Linux随机数发生器
日期:2017-11-29 01:42:10 星期三
- Linux随机数发生器
- 一、源代码的基本情况
- Linux内核版本
- 涉及文件
- 功能概述
- 二、外部访问接口
- 内核层输出接口
- 用户层输出接口
- 环境噪音输入接口
- 三、核心源码分析
- 随机数发生器理论
- 熵池结构
- 熵的加入
- 随机数的生成
- 启动脚本
- 四、回答主要问题
- 核心代码抽取
- 初始化漏洞攻击
- 五、参考文献
- 一、源代码的基本情况
一、源代码的基本情况
Linux内核版本
3.5.4
涉及文件
- /include/linux/random.h
- /drivers/char/random.c
功能概述
Linux内核随机数生成器是Linux操作系统内核的重要组成部分,该生成器从设备驱动等地方获取环境的随机噪声,从理论上返回难于预测的真随机数。该生成器的应用场景涵盖于具有较高安全性的协议栈,防止被黑客等进行爆破,如TCP序列号生成、DNS报文ID生成、TLS/SSL加密之类需要难以被预测的随机数场景。
二、外部访问接口
内核层输出接口
void get_random_bytes(void *buf, int nbytes);
void get_random_bytes_arch(void *buf, int nbytes);get_random_bytes,是一个内核接口,仅在内核编程中使用,会将随机数按照nbytes大小填充到buf分区,可用于TCP序列号的生成等。该函数为非阻塞,不会因为熵池的熵值不够而阻塞,所以会有一定的安全问题。
get_random_bytes_arch,也是一个内核接口,使用的是硬件架构级别的随机数生成器,所以效率比上面软件生成的随机数高出好多。但是难以保证该硬件级别的随机数生成器是否足够安全。如果需要比较快速,而且相信该硬件随机数生成器的安全性话,是个不错的选择。如果硬件不支持,会调用get_random_bytes函数。
用户层输出接口
除了上面两个内核接口,在用户层面也有相应的接口,就是linux中常见的/dev/urandom 和 /dev/random 这两个文件。在shell中,可以用dd和cat等命令直接获取随机数,也可以直接写个程序读取这两个文件即可。
# 从/dev/urandom处获取32个字节的随机数,并放置于本地的urand.txt文件
dd if=/dev/urandom of=./urand.txt count=1 bs=32
# 从/dev/random处获取32个字节的随机数,并放置于本地的rand.txt文件
dd if=/dev/random of=./rand.txt count=1 bs=32/dev/random适用于对随机数安全性要求比较高的情形,但为了保证安全,该文件的读取偶尔会阻塞等待熵池的熵值达到某个阈值。
/dev/urandom没有上面的限制,不会因为熵值不够而导致阻塞,可以源源不断获取所需的随机数。但随着越来越多的随机数被获取,而且熵池的随机源没有被进一步补充,新产生的随机数的安全性就会有一定的下降,有可能被人攻破,但大多数的应用场景已经够用了。
环境噪音输入接口
void add_device_randomness(const void *, unsigned int);
void add_input_randomness(unsigned int type, unsigned int code, \unsigned int value);
void add_interrupt_randomness(int irq, int irq_flags);
void add_disk_randomness(struct gendisk *disk);add_device_randomness,是一个内核接口,可将设备信息或者系统启动等信息添加到input和nonblocking的熵池中去,不同的机器会有不同的设备信息,如MAC地址、机器序列号等,主要是用于初始化这些熵池。为了避免拥有相同设备的机器带来的安全问题,该接口不增加熵池的熵值。
add_input_randomness,也是一个内核接口,用于添加输入设备的随机性,该随机性包括输入事件本身的信息和输入的中断计时。
add_interrupt_randomness,也是一个内核接口,使用中断计时作为随机源添加到熵池中。
add_disk_randomness,也是一个内核接口,使用硬盘的寻道时间作为熵池的随机源,但对于高性能的固态硬盘来讲,寻道时间非常短,而且相对稳定,所以此时的寻道时间不适合用来作为随机源。
三、核心源码分析
随机数发生器理论
计算机作为一种可预测性较强的设备,很难生成真正的随机数,然而可以使用伪随机数算法来缓解这个问题。但伪随机数有很致命的一点,就是攻击者可以通过各种攻击手段猜到伪随机数发生器的序列,在一些应用场景下,使用这样的伪随机数是十分危险的。
为了解决上面的问题,我们可以从计算机的环境中收集“环境噪音”等外部攻击者难以获取的信息,然后把它们用于随机数的生成,就可以确保产生的随机数难以被预测。来自环境的随机性来源包括键盘、鼠标和某些中断的中断计时,以及其他非确定性特别强和难以被预测的事件。把这些来源的随机性使用类似CRC机制的方法加入到“熵池”中,这种CRC机制在密码学角度可能不是特别安全,但速度足够快,也可以在一定程度上避免被恶意加入熵。在加入熵的过程中,还会根据实际情况计算随机数产生器的内部状态中的熵值,即该熵值代表该系统的随机程度,侧面反映该系统此刻的安全性。
在获取随机数时,随机数是通过对熵池进行SHA哈希计算得到的。使用SHA哈希,是为了避免熵池的内部状态直接被外部获取,从而直接对后面的随机数进行预测。虽然目前没有人可以对SHA进行逆向,但是难以避免未来的技术可以攻陷。此时,要保证从随机发生器返回的数据量小于熵池内部状态的熵值,这样输出数据是完全不可预知的。同时,当输出数据时,熵池的熵值也要进行相应地降低。
熵池结构
熵池的结构,如上图所示,图片来源于[1],并对其进行一定的修改,使其更加符合本次阅读的源码结构。
linux内核随机数生成器有三个熵池组成,分别是input_pool,blocking_pool和nonblocking_pool。每个熵池都有自己的熵值计数器,用于保存熵池的随机程度。如果有环境噪音流入,会先直接进入input_pool中,同时会测量该环境噪音的熵值,并更新其计数器。blocking_pool和nonblocking_pool会根据具体需求,向input_pool拉取熵,此时它们的熵值计数器也要有相应的增减。
熵池的数据结构如下:
struct entropy_store;
struct entropy_store {/* read-only data: */struct poolinfo *poolinfo;__u32 *pool;const char *name;struct entropy_store *pull;int limit;/* read-write data: */spinlock_t lock;unsigned add_ptr;unsigned input_rotate;int entropy_count;int entropy_total;unsigned int initialized:1;__u8 last_data[EXTRACT_SIZE];
};poolinfo指向熵池信息的结构体,里面有熵池大小以及基于GF(2)进行熵池混合的参数;pool指向具体存放熵池内部状态的数组;pull指向可以进行拉取熵的熵池,由blocking_pool和nonblocking_pool使用;limit代表熵池的熵值是否需要限制在一定的范围内;lock为内核自旋锁,用于解决多线程抢占该熵池的问题;entropy_count是该熵池的计数器,用于保存熵值;剩下的都是为了用于方便操作熵池内部状态。
input_pool的定义如下:
static __u32 input_pool_data[INPUT_POOL_WORDS];static struct entropy_store input_pool = {.poolinfo = &poolinfo_table[0],.name = "input",.limit = 1,.lock = __SPIN_LOCK_UNLOCKED(&input_pool.lock),.pool = input_pool_data
};使用static关键词对熵池内部状态和熵池结构进行定义,保证其全局唯一。其他两个熵池也是用类似的方法进行定义。
熵的加入
在熵池中加入熵的核心算法在_mix_pool_bytes函数中实现,使用了大量的异或、位移等运算将噪音数据打乱分散,最后存储至熵池的数组中。mix_pool_bytes是对其进行自旋锁的封装,用于保证线程安全的。
而credit_entropy_bits用于更新熵池的熵值,里面使用了一些原子操作,也可以保证线程安全。
static int rand_initialize(void)
{init_std_data(&input_pool);init_std_data(&blocking_pool);init_std_data(&nonblocking_pool);return 0;
}在初始化的时候,熵的加入依靠rand_initialize和init_std_data完成。他们使用时间和硬件随机数,调用mix_pool_bytes对三个熵池进行状态初始化。
在系统运行过程中,使用上一章所讲的四个导入接口进行熵池的更新:
void add_device_randomness(const void *, unsigned int);
void add_input_randomness(unsigned int type, unsigned int code, \unsigned int value);
void add_interrupt_randomness(int irq, int irq_flags);
void add_disk_randomness(struct gendisk *disk);add_device_randomese根据设备信息直接更新熵池数据,但不对熵池的熵值进行更新。
add_input_randomness和add_disk_randomness会最终调用add_timer_randomness完成熵池所有的更新,add_timer_randomness使用三阶时间差的方法进行熵值的估算。
add_interrupt_randomness使用自行实现的fast_mix完成熵池的更新。
随机数的生成
产生随机数的两个核心函数是 extract_entropy 和 extract_entropy_user。extract_entropy是在内核态中进行随机数的生成,并拷贝至内核态的内存中,所以不需要考虑与用户态交互的细节。而extract_entropy_user需要把生成的随机数拷贝到用户态的内存中,不仅需要使用copy_to_user进行内存拷贝,还需要在while循环中考虑进程调度和信号处理等问题,防止while循环耗时过长。extract_entropy_user 和 extract_entropy大体类似,不再展开对其讨论。
而extract_entropy的源码大体如下,省去了一些无用部分:
static ssize_t extract_entropy(struct entropy_store *r, void *buf,size_t nbytes, int min, int reserved)
{
...xfer_secondary_pool(r, nbytes);nbytes = account(r, nbytes, min, reserved);while (nbytes) {extract_buf(r, tmp);...}
...
}extract_entropy先调用xfer_secondary_pool函数根据实际条件进行熵从input_pool往blocking_pool或者nonblocking_pool迁移。然后调用account函数根据当前熵池的特性计算目前熵池能导出的随机数的数量,比如blocking_pool需要保证熵值在一定范围内,超出其范围会缩减nbytes的大小。最后调用最重要也是最核心的extract_buf函数来对熵池里的数据进行导出。
对extract_buf函数进行简化后,代码如下:
static void extract_buf(struct entropy_store *r, __u8 *out)
{...sha_init(hash.w);spin_lock_irqsave(&r->lock, flags);for (i = 0; i < r->poolinfo->poolwords; i += 16)sha_transform(hash.w, (__u8 *)(r->pool + i), workspace);__mix_pool_bytes(r, hash.w, sizeof(hash.w), extract);spin_unlock_irqrestore(&r->lock, flags);
...
}extract_buf函数使用SHA对熵池中部分数据进行hash,然后调用__mix_pool_bytes将hash值重新混入熵池中,重新打乱熵池,使得熵池更加不可预测,防止黑客多次取值后直接逆向出随机数生成器的内部状态。
在内核态,可以直接调用get_random_bytes通过extract_entropy获取nonblocking_pool产生的不太安全但速度足够快的随机数。
在用户态,可通过读取/dev/urandom文件,最终调用内核中的urandom_read函数使用extract_entropy_user完成nonblocking_pool产生的随机数的读取;也可以通过读取/dev/random文件,最终调用内核中的random_read函数使用extract_entropy_user完成blocking_pool产生的较为安全随机数的读取。
启动脚本
在系统启动初期,由于没有足够的熵源保证随机数生成的熵值,此时对其进行攻击较为容易。一个可行的解决方法是,自行在Linux系统内添加启动脚本和关机前执行脚本,在关机前先把系统原有熵池的数据存到某个文件中,然后开机的时候再将这些数据恢复到熵池中,保证熵池持续具有较大的熵值。同时为了避免突然断电或者系统崩溃导致关机脚本未执行的情况,启动时在恢复熵池后,又把熵池的状态存下来,或者使用定时任务来保存熵池状态。
在ubuntu 14.04系统中,启动脚本在 /etc/init.d/urandom。
四、回答主要问题
核心代码抽取
为了进一步简化整体的代码,在抽取代码来实现独立随机数模拟器的时候,做了以下修改:
1. 去除多熵池的设计,只保留nonblocking pool。
2. 去除 熵值估计 和 熵值阈值管理 的函数
3. 去除产生和管理random和urandom文件的部分操作
4. 补充了一些缺失的函数,如 sha_init, sha_transform, rol32, min_t 等
5. 添加main函数,用时间作为种子mix_pool_bytes到nonblocking pool中做初始化,并打印出随机数来测试。
改造后的代码:
#include <string.h>
#include <stdint.h>
#include <stdio.h>
#include <time.h>#define OUTPUT_POOL_WORDS 32
#define EXTRACT_SIZE 10
#define SHA_WORKSPACE_WORDS 80#define LONGS(x) (((x) + sizeof(unsigned long) - 1)/sizeof(unsigned long))
#define min_t(type,x,y) \({type __x=(x); type __y=(y); __x<__y?__x:__y;})
#define BigLong(x) (x)#define __u32 unsigned int
#define __u8 unsigned char
#define ssize_t intstatic struct poolinfo {int poolwords;int tap1, tap2, tap3, tap4, tap5;
} poolinfo_table[] = {/* x^128 + x^103 + x^76 + x^51 +x^25 + x + 1 -- 105 */{ 128, 103, 76, 51, 25, 1 },/* x^32 + x^26 + x^20 + x^14 + x^7 + x + 1 -- 15 */{ 32, 26, 20, 14, 7, 1 },
};#define POOLBITS poolwords*32
#define POOLBYTES poolwords*4struct entropy_store;
struct entropy_store {/* read-only data: */struct poolinfo *poolinfo;__u32 *pool;const char *name;/* read-write data: */unsigned add_ptr;unsigned input_rotate;
};static __u32 nonblocking_pool_data[OUTPUT_POOL_WORDS];static struct entropy_store nonblocking_pool = {.poolinfo = &poolinfo_table[1],.name = "nonblocking",.pool = nonblocking_pool_data
};static __u32 const twist_table[8] = {0x00000000, 0x3b6e20c8, 0x76dc4190, 0x4db26158,0xedb88320, 0xd6d6a3e8, 0x9b64c2b0, 0xa00ae278 };static inline uint32_t rol32(uint32_t word, unsigned int shift){return (word << shift) | (word >> (32 - shift));
}static inline uint32_t ror32(uint32_t word, unsigned int shift){return (word >> shift) | (word << (32 - shift));
}/* SHA Begin */
void sha_transform(uint32_t *digest, const char *in, uint32_t *W);
void sha_init(uint32_t *buf);
/* SHA End */static void mix_pool_bytes(struct entropy_store *r, const void *in,int nbytes, __u8 out[64]){unsigned long i, j, tap1, tap2, tap3, tap4, tap5;int input_rotate;int wordmask = r->poolinfo->poolwords - 1;const char *bytes = in;__u32 w;tap1 = r->poolinfo->tap1; tap2 = r->poolinfo->tap2;tap3 = r->poolinfo->tap3; tap4 = r->poolinfo->tap4;tap5 = r->poolinfo->tap5;input_rotate = r->input_rotate; i = r->add_ptr;/* mix one byte at a time to simplify size handling and churn faster */while (nbytes--) {w = rol32(*bytes++, input_rotate & 31);i = (i - 1) & wordmask;/* XOR in the various taps */w ^= r->pool[i]; w ^= r->pool[(i + tap1) & wordmask]; w ^= r->pool[(i + tap2) & wordmask]; w ^= r->pool[(i + tap3) & wordmask]; w ^= r->pool[(i + tap4) & wordmask]; w ^= r->pool[(i + tap5) & wordmask];/* Mix the result back in with a twist */r->pool[i] = (w >> 3) ^ twist_table[w & 7];input_rotate += i ? 7 : 14;}r->input_rotate = input_rotate;r->add_ptr = i;if (out)for (j = 0; j < 16; j++)((__u32 *)out)[j] = r->pool[(i - j) & wordmask];
}static void extract_buf(struct entropy_store *r, __u8 *out)
{int i;union {__u32 w[5];unsigned long l[LONGS(EXTRACT_SIZE)];} hash;__u32 workspace[SHA_WORKSPACE_WORDS];__u8 extract[64];/* Generate a hash across the pool, 16 words (512 bits) at a time */sha_init(hash.w);for (i = 0; i < r->poolinfo->poolwords; i += 16)sha_transform(hash.w, (__u8 *)(r->pool + i), workspace);mix_pool_bytes(r, hash.w, sizeof(hash.w), extract);sha_transform(hash.w, extract, workspace);memset(extract, 0, sizeof(extract));memset(workspace, 0, sizeof(workspace));hash.w[0] ^= hash.w[3]; hash.w[1] ^= hash.w[4];hash.w[2] ^= rol32(hash.w[2], 16);memcpy(out, &hash, EXTRACT_SIZE);memset(&hash, 0, sizeof(hash));
}static ssize_t extract_entropy(struct entropy_store *r, void *buf,size_t nbytes){ssize_t ret = 0, i;__u8 tmp[EXTRACT_SIZE];while (nbytes) {extract_buf(r, tmp);i = min_t(int, nbytes, EXTRACT_SIZE);memcpy(buf, tmp, i);nbytes -= i; buf += i; ret += i;}/* Wipe data just returned from memory */memset(tmp, 0, sizeof(tmp));return ret;
}void get_random_bytes(void *buf, int nbytes){extract_entropy(&nonblocking_pool, buf, nbytes);
}int main(int argc,char* argv[]){char buf[32];time_t seconds = time(NULL);mix_pool_bytes(&nonblocking_pool, &seconds, sizeof(time_t), NULL);if(argc == 2) seconds = (time_t) atol(argv[1]);int i;get_random_bytes(buf, 32);for(i=0; i<32; ++i){printf("%d ", buf[i]);}printf("\n");return 0;
}
由于篇幅有限,上面的 SHA 部分被省去,具体源码可看附件。
编译过程:
gcc rand.c -o rand由于解决了所有对外的依赖,用最简单的方式进行编译即可。
初始化漏洞攻击
原理:
上面提取的程序,使用了常用的time(NULL)产生的时间作为随机源,然后不再添加新的随机熵源了。
由于time(NULL)返回是以“秒”为单位,同时该程序产出的随机数我们也得到了,所以我们只需要知道上次启动该程序的大致时间,对初始化的时间设置一定的范围进行爆破。当生成的随机数数列符合我们之前得到的随机数数列,此时进行初始化的时间种子便是之前运行该程序的初始条件,利用该初始条件我们可以预测该程序接下来产生的随机数。
实验方案:
1. 在特定时间点,运行上述提取程序,产生32个随机数,将前20个作为攻击程序的输入,将12个作为攻击程序的预测输出。
2. 提取的程序可以自定义参数作为随机数种子,方便攻击程序调用进行破解,默认不填使用系统时间。
3. 取一个时间范围,运行攻击程序进行爆破,攻击程序会以不同时间作为种子调用提取程序进行爆破猜解,如果发现前20个符合输出,随即进行后续预测,输出后续的12个生成的随机数。
4. 判断攻击程序预测的12个随机数,和之前随机数程序生成的是否一致,即可判断该攻击是否真实有效。
实验Python代码:
# encoding: utf-8import os
import time
import randomdef getRet(seed=None):if seed is None:argList = ['./rand']else:argList = ['./rand', str(seed)]wf, rf = os.popen2(argList)strList = rf.read().strip().split(' ')intList = map(lambda x: int(x), strList)wf.close()rf.close()return intListif __name__ == '__main__':target = getRet()print "target List: ", targetwaitTime = random.random() * 30print "wait for %s s" % waitTimetime.sleep(waitTime)print "let's attack!"endTime = int(time.time())beginTime = endTime - 100for seed in range(beginTime, endTime):ret = getRet(seed)OK = Truefor i in range(12):if ret[i] != target[i]:OK = Falsebreakif OK:print "found the random seed %d" % seedprint "the predict list is ", ret[12:]print "the target list is ", target[12:]实验结果:
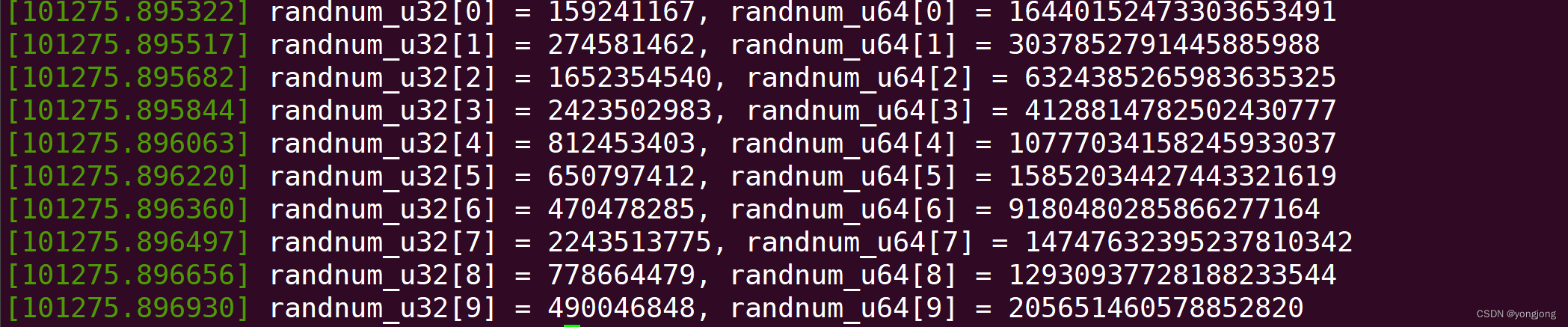
进行三次实验,得到实验截图如下所示:
可见,进行三次猜解,均成功预测原程序接下来的12个随机数数列。所以,一个随机数生成系统,如果没有持续添加新的熵,而且初始状态的搜索空间比较小的情况下,很容易对整个随机数生成系统进行攻破。
五、参考文献
- 曹润聪, 曹立明. Linux 随机数生成器的原理及缺陷[J]. 计算机技术与发展, 2007, 17(10): 109-112.
- Gutterman Z, Pinkas B, Reinman T. Analysis of the linux random number generator[C]//Security and Privacy, 2006 IEEE Symposium on. IEEE, 2006: 15 pp.-385.
- Patrick Lacharme, Andrea Röck, Vincent Stubel, Marion Videau. Analysis of the Linux Random Number Generator. http://users.ics.aalto.fi/arock/slides/slides_devrand.pdf