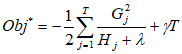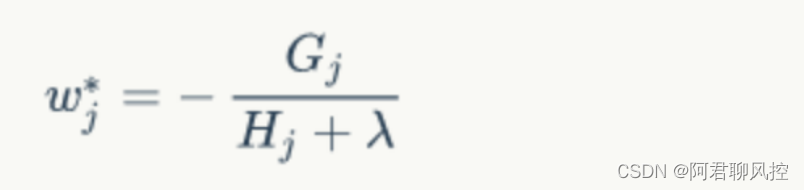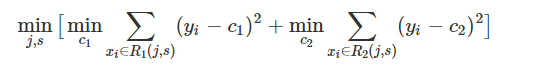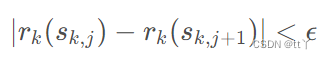想问:在CSDN如何编辑数学公式呢?
XGBoost算法是由GBDT算法演变出来的,GBDT算法在求解最优化问题的时候应用了一阶导技术,而XGBoost则使用损失函数的一阶导和二阶导,不但如此,
还可以自己定义损失函数,自己定义损失函数前提是损失函数可一阶导和二阶导。
XGBoost算法原理:(务必保证先学习决策树算法)
其实算法的原理就是在一颗决策树的基础上不断地加树,比如在n-1颗树地基础上加一棵树变成n颗树的同时算法的精确率不断提高、效果提升。
基础理解:
-
损失函数: l(yi,yi^) = (yi-yi^)**2 【这里损失函数先以方差损失作为示例、因为比较好算和符号表达毕竟这个也很不错;当然损失函数可以更改】
-
如何最优化的求解? : F*(x) = argmin E(x,y)(L(y,F(x)))
-
最终,集成算法的表示:yi^ = sum(fk(xi)) ; 其中,k=1~K;fk属于F
-
yi0^ = 0
-
yi1^ = f1(xi) = yi0^+f1(xi)
-
yi2^ = f1(xi)+f2(xi) = yi1^+f2(xi)
-
…
-
yin^ = sum(fk(xi)) = yi{n-1}^ + fn(xi) ;其中,k=1~n。
推导过程:
-
在样本中着手计算,样本的真实值yi,预测值yi^。
-
目标: Obj{t} = sum(l(yi,yi^{t-1}+ft(xi)))+U(ft)+c 其中、c为常数,i=1~n, U(ft)为L2正则化的惩罚函数
(说白了就是L2正则项:qT+lambad* 1/2* sum(wj**2);其中j=1~T;qT是某个常数,T为叶子节点个数) -
知识补充:
- 泰勒展开: f(x+▲x) ~ f(x)+▲x* f(x)的一阶导 + ▲x*f(x)的二阶导
- 定义:gi = G{y{t-1}^}* l(yi,y{t-1}^); hi = H{y{t-1}^}**2 * l(yi,y{t-1}^) ; gi是一阶导、hi是二阶导。
-
所以,目标函数变换得到:Obj{t} ~ sum(l(yi,yi{t-1}^)+gi* ft{xi}+1/2* hi* ft(xi)**2) ;其中,i=1~n。其实l(yi,yi{t-1}^)相当于一个常数值,因为它从未改变,收敛于某个具体的常数。
-
再次变换:得到Obj{t} ~ sum(gi* ft(xi)+1/2* hi* ft(xi)**2)+U(ft) ;其中,i=1~n。
-
将样本上的遍历计算转换为在叶子节点上的遍历计算: Obj{t} = sum((sum(gi,i属于Ij)* wj+1/2*(sum(hi,i属于Ij)+lambad)* wj**2))+qT,其中,j=1~T。
-
最终目标函数简化为: Obj{t} = sum(Gj* wj+1/2*(Hj+lambad)* wj**2) + qT;其中Gj=sum(gi,i属于Ij),Hj=sum(hi,i属于Ij)。
-
求解最终的目标函数:一贯操作:求偏导、令偏导为0、代入原函数;
- J(ft)对wj求偏导 = Gj+(Hj+lambad)* wj=0
- wj = -(Gj/Hj+lambad)
- 将wj带回原Obj{t}最终目标函数得到:Obj = -1/2* sum(Gj**2/(Hj+lambad),j=1~T)+qT; 代入数据计算得出的分数越小代表这个树的结构越好,也就是损失值越小越好。
-
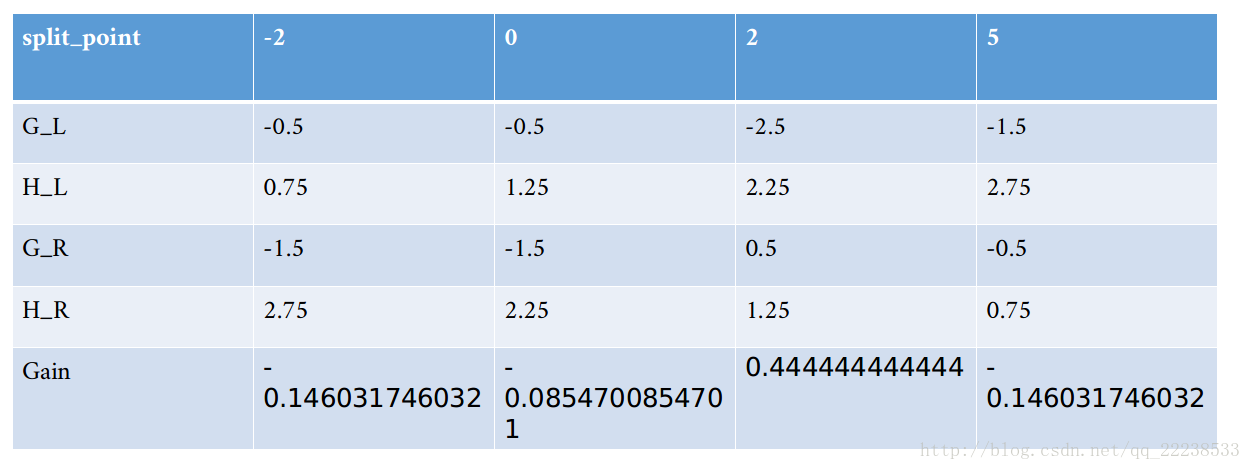
加入新节点的时候的模型复杂度代价:Gain = 1/2*(G{L}**2/(H{L}+lambad)+G{R}**2/(H{R}+lambad)-(G{L}+G{R})**2/(H{L}+H{R}+lambad))-q
XGBoost的思路总结:1.根据数据集初始化一棵树;2.确定损失函数;3.拿出一棵树来作为推导“样本上的遍历计算”这个过程,然后通过函数变换得到“叶子节点上的遍历计算”这个过程,之后求解模型。4.还可以根据计算得到的模型复杂度设置复杂度阈值、毕竟计算资源的代价太大的话也不是很好。
使用wl包安装xgboost之后,使用import引入即可使用
-
其中、xgboost模块的XGBClassifier类是解决分类问题、XGBRegressor类是解决回归问题。
-
xgboost.XGBClassifier(max_depth=3,learning_rate=0.1,n_estimators=100,silent=True,objective=‘binary:logistic’,booster=‘gbtree’,n_jobs=1,
nthread=None,gamma=0,min_child_weight=1,max_delta_step=0,subsample=1,colsample_bytree=1,colsample_bylevel=1,reg_alpha=0,
reg_lambda=1,scale_pos_weight=1,base_score=0.5,random_state=0,seed=None,missing=None) -
xgboost.XGBRegressor(max_depth=3,learning_rate=0.1,n_estimators=100,silent=True,objective=‘binary:linear’,booster=‘gbtree’,n_jobs=1, nthread=None,gamma=0,min_child_weight=1,max_delta_step=0,subsample=1,colsample_bytree=1,colsample_bylevel=1,reg_alpha=0,reg_lambda=1,
scale_pos_weight=1,base_score=0.5,random_state=0,seed=None,missing=None)
参数解释:
- max_depth用于指定每个基础模型所包含的最大深度、默认为3层。
- learning_rate 用于指定模型迭代的学习率(步长)、默认为0.1;【与前面的提升树模型、梯度提升树模型含义相同】
- n_estimators 用于指定基础模型的数量、默认为100个。
- silent:bool类型参数,是否输出算法运行过程中的日志信息,默认为True。
- objective用于指定目标函数中的损失函数类型,1.对于分类类型的XGBoost算法、默认损失函数为二分类的Logistic损失(模型返回概率值)函数,也可以是’multi:softmax’表示处理多分类的损失函数(模型返回类别值)、还可以是’multi:softprob’处理多分类(模型返回各类别对应的概率值)。 2.对于预测型的XGBoost算法,默认损失函数为线性回归损失’binary:linear’。
- booster:用于指定基础模型的类型,默认为’gbtree’,即CART模型,也可以是’gblinear’表示基础模型为线性模型。
- nthread:用于指定XGBoost算法在运行时所使用的线程数、默认为None表示计算机最大可能的线程数。
- gamma:用于指定节点分割所需的最小损失函数下降值,即增益值Gain的阈值,默认为0.
- min_child_weight : 用于指定叶子节点中各样本点二阶导之和的最小值,即Hj的最小值,默认为1,该参数的值越小模型越容易过拟合,
- max_delta_step:用于指定模型在更新过程中的步长,如果为0表示没有约束;如果取值为某个较小的正数就会导致模型更加保守。
- subsample:用于指定构建基础模型所使用的抽样比例,默认为1,表示使用原始数据构建每一个基础模型;当抽样比例小于1时,表示构建随机梯度提升树模型,通常会导致模型的方差降低、偏差提高。
- colsample_bytree:用于指定每个基础模型所需要的采样字段比例,默认为1表示使用原始数据的所有字段。
- colsample_bylevel:用于指定每个基础模型在节点分割时所需的采样字段比例,默认为1表示使用原始数据的所有字段。
- reg_alpha:用于指定L1正则项的系数、默认为0。
- reg_lambda:用于指定L2正则项的系数、默认为1。
- scale_pos_weight:当各类别样本的比例十分不平衡时,通过设定该参数为一个正值可以使算法更快收敛。
- base_score:用于指定所有样本的初始化预测得分,默认为0.5。
- random_state:默认为0表示使用默认的随机数生成器。
- seed:与random_state相同。
- missing:用于指定缺失值的表示方法,默认为None,即NaN为默认值。
XGBoost实战案例
- 数据集:信用卡欺诈数据集、来源于kaggle网站。
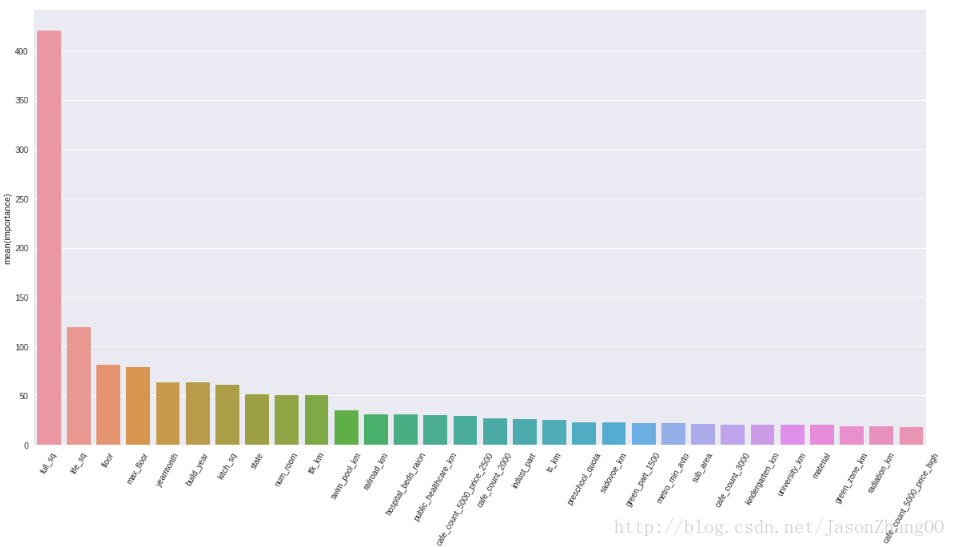
- 包含25个变量、284807条记录,因变量为class表示用户在交易中是否发生欺诈行为(0表示不欺诈、1表示欺诈)
- 由于数据涉及敏感信息、文件中已经做好了主成分分析(PCA)处理。
读取数据:
import pandas as pdcreditcard = pd.read_csv(r'creditcard.csv')
creditcard.head(5)
查看各类别的标签比例:
#探索查看各类别的比例差异
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 为确保绘制的饼图为圆形,需执行如下代码
plt.axes(aspect = 'equal')
# 统计交易是否为欺诈的频数
counts = creditcard.Class.value_counts()
# 绘制饼图
plt.pie(x = counts, # 绘图数据labels=pd.Series(counts.index).map({0:'正常',1:'欺诈'}), # 添加文字标签autopct='%.2f%%' # 设置百分比的格式,这里保留一位小数)
# 显示图形
plt.show()
在28w条交易数据中、欺诈交易仅占0.17%,两个类别的比例存在严重的不平衡。
如果直接建模则模型的准确率会偏向多数类别的样本,而正确预测交易为欺诈的概率几乎为0.所以,需要使用SMOTE算法转换为相对平衡的数据:
from sklearn import model_selection# 将数据拆分为训练集和测试集
# 删除自变量中的Time变量
X = creditcard.drop(['Time','Class'], axis = 1)
y = creditcard.Class
# 数据拆分
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,y,test_size = 0.3, random_state = 1234)from imblearn.over_sampling import SMOTE# 运用SMOTE算法实现训练数据集的平衡
over_samples = SMOTE(random_state=1234)
over_samples_X,over_samples_y = over_samples.fit_sample(X_train, y_train)
#over_samples_X, over_samples_y = over_samples.fit_sample(X_train.values,y_train.values.ravel())# 重抽样前的类别比例
print(y_train.value_counts()/len(y_train))
# 重抽样后的类别比例
print('')
print(pd.Series(over_samples_y).value_counts()/len(over_samples_y))
使用默认参数直接建模:(也可以进行交叉验证以及其它方式找出最优参数,但我的目的是想看一下处理非平衡数据以及不处理非平衡数据会是怎么样的一种对比)
from sklearn import metrics
import xgboost
import numpy as np# 构建XGBoost分类器
xgboost = xgboost.XGBClassifier()
# 使用重抽样后的数据,对其建模
xgboost.fit(over_samples_X,over_samples_y)
# 将模型运用到测试数据集中
resample_pred = xgboost.predict(np.array(X_test)) #传入的是array# 返回模型的预测效果
print('模型的准确率为:\n',metrics.accuracy_score(y_test, resample_pred))
print('模型的评估报告:\n',metrics.classification_report(y_test, resample_pred))
计算欺诈交易的概率值,用于生成ROC曲线的数据:
y_score = xgboost.predict_proba(np.array(X_test))[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
利用不平衡数据建模进行对比一下
# 构建XGBoost分类器
import xgboost
xgboost2 = xgboost.XGBClassifier()
# 使用非平衡的训练数据集拟合模型
xgboost2.fit(X_train,y_train)
# 基于拟合的模型对测试数据集进行预测
pred2 = xgboost2.predict(X_test)
# 混淆矩阵
pd.crosstab(pred2,y_test)
# 返回模型的预测效果
print('模型的准确率为:\n',metrics.accuracy_score(y_test, pred2))
print('模型的评估报告:\n',metrics.classification_report(y_test, pred2))
计算欺诈交易的概率值,用于生成ROC曲线的数据:
y_score = xgboost2.predict_proba(X_test)[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
AUC值一个是0.98,一个是0.97,虽然处理非平衡数据过后只是提升了0.01,但是也算是得到了优化。
希望大家能多多给予意见和建议。谢谢。
欢迎加入QQ群一起学习和交流,只为学习和交流:275259334
或者直接扫码加入: