如有图像或公式显示错误,可以访问我的个人博客:https://www.wanglichun.tech/2019/11/15/tvm/
笔者也是最近偶然的机会才开始接触TVM,使用过后发现,经过auto-tuning后的TVM模型在速度是竟然超过了TensorRT,并且笔者使用的是MXNet框架,TVM对MXNet绝对的友好,对于Pytorch等模型,可以使用ONNX,操作也一样简单,使用起来基本类似一键操作,本篇文章是笔者对TVM的简单整理,也算是对TVM的入门。
当然如何想详细了解TVM,还请阅读TVM的主页以及论文,文章最后有链接。
TVM简介
随着深度学习的发展,深度学习的能力可以说是越来越强大,识别率节节攀升,甚至超过人类。于此同时,深度学习框架也变得越来越多,目前比较主流的深度学习框架包括:Pytorch、TensorFlow、Mxnet、Caffe、Keras等。
一般进行深度学习任务包括两部分,一是训练出精度比较高的模型,然后将其部署到对应的目标机器上。
针对第一部分,自然我们可以使用各种深度学习框架,通过修改网络调参等,训练出精度比较满意的模型,一般情况,在训练深度学习模型的时候,都会使用到GPU。
针对部署,这里的目标机包括服务器、手机、其他硬件设备等等。部署的模型自然是希望越快越好,所以硬件厂商一般会针对自己的硬件设备进行一定的优化,以使模型达到更高的效率,比如Nvidia的TensorRT。但是框架这么多,硬件平台这么多,并不是所有的硬件平台都像Nvidia提供了硬件加速库,而即使做了加速,要适应所有的深度学习训练框架,也是一件比较难的事情。
其实介绍了这么多总结起来就是两个问题:
- 在进行模型部署的时候,我们是否可以对不同框架训练的模型均生成统一的模型,解决硬件平台需要适配所有框架的问题?
- 在进行模型部署的时候,我们是否可以自动化的针对不同的硬件进行优化,进而得到高效的模型?
TVM实际上就是在解决这两个问题,并且解决的还不错。
那么TVM是什么?
TVM is an open deep learning compiler stack for CPUs, GPUs, and specialized accelerators. It aims to close the gap between the productivity-focused deep learning frameworks, and the performance- or efficiency-oriented hardware backends.
TVM是一个开源的可面向多种硬件设备的深度学习编译器,它的作用在于打通模型框架、模型表现以及硬件设备的鸿沟,进而得到表现最好的可部署的深度学习模型,实现端到端的深度学习模型部署。
TVM做了哪些工作
针对第一个问题:
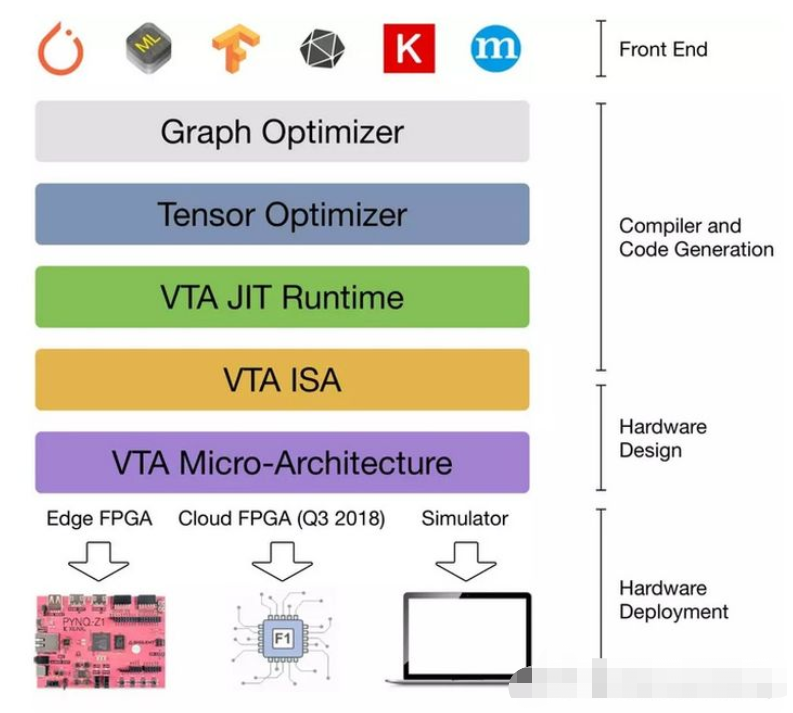
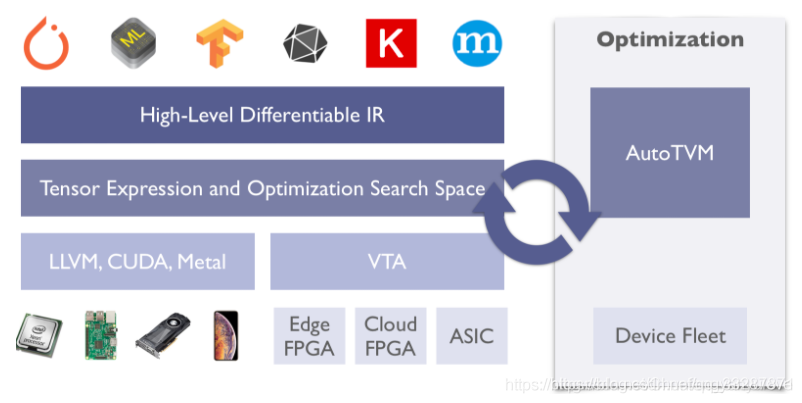
TVM将不同前端(深度学习框架)训练的模型,转换为统一的中间语言表示,如果想详细理解这里,可以了解一下NNVM,NNVM是陈天奇团队开发的可以针对不同框架进行深度学习编译的框架,在TVM中,陈天奇团队进一步优化,实现了NNVM的第二代Relay。Relay是TVM中实现的一种高级IR,可以简单理解为另一种计算图表示。其在TVM所处的位置如下图所示,并且该部分实现了比如运算融合等操作,可以提升一部分模型效率。

针对第二个问题:
TVM设计了对不同的硬件后端,自动优化tensor操作,以达到加速的目的。该部分的实现,TVM使用机器学习的方法进行计算空间的最优化搜索,通过在目标硬件上跑大量trial,来获得该硬件上相关运算(例如卷积)的最优实现。详细介绍可以参考TVM主页以及论文。

TVM 安装
不同环境的安装方法可以参考tvm的官网:https://docs.tvm.ai/install/index.html
对于安装环境,我还是强烈推荐docker的,会少很多坑。
TVM 使用
TVM的使用可以阅读一下tvm提供的tutorials:https://docs.tvm.ai/tutorials/
主要推荐两部分:
- compile deep learning models
- auto tuning
其实简单的使用主要就是这两块内容,如果不想细研究其代码,可以将其当成一个工具使用,通过compile deep learning models,无论你使用什么样的框架,都可以生成统一的模型,一般会生成3个东西如下:

这里一般会做一些层的融合等操作,速度会有一定的提升的,但是不是特别大。这时如果你需要进一步提速可以试试auto tuning,这部分可以参考tutorials以及下面的例子代码,auto-tune的时间一般比较长,但是效果还是比较显著的,本地测试,resnet在nvidia 1080ti上可以提高3倍左右。
Demo代码
TVM的原理很复杂但是使用起来还是比较方便的,下面是使用MXNet进行TVM转换的demo。
代码一:生成TVM模型。
import tvm
from tvm import relay
from tvm.relay import testing
from tvm.contrib import graph_runtime
import mxnet as mx
from tvm.contrib.download import download_testdata
import numpy as np
import time## load mxnet model
prefix = '/Models/resnetv1d-101'
epoch = 13
mx_sym, arg_params, aux_params = mx.model.load_checkpoint(prefix, epoch)
shape_dict = {'data': (1, 3, 224, 224)}relay_func, relay_params = relay.frontend.from_mxnet(mx_sym, shape_dict,arg_params=arg_params, aux_params=aux_params)target = 'cuda'
with relay.build_config(opt_level=3):graph, lib, params = relay.build(relay_func, target, params=relay_params)
# run forwardfrom PIL import Image
image = Image.open('test.jpg').resize((224, 224))
def transform_image(im):im = np.array(im).astype(np.float32)im = np.transpose(im, [2, 0, 1])im = im[np.newaxis, :]return im
x = transform_image(image)
# let's go
ctx = tvm.gpu(0)
dtype = 'float32'm = graph_runtime.create(graph, lib, ctx)
## set input data
m.set_input('data', tvm.nd.array(x.astype(dtype)))
## set input params
m.set_input(**params)
t1 = time.time()
m.run()
t2 = time.time()
# get output
outputs = m.get_output(0)
top1 = np.argmax(outputs.asnumpy()[0])
print(outputs, str(t2-t1))### evaluate inference timeftimer = m.module.time_evaluator('run', ctx, number=1, repeat=100)
prof_res = np.array(ftimer().results) * 1000
print('time cost : mean:{}'.format(np.mean(prof_res)))# save modelpath_lib = '/Outputs/tvm/deploy_resnet101_v1d_lib.tar'
lib.export_library(path_lib)with open('/Outputs/tvm/deploy_resnet101_v1d_graph.json', 'w') as f:f.write(graph)
with open('/Outputs/tvm/deploy_params', 'wb') as f:f.write(relay.save_param_dict(params))# load model backloaded_json = open('/Outputs/tvm/deploy_resnet101_v1d_graph.json').read()
loaded_lib = tvm.module.load(path_lib)
loaded_params = bytearray(open('/Outputs/tvm/deploy_params', 'rb').read())
module = graph_runtime.create(loaded_json, loaded_lib, ctx)
module.load_params(loaded_params)tvm_data = tvm.nd.array(x.astype(dtype))
module.run(data=tvm_data)
outputs = module.get_output(0)
print(outputs)代码二:auto-tuning
这部分耗时较长,一个resnet101模型,在1080ti上面可能要tune1到2天的时间。
import osimport numpy as np
import mxnet as mx
import tvm
from tvm import autotvm
from tvm import relay
import tvm.relay.testing
from tvm.autotvm.tuner import XGBTuner, GATuner, RandomTuner, GridSearchTuner
from tvm.contrib.util import tempdir
import tvm.contrib.graph_runtime as runtime
import argparsedef get_network(dtype, args):"""Get the symbol definition and random weight of a network"""input_shape = (args.batch_size, 3, 224, 224)# if "resnet" in name:# n_layer = int(name.split('-')[1])# mod, params = relay.testing.resnet.get_workload(num_layers=n_layer, batch_size=batch_size, dtype=dtype)# elif "vgg" in name:# n_layer = int(name.split('-')[1])# mod, params = relay.testing.vgg.get_workload(num_layers=n_layer, batch_size=batch_size, dtype=dtype)# elif name == 'mobilenet':# mod, params = relay.testing.mobilenet.get_workload(batch_size=batch_size, dtype=dtype)# elif name == 'squeezenet_v1.1':# mod, params = relay.testing.squeezenet.get_workload(batch_size=batch_size, version='1.1', dtype=dtype)# elif name == 'inception_v3':# input_shape = (1, 3, 299, 299)# mod, params = relay.testing.inception_v3.get_workload(batch_size=batch_size, dtype=dtype)# elif name == 'mxnet':# an example for mxnet model# from mxnet.gluon.model_zoo.vision import get_model# block = get_model('resnet18_v1', pretrained=True)# else:# raise ValueError("Unsupported network: " + name)prefix = '/Models/{}/{}'.format(args.version, args.model_name)epoch = args.model_indexmx_sym, arg_params, aux_params = mx.model.load_checkpoint(prefix, epoch)mod, params = relay.frontend.from_mxnet(mx_sym, shape={'data': input_shape}, dtype=dtype, arg_params=arg_params,aux_params=aux_params)net = mod["main"]net = relay.Function(net.params, relay.nn.softmax(net.body), None, net.type_params, net.attrs)mod = relay.Module.from_expr(net)return mod, params, input_shape# You can skip the implementation of this function for this tutorial.
def tune_tasks(tasks,measure_option,tuner='xgb',n_trial=1000,early_stopping=None,log_filename='tuning.log',use_transfer_learning=True,try_winograd=True):if try_winograd:for i in range(len(tasks)):try: # try winograd templatetsk = autotvm.task.create(tasks[i].name, tasks[i].args,tasks[i].target, tasks[i].target_host, 'winograd')input_channel = tsk.workload[1][1]if input_channel >= 64:tasks[i] = tskexcept Exception:pass# create tmp log filetmp_log_file = log_filename + ".tmp"if os.path.exists(tmp_log_file):os.remove(tmp_log_file)for i, tsk in enumerate(reversed(tasks)):prefix = "[Task %2d/%2d] " %(i+1, len(tasks))# create tunerif tuner == 'xgb' or tuner == 'xgb-rank':tuner_obj = XGBTuner(tsk, loss_type='rank')elif tuner == 'ga':tuner_obj = GATuner(tsk, pop_size=100)elif tuner == 'random':tuner_obj = RandomTuner(tsk)elif tuner == 'gridsearch':tuner_obj = GridSearchTuner(tsk)else:raise ValueError("Invalid tuner: " + tuner)if use_transfer_learning:if os.path.isfile(tmp_log_file):tuner_obj.load_history(autotvm.record.load_from_file(tmp_log_file))# do tuningn_trial = min(n_trial, len(tsk.config_space))tuner_obj.tune(n_trial=n_trial,early_stopping=early_stopping,measure_option=measure_option,callbacks=[autotvm.callback.progress_bar(n_trial, prefix=prefix),autotvm.callback.log_to_file(tmp_log_file)])# pick best records to a cache fileautotvm.record.pick_best(tmp_log_file, log_filename)os.remove(tmp_log_file)def tune_and_evaluate(tuning_opt, target, log_file, dtype, args):# extract workloads from relay programprint("Extract tasks...")mod, params, input_shape = get_network(dtype, args)tasks = autotvm.task.extract_from_program(mod["main"], target=target,params=params, ops=(relay.op.nn.conv2d,))# run tuning tasksprint("Tuning...")tune_tasks(tasks, **tuning_opt)# compile kernels with history best recordswith autotvm.apply_history_best(log_file):print("Compile...")with relay.build_config(opt_level=3):graph, lib, params = relay.build_module.build(mod, target=target, params=params)# export librarytmp = tempdir()filename = "/Outputs/tvm_autotuning/{}/{}_auto_tune_deploy_batch_{}_lib.tar".format(args.version,args.model_name, args.batch_size)lib.export_library(tmp.relpath(filename))with open('/Outputs/tvm_autotuning/{}/{}_auto_tune_deploy_batch_{}_graph.json'.format(args.version,args.model_name,args.batch_size) , 'w') as f:f.write(graph)with open('/Outputs/tvm_autotuning/{}/{}_auto_tune_deploy_batch_{}_params.params'.format(args.version,args.model_name,args.batch_size) , 'wb') as f:f.write(relay.save_param_dict(params))# load parametersctx = tvm.context(str(target), 0)module = runtime.create(graph, lib, ctx)data_tvm = tvm.nd.array((np.random.uniform(size=input_shape)).astype(dtype))module.set_input('data', data_tvm)module.set_input(**params)# evaluateprint("Evaluate inference time cost...")ftimer = module.module.time_evaluator("run", ctx, number=1, repeat=600)prof_res = np.array(ftimer().results) * 1000 # convert to millisecondprint("Mean inference time (std dev): %.2f ms (%.2f ms)" %(np.mean(prof_res), np.std(prof_res)))# We do not run the tuning in our webpage server since it takes too long.
# Uncomment the following line to run it by yourself.if __name__ == '__main__':parser = argparse.ArgumentParser(description='score a model on a dataset')parser.add_argument('--version', type=str, default='porno')parser.add_argument('--model-name', type=str, default='resnetv1d-101-320x320')parser.add_argument('--model-index', type=int, default=16)parser.add_argument('--batch-size', type=int, default=1)parser.add_argument('--tag', type=str, default='')args = parser.parse_args()if not os.path.exists(os.path.join('/Outputs/tvm_autotuning/{}'.format(args.version))):os.mkdir(os.path.join('/Outputs/tvm_autotuning/{}'.format(args.version)))#### DEVICE CONFIG ####target = tvm.target.cuda()#### TUNING OPTION ####log_file = '/Outputs/tvm_autotuning/{}/{}_batch_{}.log'.format(args.version, args.model_name, args.batch_size)dtype = 'float32'tuning_option = {'log_filename': log_file,'tuner': 'xgb','n_trial': 2000,'early_stopping': 600,'measure_option': autotvm.measure_option(builder=autotvm.LocalBuilder(timeout=10),runner=autotvm.LocalRunner(number=20, repeat=3, timeout=4, min_repeat_ms=150),# runner=autotvm.RPCRunner(# '1080ti', # change the device key to your key# '0.0.0.0', 9190,# number=20, repeat=3, timeout=4, min_repeat_ms=150)),}tune_and_evaluate(tuning_option, target, log_file, dtype, args)TensorRT
这里简单介绍一下TensorRT,也是模型加速的利器,并且tvm和tensorRT做的对与模型图的优化都差不多,可以参考。
TensorRT是Nvidia出品的用于将不同框架训练的模型部署到GPU的加速引擎,可以自动将不同框架的模型转换为TensorRT模型,并进行模型加速。
TensorRT进行模型加速主要有两点:
- TensorRT支持int8以及FP16计算
- TensorRT对网络进行重构以及优化:
去掉网络中的无用层
网络结构的垂直整合
网络结构的水平融合



参考资料
TVM官网: https://tvm.ai/
TVM论文:arxiv: https://arxiv.org/abs/1802.04799
tensorRT加速参考文献:https://blog.csdn.net/xh_hit/article/details/79769599
Nvidia参考文献:https://devblogs.nvidia.com/production-deep-learning-nvidia-gpu-inference-engine/






![TVM[2] —— TVM简介和发展](https://img-blog.csdnimg.cn/02bb2422b78142aba58da82e9fe1b568.png#pic_center)