注:本文手动搬家自我的新浪博客点击打开链接
从2016年3月份左右,我的毕业设计开题答辩时间正好是AlphaGo大战李世石之日。还记得当时答辩PPT最末引用的图片还是这张:

李世石大战Google的AlphaGo
不过当时答辩情况并不理想,答辩组老师也没发现我留的这个彩蛋。想想但是我是一种多么激动的心情面对这个毕业设计课题的吗,第一次与前沿科技这么近距离的沾边。可是他们咋就没有多关注关注新闻呢,而且当天下午就是对战之日呀!!
到如今我毕业已近一载,而alphago也已战胜柯洁,隐藏功与名默默退役,将对弈棋谱献于世人研究。我的配图也该换一换了:

柯洁对战AlphaGo
好了,过了这么久,在这过程中又接触到了许多神经网络内容。是该蹭蹭热点,重拾毕业设计内容,来一发BP神经网络的总结和探寻了。
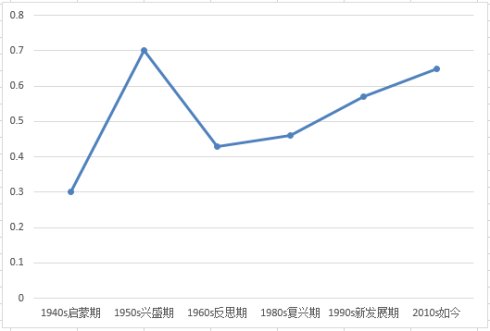
其实,神经网络在上世纪50年代,神经网络就引发过一次热潮,不过由于当时的硬件计算速度和神经网络模型研究的不够深入。在短暂的兴盛后,在60年代末陷入了沉默,之后是默默的反思探索,默默耕耘。直至如今,当前人工智能将发展如何就让历史来评判吧。
神经网络发展历史
如今,随之BP神经网络模型,深度神经网络模型的提成,而且硬件水平的大福提升(加工工艺都已经到8nm了),AlphaGo的围棋挑战又一次引爆了这个AI热潮。谈谈我对BP神经网络的一些看法吧,神经网络应用,其核心就“ 几乎万能的模型+误差修正函数”。
例如:看到某品牌的泥塑很好,小作坊想仿造,拥有很多陶泥( 输入),还有可修改的模具( 万能的模型),可套出任意形状。然后开始仿制,首先刚起步很蠢用一大坨陶泥模子套出个长条形身体,出去卖当然市场不买账,返工对比发现 需要手和脚( 误差判断修正函数),然后一次一次的尝试改正(大小尺寸、头发、眼睛等),然后慢慢成型,这个模型就记录各种参数,然后直接套模子出产品就是的了。
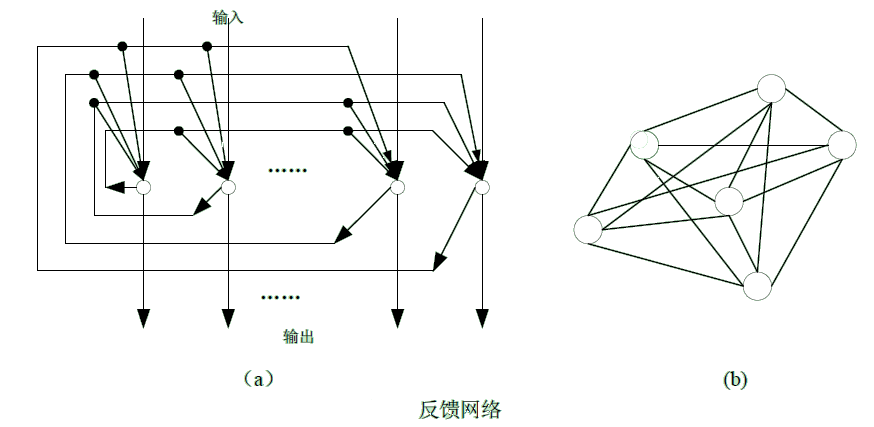
BP神经网络(Back Propagation)误差反向传播神经网络,是通过误差反向传播算法实现的神经网络模型,其核心是误差反向传播思想和算法,简称BP神经网络。那么BP神经网络的 万能模型就是下图中的神经网络拓扑结构了:
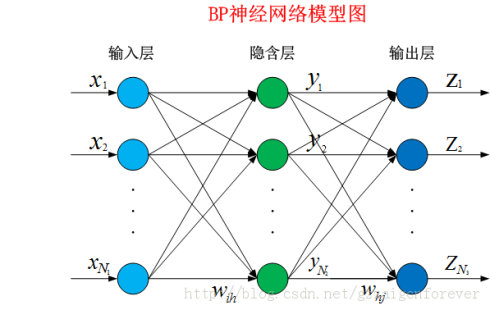
研究证明: 神经元网络拓扑结构可以逼近任意非线性函数(国外论文数学论证了的,就当它具有这个功能就行了,仿生学厉害呀,仿造人脑神经元间的信息传递) 。而且观察到神经元网络为多输入的并行结构,能同时输入不同类型的信息进行处理并给出输出,高效而迅速。
有了万能的淘宝,呕不,万能的模具。还差一个 美工刀来雕琢修改了。倒是有很多种 偏差修正函数,这里提一种我熟悉也较为通用(通用始终比不上专用的喽)的修正判定函数吧。
二次型性能修正:和最小二乘法的思想相似,取偏差的平方差构成2次函数。
简单的例子:有一根绳子长度为x米,需要另外剪一根和它长度一样的绳子。第一次剪了y1米,y1>x长了就需要剪短。第二次再修正剪短一节n1米,当前的绳子长y2=y1-n1,发现y2短了需要增长。第三次再修正增加一节n2米...以此类推,不断的逼近目标,使偏差趋于零。
最小二乘法:我们都知道一元二次函数 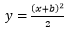 的曲线是一个“U”形,如下图所示:
的曲线是一个“U”形,如下图所示:
的曲线是一个“U”形,如下图所示: 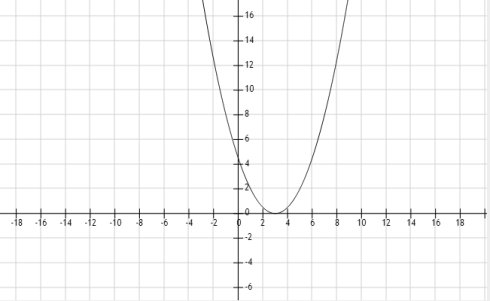
一元二次函数曲线
可以观察到,U形最底部与x相交处函数值最小,趋近于零。由梯度下降法求解极小值思想,向函数增大的反方向或者函数减小的同方向迈步,而函数的变化方向可以通过求导得到,在交点左侧导数小于零,右侧导数大于零。
梯度下降法:导数为正函数正在增大,外部修正调节效果变坏,应反向调节使其减小;导数为负函数正在减小外部修正修正调节效果变好,函数正在减小趋近于零,保存当前调节。通过不断的正反向梯度调节,最终逐渐逼近于导数为零时,纯2次函数的导数为零点即偏差为零点。从而达到学习调整权值逐渐趋近期望目标,使偏差逼近零。( 不断的剪短或增加绳子的长度,逐渐的趋近于目标值,偏差趋于零)。
于是借助于其特性,我们假定当前值和目标值得偏差为ek=y-x,设函数 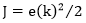 ,就可以确定该用美工刀挖一刀或者加点材料了。
,就可以确定该用美工刀挖一刀或者加点材料了。
,就可以确定该用美工刀挖一刀或者加点材料了。 
二次型性能修正
当然最小二乘法修正函数是较为原始的方法了,已不大适用于当前复杂的情况了。(我们一直假定的是偏差ek是一个一元函数,但如果偏差为二元甚至多元或者多次函数呢?那函数曲线就不单单是一个U形曲线了。)例如若最终拟合的函数曲线为一个多段多凹曲线时,二次性能修正函数就可能陷入局部最优解(局部U形)。例如下图的曲线:
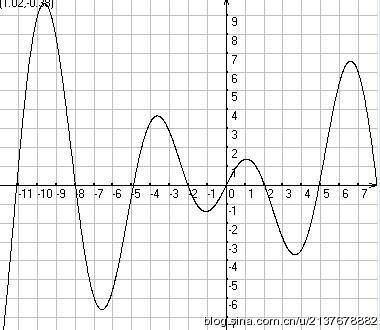
多凹段曲线
上图多凹段曲线(并不太严谨举例说明足够了)中,有多个U形凹坑,随时一不小心就会陷入一个局部凹坑,但其并不是整个偏差函数趋于零的最小值,可见二次性能修正还有局限性。
但对于一般情况,已经足够了,作为见识神经网络神奇的拟合能力还是可以的。相信AlphaGo的学习修正函数比这个高级的多。 --------------------------------------------- 分割线---------------------------------------------
接下来进入数学世界。。。有人在其中乐此不彼(例如《知无涯者》中的拉马努金),有人就只有使劲摆摆头了。我呢,处于中间阶段吧,愿意见到数学的神奇,但让我自己深入研究,那就太难为我了。
神经元是以生物研究及大脑的响应机制而建立的拓扑结构网络,模拟神经冲突的过程,多个树突的末端接受外部信号,并传输给神经元处理融合,最后通过轴突将神经传给其它神经元或者效应器。神经元的拓扑结构如图:
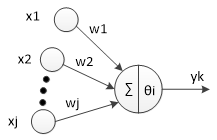
神经元拓扑结构
对于第i个神经元,X1、X2、…、Xj为神经元的输入,输入常为对系统模型关键影响的自变量,W1、W2、…、Wj为连接权值调节各个输入量的占重比。将信号结合输入到神经元有多种方式,选取最便捷的线性加权求和可得neti神经元净输入。
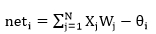
式中θi为阀值,当信号强度达到强度θi时才激活。
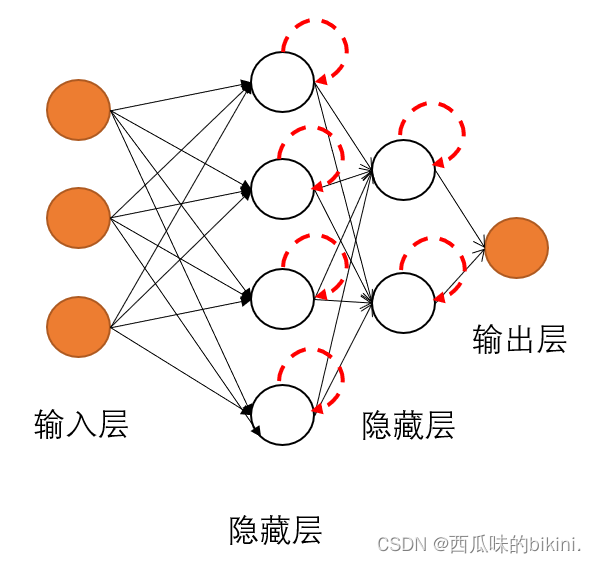
在拓展构建成多层神经元,就成了神经网络模型。一般来说,神经网络由3种层构成:输入层、隐含层、输出层。
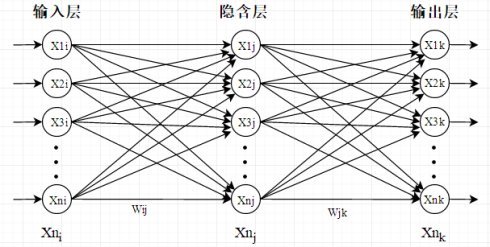
神经网络结构
输入的层数(Xi):
需要选取对系统对象 影响较大的变量,例如 逼近函数
y(k)=sin(5x)+y(k-1)^2;
可以基本确定影响因素为:
输入样本1: Sin(5x)或者x
输入样本2: y(k-1)
这需要一定的练习才能更好的掌握,也就是输入的是一些教师信号(由什么可以及应该得到什么),通过不断的调整各个权值来逐步的逼近这个函数规律。
输入(Wij)输出(Wjk)权值:
一般取[0,1]或[-1,1]区域内的随机值,C语言中使用(rand(srand(time(NULL))00)/1000.0以时间作种的随机数变换得到,具体为什么要取这之间的权值,还不太清楚,计算的方便可能是影响因素之一。
隐含层数Xj:
隐含层书上所说基本靠经验试凑确定,还有是输入层数+输出层数+值,一般我们取5层就可以满足要求,隐含层数的增加可以更加精准的逼近目标函数,提高网络的精度。
输出层数Xk:
所求对象的输出,需要想要得到的数值。 例如 y(k)=sin(5x)+y(k-1)^2;则对象输出为yn(k),后边根据理想教师信号的输出y(k)与网络计算的输出做误差运算来修正权值逼近理想输出。
隐含层神经元的输入为所有输入的加权之和:
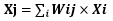
即例如" X1j=W11*X1+W21*X2+W31*X3+...+Wi1*Xj "以此类推。
隐含层神经元输出Xj'采用S型函数激发Xj得:
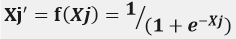
隐含层的激活函数选择:
常用的是S型的对数或正切激活函数以及线性函数,S型函数具有非线性放大系数功能,它可以把输入从负无穷大到正无穷大的信号变换成-1到1之间输出,对较大的输入信号,放大系数较小,而对较小的输入信号,放大系数则较大,所以采用S型激活函数可以处理和逼近非线性的输入、输出关系。如果在输出层采用S型函数,输出则被现在到一个很小的范围,若采用线性激活函数,则可使网络输出任何值。所以当网络的输出没有限制时在隐含层采用S型激活函数,而输出层采用线性激活函数。
输出层神经元为所有隐含层输出的加权之和:
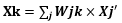
网络输出与理想输出误差为:
e(n)=XLk(n)-Xk(n) (理想输出-网络输出)
其中k为第几个输出神经元,n为 计算值的第几次。
由最小二乘法思想,引入误差性能指标函数:
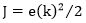
反向传播:求导,或者偏导,调整各层间的权值。隐含层到输出层连接权值修正值:
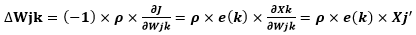
输入层到隐含层连接权值修正值:
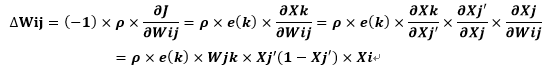
式中p为学习速率,p一般取0~1之间的值稳定。(-1)是由梯度下降法得来的,导数>0时需反向控制,导数<0时需保持控制,所以乘以-1正好抵消满足。则下一次隐含层到输出层的连接权值Wjk和输入层到隐含层的连接权值Wij分别为:
Wjk(n+1)=Wjk(n)+△Wij
Wij(n+1)=Wij(n)+△Wjk
为了避免权值的学习过程发生振荡、收敛速度慢,需要考虑上次权值变换对本次权值变换的影响,即加入动量因子α(为了一定程度上避免陷入局部凹坑)。此时权值为:
Wjk(n+1)=Wjk(n)+△Wjk+ α(Wjk(n)-Wjk(n-1))
Wij(n+1)=Wij(n)+△Wij+ α(Wij(n)-Wij(n-1))
通常而言0<α<1,大小合适可以振荡越过局部凹坑,太大就可能振荡的无法趋近于全局最优解,太小无法振荡越出局部凹坑,但通常而言,一般的函数就够了。由此可见反向学习算法还是挺重要的,所以这把美工刀需要选择好。
参考书籍----《智能控制》-刘金琨
--------------------------------------------- 分割线 ---------------------------------------------
终于,数学讨论结束了。下面我们进行试验论证,使用Java实现BP神经网络算法。
Java Code
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 | | import java.util.Scanner; public class BpNet { private static final int IM = 1; //输入层数量 private static final int RM = 8; //隐含层数量 private static final int OM = 1; //输出层数量 private double learnRate = 0. 55; //学习速率 private double alfa = 0. 67; //动量因子 private double Win[][] = new double[IM][RM]; //输入到隐含连接权值 private double oldWin[][] = new double[IM][RM]; private double old1Win[][] = new double[IM][RM]; private double dWin[][] = new double[IM][RM]; private double Wout[][] = new double[RM][OM]; //隐含到输出连接权值 private double oldWout[][] = new double[RM][OM]; private double old1Wout[][] = new double[RM][OM]; private double dWout[][] = new double[RM][OM]; private double Xi[] = new double[IM]; private double Xj[] = new double[RM]; private double XjActive[] = new double[RM]; private double Xk[] = new double[OM]; private double Ek[] = new double[OM]; private double J = 0. 1; public static void main( String[] arg) { BpNet bpNet = new BpNet(); bpNet.train(); Scanner keyboard = new Scanner(System. in); System.out.println( "Please enter the parameter of input:"); double parameter; while((parameter = keyboard.nextDouble()) != - 1) System.out.println(parameter + "*2+23=" + bpNet.bpNetOut(parameter / 100. 0)[ 0] * 100. 0); } public void train() { double y; int n = 0; //初始化权值和清零// bpNetinit(); System.out.println( "training..."); while(J > Math.pow( 10, - 17)) { for(n = 0; n < 20; n++) { y = n * 2 + 23; //逼近对象 //前向计算输出过程// bpNetForwardProcess(n / 100. 0, y / 100. 0); //反向学习修改权值// bpNetReturnProcess(); } } //在线学习后输出// for(n = 0; n < 20; n++) { y = n * 2 + 23; //逼近对象 System.out.printf( "%.1f ", y); System.out.printf( "%f ", bpNetOut(n / 100. 0)[ 0] * 100. 0); System.out.println( "J=" + J); } System.out.println( "n=20 " + "Out:" + this.bpNetOut( 20 / 100. 0)[ 0] * 100); } // // BP神经网络权值随机初始化 // Win[i][j]和Wout[j][k]权值初始化为[-0.5,0.5]之间 // public void bpNetinit() { //初始化权值和清零// for( int i = 0; i < IM; i++) for( int j = 0; j < RM; j++) { Win[i][j] = 0. 5 - Math.random(); Xj[j] = 0; } for( int j = 0; j < RM; j++) for( int k = 0; k < OM; k++) { Wout[j][k] = 0. 5 - Math.random(); Xk[k] = 0; } } // // BP神经网络前向计算输出过程 // @param inputParameter 归一化后的理想输入值(单个double值) // @param outputParameter 归一化后的理想输出值(单个double值) // public void bpNetForwardProcess( double inputParameter, double outputParameter) { double input[] = {inputParameter}; double output[] = {outputParameter}; bpNetForwardProcess(input, output); } // // BP神经网络前向计算输出过程--多个输入,多个输出 // @param inputParameter 归一化后的理想输入数组值 // @param outputParameter 归一化后的理想输出数组值 // public void bpNetForwardProcess( double inputParameter[], double outputParameter[]) { for( int i = 0; i < IM; i++) { Xi[i] = inputParameter[i]; } //隐含层权值和计算// for( int j = 0; j < RM; j++) { Xj[j] = 0; for( int i = 0; i < IM; i++) { Xj[j] = Xj[j] + Xi[i] * Win[i][j]; } } //隐含层S激活输出// for( int j = 0; j < RM; j++) { XjActive[j] = 1 / ( 1 + Math.exp(-Xj[j])); } //输出层权值和计算// for( int k = 0; k < OM; k++) { Xk[k] = 0; for( int j = 0; j < RM; j++) { Xk[k] = Xk[k] + XjActive[j] * Wout[j][k]; } } //计算输出与理想输出的偏差// for( int k = 0; k < OM; k++) { Ek[k] = outputParameter[k] - Xk[k]; } //误差性能指标// J = 0; for( int k = 0; k < OM; k++) { J = J + Ek[k] * Ek[k] / 2. 0; } } // //BP神经网络反向学习修改连接权值过程 // public void bpNetReturnProcess() { //反向学习修改权值// for( int i = 0; i < IM; i++) //输入到隐含权值修正 { for( int j = 0; j < RM; j++) { for( int k = 0; k < OM; k++) { dWin[i][j] = dWin[i][j] + learnRate * (Ek[k] * Wout[j][k] * XjActive[j] * ( 1 - XjActive[j]) * Xi[i]); } Win[i][j] = Win[i][j] + dWin[i][j] + alfa * (oldWin[i][j] - old1Win[i][j]); old1Win[i][j] = oldWin[i][j]; oldWin[i][j] = Win[i][j]; } } for( int j = 0; j < RM; j++) //隐含到输出权值修正 { for( int k = 0; k < OM; k++) { dWout[j][k] = learnRate * Ek[k] * XjActive[j]; Wout[j][k] = Wout[j][k] + dWout[j][k] + alfa * (oldWout[j][k] - old1Wout[j][k]); old1Wout[j][k] = oldWout[j][k]; oldWout[j][k] = Wout[j][k]; } } } // // BP神经网络前向计算输出,训练结束后测试输出 // @param inputParameter 测试的归一化后的输入值 // @return 返回归一化后的BP神经网络输出值,需逆归一化 // public double[] bpNetOut( double inputParameter) { double[] input = {inputParameter}; return bpNetOut(input); } // // BP神经网络前向计算输出,训练结束后测试输出 // @param inputParameter 测试的归一化后的输入数组 // @return 返回归一化后的BP神经网络输出数组 // public double[] bpNetOut( double[] inputParameter) { //在线学习后输出// for( int i = 0; i < IM; i++) { Xi[i] = inputParameter[i]; } //隐含层权值和计算// for( int j = 0; j < RM; j++) { Xj[j] = 0; for( int i = 0; i < IM; i++) { Xj[j] = Xj[j] + Xi[i] * Win[i][j]; } } //隐含层S激活输出// for( int j = 0; j < RM; j++) { XjActive[j] = 1 / ( 1 + Math.exp(-Xj[j])); } //输出层权值和计算// double Uk[] = new double[OM]; for( int k = 0; k < OM; k++) { Xk[k] = 0; for( int j = 0; j < RM; j++) { Xk[k] = Xk[k] + XjActive[j] * Wout[j][k]; Uk[k] = Xk[k]; } } return Uk; } } |


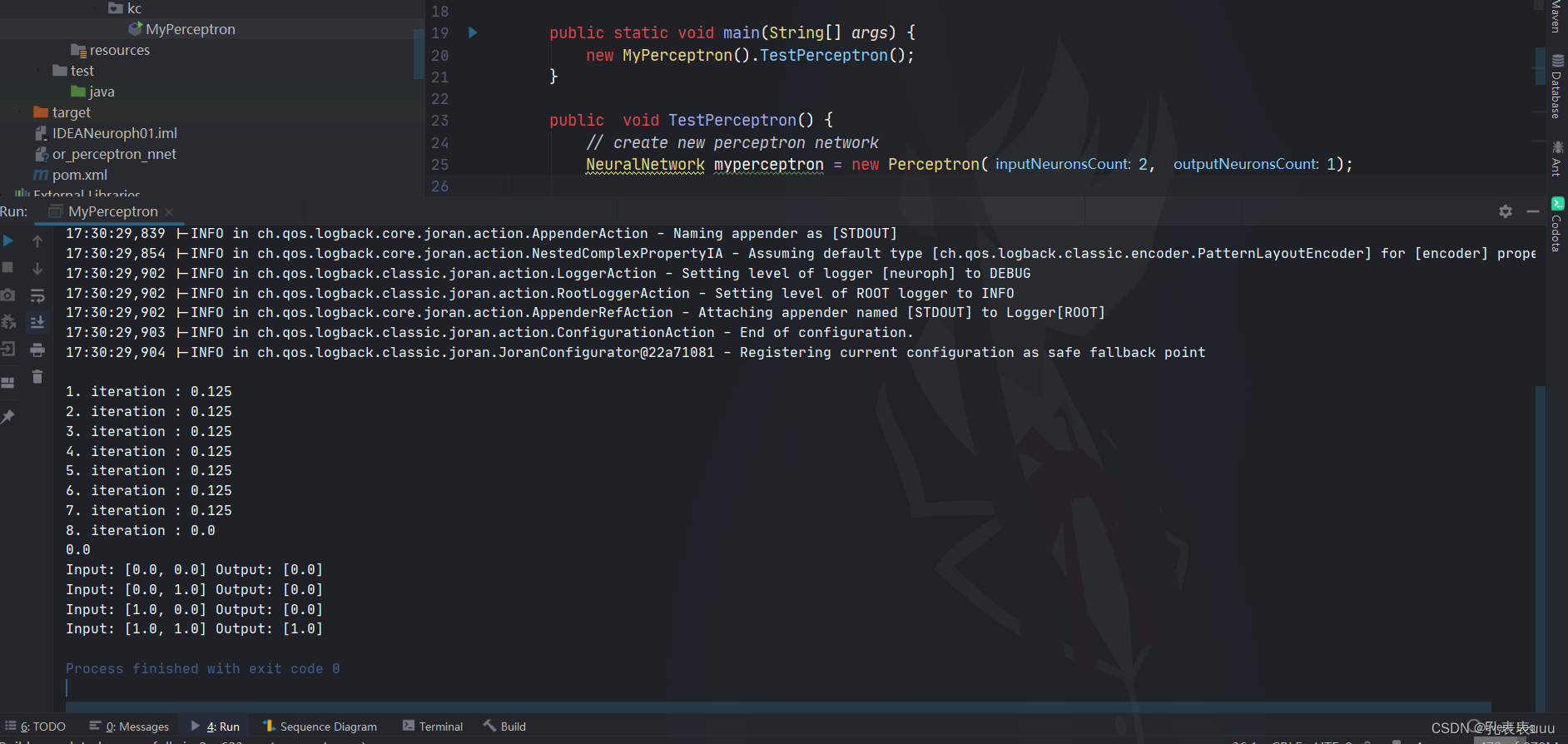
以上就是JAVA写的BP神经网络拟合曲线Y=n*2+23的程序。我们看看 拟合结果吧:
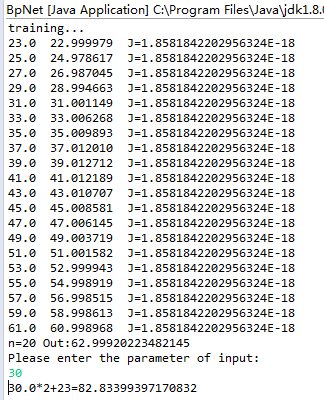
BP神经逼近函数Y=n*2+23
第一列为理想输出值(函数Y=n*2+23,n从0到19),第二列为训练完后BP神经网络计算逼近输出值,第三列为误差性能指标(方差和)。可以观察到第一列和第二列的值非常接近,说明神经网络训练逼近模型还是很成功的。最后我们还测试了n=30时,BP神经网络模具输出值,也很理想接近83.0(我们只训练了n从0到19的数据)。
可见经过多次(通常上万次)权值修正函数(美工刀)的微调,神经网络结构(万能模具)已几乎具有函数Y=n*2+23的功能。
好了,见识了神经网络结构的巨大潜力,来细究它的一些局限和注意事项吧:
输入样本归一化的重要性:
1.避免数值过大问题:若不进行归一化处理,所得的输出,权值等往往会很大,而偏差也就很大,而权值调节中需要偏差*权值*输入,及偏差的积分和,这得到的数值将会很大,超出了数量级,也就超出了计算机等处理器的数值范围(我开始就是这样,导致偏差积分根本不能求),权值修正很差。
2.归一化将有单位的量纲转换成无量纲的了,便于BP网络的计算。
3.使网络快速的收敛。
尽量的使尽可能多的输入样本归一化,不完全归一化也能实现效果。
归一化方法:
(测量值—最低标度)/(最大标度—最低标度)等(就是求占得百分比)
可能陷入局部最优解:
前面针对反向学习算法的二次性能修正函数已经做过介绍,表现出来最明显的现象就是,在神经网络训练过程中,由于初始化权值的随机,可能一开始就走偏了,一直无法满足偏差最小情况。学习时间很长还没有出结果,可能就是陷入了局部凹坑。需要重新初始化BP神经网络。
它就是个黑盒子:
神经网络是经过不断的训练数据,不断的调整连接权值。就像是在不断的总结经验,给它一系列输入,对应得到一系列输出。一直在模仿,就如熟能生巧样,仿佛它自己找到了事物的规律。就如中医一样,有很多前人的经验,有些确实有很好的疗效,甚至凭多年的经验,自己能够抓药配药。但一直没有强有力的科学理论依据,所以充满未知(细思极恐),稳定性也得不到保证。
对数据要求较高:
计算机只能处理计算机语言,所以需要处理现实中的问题,就需要转换为计算机能处理的数据,图片就需要转换为二进制编码,但二进制编码也包含了广泛的内容(颜色编码,方位编码,明亮编码),如瓶子装水一般,有清水、污水、酸性、碱性等性质不同。当你训练神经网络时用的是什么特征的数据,那么测试时就也该在这个特征范围内。(装清水的瓶就该只装清水)
拿Google识别图片来说,训练时是未经处理的图片,直接将图片的二进制存储信息等交由计算机处理就行。而如果人为的加入干扰,人眼直接可辨识出物体名称,而Google识图却出错了(如今已修复大部分问题)。具体操作可参考以下网页内容:
阿里的数字水印
http://blog.jobbole.com/105968/
在图片中加入噪点就能骗过 Google 最顶尖的图像识别 AI
http://www.oschina.net/news/84329/noise-can-fool-google-ai
以上,是我学习BP神经网络中的一些总结,能力有限难免有纰漏之处。
转载请注明出处