶段标记为 Shared。如果没有显式的Memory Scopes,自动范围推断将把计算阶段标记为 thread-local。
Tensorization
最新的硬件带来了超越向量运算的新指令集,如 TPU 中的 GEMM 算子和英伟达 Volta 架构中的 Tensor Core。因此在调度过程中,我们必须将计算分解为张量算术内联函数,而非标量或向量代码。
把矩阵-向量运算变成矩阵-矩阵运算,4x8 的矩阵乘上 8x1 的向量变成两个 4x4 和 4x1 的矩阵乘积。
Explicit Memory Latency Hiding
尽管在现代 CPU 与 GPU 上,同时拥有多线程和自动缓存管理的传统架构隐藏了延迟问题,但专用的加速器设计通常是采用精简控制流和将复杂性分配到编译器堆栈上面的方案。所以设计涉及到隐藏内存访问延迟的调度器时必须要非常仔细。
Automating Optimization
给定丰富的调度原语集,剩下的问题是为模型的每一层找到最优的算子实现。
系统需要选择调度优化,比如修改循环顺序或优化内存层次结构,以及特定调度的参数,比如平铺大小和循环展开因子。这些选择的组合为每个硬件后端都创建了一个很大的算子实现的搜索空间。
- Schedule Space Specification
- ML-Based Cost Model
- Schedule Exploration
TVM论文地址

![TVM[2] —— TVM简介和发展](https://img-blog.csdnimg.cn/02bb2422b78142aba58da82e9fe1b568.png#pic_center)