集群中的每个节点都可以分配多个角色:master、data、ingest、ml(机器学习)等。 我们在当前讨论中感兴趣的角色之一是 master 角色。 在 Elasticsearch 的配置中,我们可以配置一个节点为 master 节点。master 角色的分配表明该节点是具有当选主节点资格的节点(master-eligible)。 在讨论主节点资格之前,让我们了解主节点的重要性。更多关于节点描述的内容,可以参考之前的文章 “Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica”。
Master node
Master node,也即主节点。主节点负责集群范围内的操作,例如为节点分配分片、索引管理和其他轻量级操作。 主节点是一个关键组件,负责保持集群健康。 它努力保持集群和节点社区的状态完好无损。 一个集群只有一个主节点,其唯一的工作就是负责集群的操作 —— 仅此而已。
Master-eligible 节点是一组被标记为 master 角色的节点。 为节点分配 master 节点角色并不意味着该节点成为集群主节点,但如果选出的主节点崩溃,则离成为集群主节点更近了一步。 请记住,如果有机会,其他符合主节点资格的节点也有可能成为主节点,因此它们也离成为主节点更近了一步。
你可能会问,符合主节点资格的节点有什么用! 每个符合主节点资格的节点都会行使投票权来选择集群的主节点。 在幕后,当我们第一次启动节点以形成集群或主节点死亡时,首先采取的步骤之一就是选举一个主节点。 让我们在下一节中了解有关主集群选举的所有信息。
主节点选举
主集群是通过选举民主选出的! 当集群第一次形成或当前主节点死亡时,将举行一次选举以选择一个主节点。 作为选举的一部分,所有符合主节点资格的节点都会选择其中一个作为主节点。 然后,如果 master 由于某种原因崩溃,任何符合 master 资格的节点都会要求进行选举。 成员投票选举新的主人。一旦被选中,主节点将接管集群管理的职责。
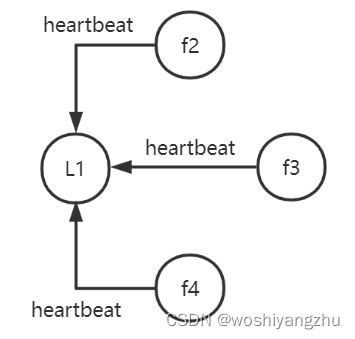
并非所有的日子都是快乐的日子; — 在一些无法控制的情况下,主节点可能被干掉。 因此,符合主节点资格的节点会不断与主节点通信以确保其处于活动状态,并通知主节点自己的状态。 当 master 节点不在后,节点们迫在眉睫的工作就是发起选举,选出新的 master。
有一些属性,例如 cluster.election.duration 和 cluster.election.initial_timeout,可以帮助我们配置选举频率以及在符合主节点资格的节点要求选举之前等待多长时间。 例如,initial_timeout 属性是符合主节点资格的节点在请求选举之前等待的时间。 默认情况下,此值设置为 500 毫秒。 例如,假设符合主节点条件的节点 A 在 500 毫秒内没有从主节点接收到心跳。 然后它要求进行选举,因为它认为 master 已经不在了。
除了选举主节点之外,符合主节点资格的节点还必须协同工作才能使集群运行顺利进行。 然而,虽然 master 是集群的 “王”,但它需要得到其他符合 master 资格的节点的支持和支持。 master 的作用是维护和管理集群状态,所以让我们在下一节中看一下。
集群状态 - Cluster state
集群状态包含有关分片、副本、模式、映射、字段信息等的所有元数据。 这些详细信息作为全局状态存储在集群中,并写入每个节点。 主节点是唯一可以提交集群状态的节点。 它有更多的责任来维护集群的最新信息。 主节点分阶段提交集群数据(类似于分布式架构中的两阶段提交事务):
- 主节点计算集群变化并将它们发布到各个节点,然后等待确认。
- 每个节点都会收到集群更新,但它们尚未应用于其本地状态。 收到后,他们将确认发回给主节点。
- 当从符合主节点资格的节点接收到一定数量的确认时(主节点不需要等待来自每个节点的确认,只需等待符合主节点资格的节点),主节点提交更改以更新集群状态。
- 主节点在成功提交集群更改后,向各个节点广播最终消息,指示它们提交先前收到的集群更改。
- 各个节点提交集群更新。
cluster.publish.timeout 属性设置了一个时间限制(默认为 30 秒),以成功提交每批集群更新。 此期间从向节点发布第一个集群更新消息的时间开始,直到提交集群状态。 如果全局集群更新在默认的 30 秒内成功提交,则 master 会等到这段时间过去,然后再开始下一批集群更新。 然而,故事并没有就此结束!
如果在给定的 30 秒内未提交集群更新,则可能是主节点已死亡。 在这种情况下,当前的 master 拒绝集群更新并辞去 master 的职位。 新主节点的选举因此开始。
尽管全局集群更新已提交,但 master 仍在等待那些尚未发回确认的节点。 除非收到确认,否则 master 无法将此集群更新标记为成功。 在这种情况下,master 会跟踪这些节点并等待 90 秒的宽限期,该宽限期由 cluster.follower_lag.timeout 属性设置,默认为 90 秒。 如果节点在这 90 秒的宽限期内没有响应,它们将被标记为故障节点,结果,主节点将它们从集群中移除。
正如你现在可能已经了解到的那样,Elasticsearch 的幕后发生了很多事情。 集群更新频繁发生,而 master 有大量责任维护移动部件。 在前面的集群更新场景中,master 在继续提交状态之前等待来自一组称为 quorum 的 master-eligible 节点的确认,而不是等待其余节点。 quorum 是 master 有效运行所需的最少 master 节点数,这将在下面来详细描述。
Quorum - 法定节点数
主节点负责维护和管理集群。 但是,它会咨询符合主节点资格的法定节点数以进行集群状态更新和主节点选举。 法定节点数是主节点有效操作集群所需的主节点合格节点的精心选择的子集。 这是主节点将咨询的大多数节点,以便在集群状态和其他问题上达成共识。
虽然我们正在了解法定节点数,但好消息是我们(用户/管理员)不必担心如何形成法定节点数。 集群根据可用的符合主节点资格的节点自动制定法定节点数。 给定一组符合主节点条件的节点,有一个简单的公式可以找到所需的最小主节点数(法定节点数):
Minimum number of master nodes = (number of master-eligible nodes / 2) + 1假设我们有一个 20 节点的集群,我们有 8 个节点被分配为符合主节点条件的节点(节点角色设置为主节点)。 通过应用这个公式,我们的集群创建了一个具有(精心选择的)5 个符合主节点资格的节点 (8 / 2 + 1 = 5) 的法定节点数。 这个想法是我们需要至少 5 个合格的主节点来形成一个法定节点数。
经验法则是,任何节点集群中推荐的最少 master-eligible 成员为三个。 至少设置三个主节点是管理集群的必经之路。 在集群法定人数中拥有至少三个节点的另一大优势是这可以缓解裂脑问题,这将在下一节中讨论。
脑裂 - Split brain
Elasticsearch 的集群健康状况严重依赖于多种因素:网络、内存、JVM 垃圾回收等。 在某些情况下,集群会被分成两个集群:一个集群中有几个节点,另一个集群中有一些节点。 例如,请看下图:
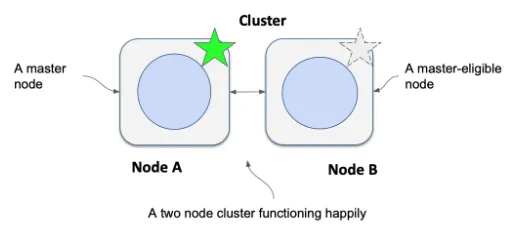
正如你在图中看到的,我们有一个集群,其中有两个符合主节点资格的节点,但其中一个(节点 A)被选为主节点。 只要我们处于快乐的一天状态,集群就是健康的,主节点尽职尽责。
让我们在工作中有所作为。 假设节点 B 由于硬件问题而停止运行。 因为节点 A 是主节点,它会继续使用手头的一个节点为查询提供服务:我们实际上拥有一个单节点集群,同时我们等待另一个节点 B 启动以加入集群。
这就是它可能变得棘手的地方。 在启动时,假设网络连接严重,使得节点 B 无法看到节点 A 的存在。这导致节点 B 承担主角色,因为它认为集群中没有主节点,即使节点 A 作为主节点存在. 这会导致如下图所示的裂脑情况:
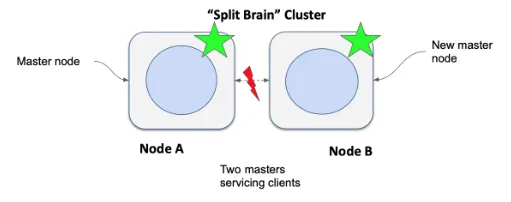
因为两个节点由于网络问题没有通信,所以它们仍然愉快地工作,成为集群的一部分。 因为两个节点都是主节点,所以任何到达其中任何一个的请求都只能由接收节点执行。 然而,一个节点中的数据对另一个节点不可见,这会导致数据差异。 这就是为什么我们应该在一个集群中至少有三个符合主节点资格的节点的原因之一。 拥有三个节点可以完全避免脑裂集群的形成。
专用主节点
因为可以为一个节点分配多个角色,所以看到一个包含 20 个节点的集群,其中所有节点都执行所有角色并不奇怪。 创建这种类型的集群架构没有坏处; 但是,这种类型的设置仅适用于轻量级集群需求。 正如我们已经了解到的,主节点是集群中的关键节点,它使集群保持运转。
如果预计数据将以指数增长速度被索引或搜索,则包括主节点在内的每个节点都会受到性能影响。 一个性能缓慢的主节点是在自找麻烦:集群运行速度变慢甚至停滞。 因此,始终建议创建一台专用机器来托管主节点。 拥有专用的主节点可以让集群平稳运行并减少数据丢失和应用程序停机时间。
如前所述,经验法则是至少在一个集群中拥有三个专用的符合主节点条件的节点。 形成集群时,请确保将 node.roles 设置为 master,如以下代码片段所示,以创建节点专用的主节点。 这样,专用主角色就不会超载来执行数据或摄取相关操作,而只是全职管理集群。
node.roles: [ master ]