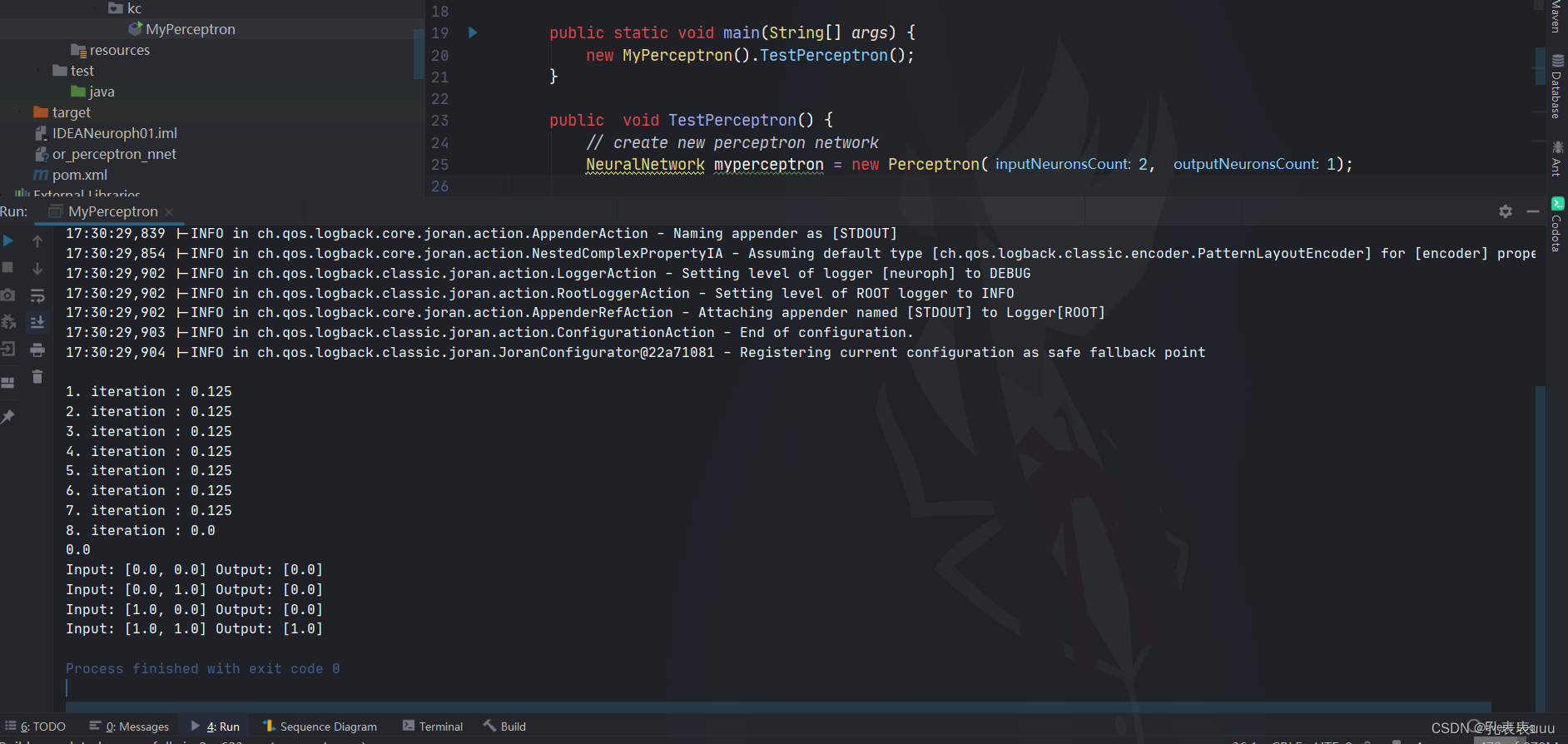
怎么用spss神经网络来分类数据
。
用spss神经网络分类数据方法如下:神经网络算法能够通过大量的历史数据,逐步建立和完善输入变量到输出结果之间的发展路径,也就是神经网络,在这个神经网络中,每条神经的建立以及神经的粗细(权重)都是经过大量历史数据训练得到的,数据越多,神经网络就越接近真实。
神经网络建立后,就能够通过不同的输入变量值,预测输出结果。例如,银行能够通过历史申请贷款的客户资料,建立一个神经网络模型,用于预测以后申请贷款客户的违约情况,做出是否贷款给该客户的决策。
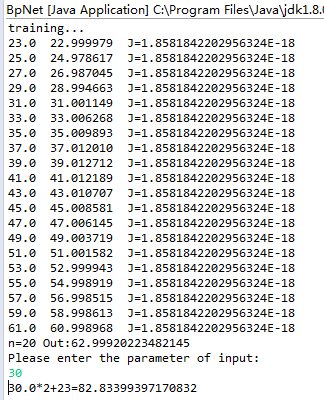
本篇文章将用一个具体银行案例数据,介绍如何使用SPSS建立神经网络模型,用于判断将来申请贷款者的还款能力。
选取历史数据建立模型,一般会将历史数据分成两大部分:训练集和验证集,很多分析者会直接按照数据顺序将前70%的数据作为训练集,后30%的数据作为验证集。
如果数据之间可以证明是相互独立的,这样的做法没有问题,但是在数据收集的过程中,收集的数据往往不会是完全独立的(变量之间的相关关系可能没有被分析者发现)。
因此,通常的做法是用随机数发生器来将历史数据随机分成两部分,这样就能够尽量避免相同属性的数据被归类到一个数据集当中,使得建立的模型效果能够更加优秀。
在具体介绍如何使用SPSS软件建立神经网络模型的案例之前,先介绍SPSS的另外一个功能:随机数发生器。SPSS的随机数发生器常数的随机数据不是真正的随机数,而是伪随机数。
伪随机数是由算法计算得出的,因此是可以预测的。当随机种子(算法参数)相同时,对于同一个随机函数,得出的随机数集合是完全相同的。与伪随机数对应的是真随机数,它是真正的随机数,无法预测也没有周期性。
目前大部分芯片厂商都集成了硬件随机数发生器,例如有一种热噪声随机数发生器,它的原理是利用由导体中电子的热震动引起的热噪声信号,作为随机数种子。
谷歌人工智能写作项目:小发猫

神经网络如何做分类?
神经网络有哪些主要分类规则并如何分类?
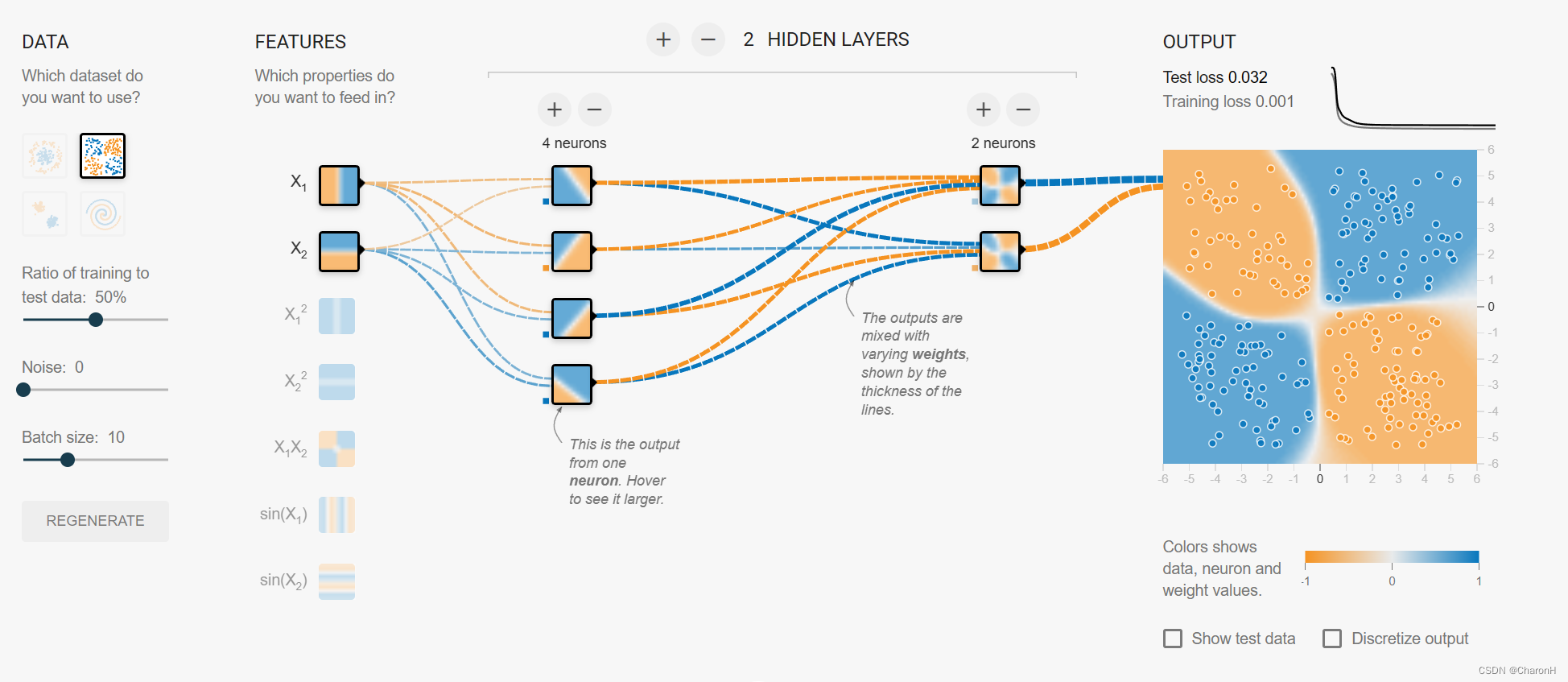
神经网络模型的分类人工神经网络的模型很多,可以按照不同的方法进行分类。其中,常见的两种分类方法是,按照网络连接的拓朴结构分类和按照网络内部的信息流向分类。
1按照网络拓朴结构分类网络的拓朴结构,即神经元之间的连接方式。按此划分,可将神经网络结构分为两大类:层次型结构和互联型结构。
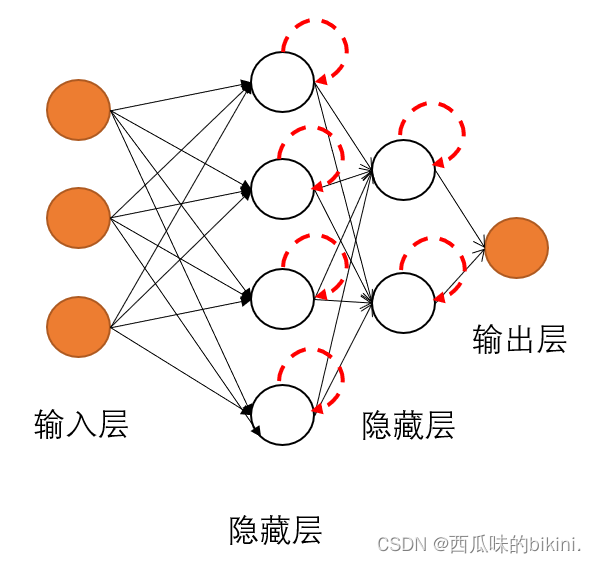
层次型结构的神经网络将神经元按功能和顺序的不同分为输出层、中间层(隐层)、输出层。输出层各神经元负责接收来自外界的输入信息,并传给中间各隐层神经元;隐层是神经网络的内部信息处理层,负责信息变换。
根据需要可设计为一层或多层;最后一个隐层将信息传递给输出层神经元经进一步处理后向外界输出信息处理结果。
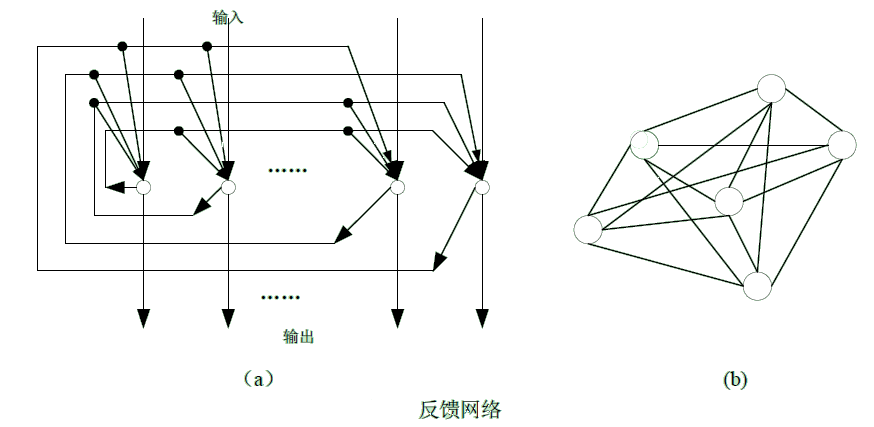
而互连型网络结构中,任意两个节点之间都可能存在连接路径,因此可以根据网络中节点的连接程度将互连型网络细分为三种情况:全互连型、局部互连型和稀疏连接型2按照网络信息流向分类从神经网络内部信息传递方向来看,可以分为两种类型:前馈型网络和反馈型网络。
单纯前馈网络的结构与分层网络结构相同,前馈是因网络信息处理的方向是从输入层到各隐层再到输出层逐层进行而得名的。
前馈型网络中前一层的输出是下一层的输入,信息的处理具有逐层传递进行的方向性,一般不存在反馈环路。因此这类网络很容易串联起来建立多层前馈网络。反馈型网络的结构与单层全互连结构网络相同。
在反馈型网络中的所有节点都具有信息处理功能,而且每个节点既可以从外界接受输入,同时又可以向外界输出。
现在有一组数据用神经网络分类怎么办
什么叫数据挖掘、神经网络
数据挖掘(DataMining)是指通过大量数据集进行分类的自动化过程,以通过数据分析来识别趋势和模式,建立关系来解决业务问题。
换句话说,数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
原则上讲,数据挖掘可以应用于任何类型的信息存储库及瞬态数据(如数据流),如数据库、数据仓库、数据集市、事务数据库、空间数据库(如地图等)、工程设计数据(如建筑设计等)、多媒体数据(文本、图像、视频、音频)、网络、数据流、时间序列数据库等。
也正因如此,数据挖掘存在以下特点:(1)数据集大且不完整数据挖掘所需要的数据集是很大的,只有数据集越大,得到的规律才能越贴近于正确的实际的规律,结果也才越准确。除此以外,数据往往都是不完整的。
(2)不准确性数据挖掘存在不准确性,主要是由噪声数据造成的。比如在商业中用户可能会提供假数据;在工厂环境中,正常的数据往往会收到电磁或者是辐射干扰,而出现超出正常值的情况。
这些不正常的绝对不可能出现的数据,就叫做噪声,它们会导致数据挖掘存在不准确性。(3)模糊的和随机的数据挖掘是模糊的和随机的。这里的模糊可以和不准确性相关联。
由于数据不准确导致只能在大体上对数据进行一个整体的观察,或者由于涉及到隐私信息无法获知到具体的一些内容,这个时候如果想要做相关的分析操作,就只能在大体上做一些分析,无法精确进行判断。
而数据的随机性有两个解释,一个是获取的数据随机;我们无法得知用户填写的到底是什么内容。第二个是分析结果随机。数据交给机器进行判断和学习,那么一切的操作都属于是灰箱操作。
神经网络:神经网络由于本身良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性非常适合解决数据挖掘的问题,因此近年来越来越受到人们的关注。