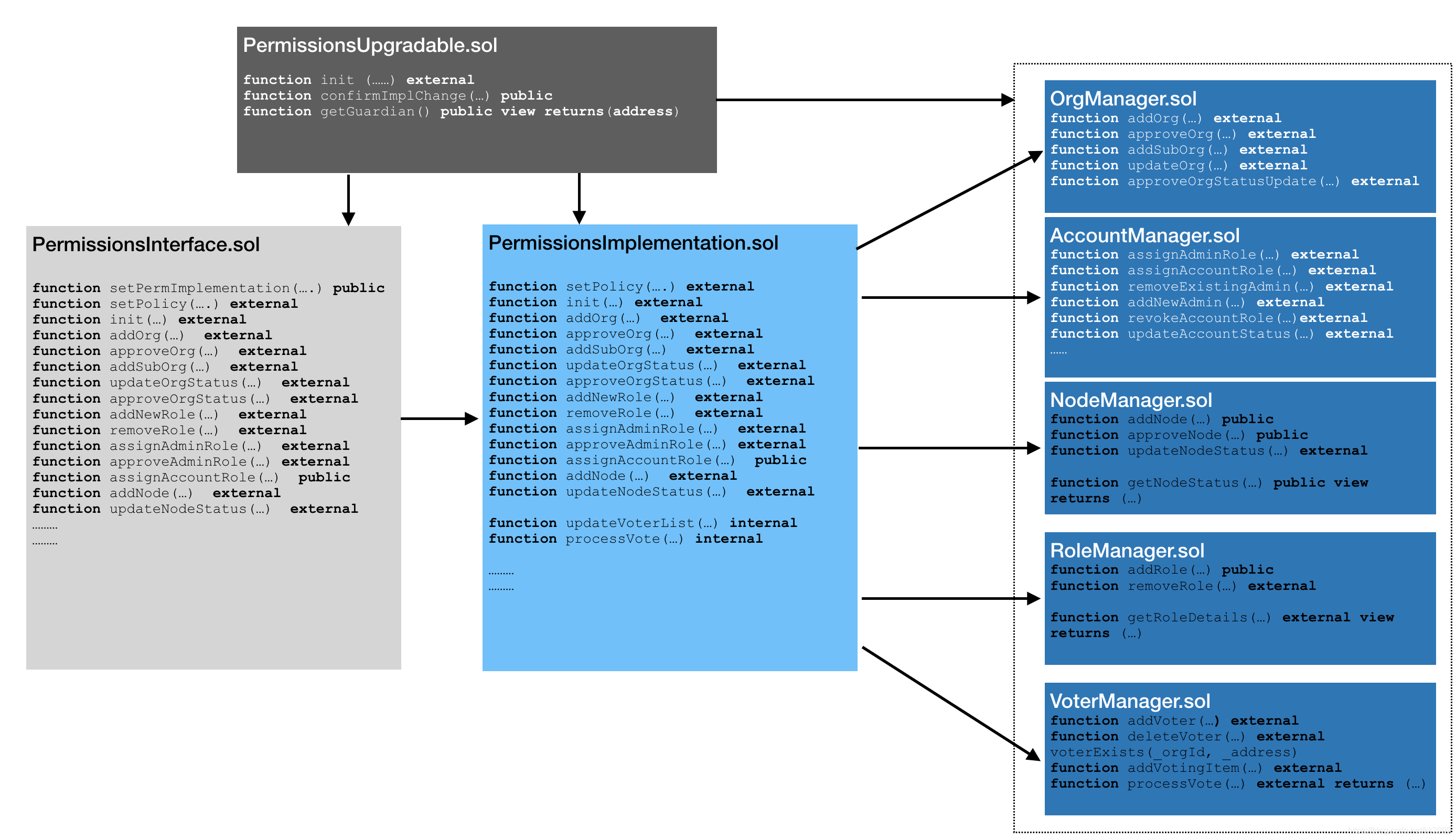
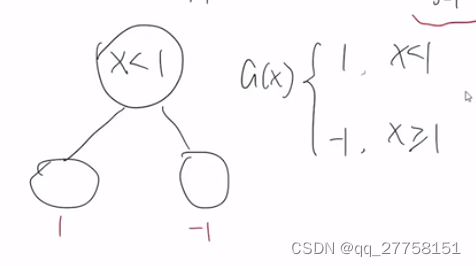注:
这里谈论的2PC不同于事务中的2PC,而是专门为了同步和高可用改过的2PC协议
问题:
寻求一种能够保证,在给定多台计算机,并且他们之间由网络相互连通,中间的数据没有拜占庭将军问题(数据不会被伪造)的前提下,能够做到以下两个特性的方法:
1)数据每次成功的写入,数据不会丢失,并且按照写入的顺序排列
2)给定安全级别,保证服务可用性,并尽可能减少机器的消耗
基础场景:
假定有两个人,李雷和韩梅梅,李雷让韩梅梅去把隔壁班的电灯关掉,这时候,韩梅梅可能有以下三种反馈:
1)“好了,关了”(成功)
2)“开关坏了,没法关”(失败)
3)(因为网络原因,无反馈)
两阶段提交
假如我有两台机器A和B,A是Coordinator(协调者),B是Cohorts(同伴,支持者) 
A将某个事件通知给B,B会有以下几种反馈:
1.成功
2.失败,比如硬盘满了?不符合某些条件?为了解决这个情况,所以我们必须让A多一个步骤:准备,准备意味着如果B失败,那么A也自然不应该继续进行,应该将A的所有已经做得修改回滚,然后通知客户端:错误啦。
因此,我们为了能做到能够让A应付B失败的这个情况,需要将同步协议设计为:
PrepareA -> CommitB -> Commit A
使用这个协议,就可以保证B就算出现了某些异常情况,数据还能够回滚
我们再看一些异常情况:
PA->CB(B机器挂掉):在CommitB失败,回滚PrepareA
PA->CB->CA(A机器挂掉):CommitA失败,在A这个机器重新恢复后,因为自己的状态是PA,所以它必须询问B机器,你提交了没有?如果B回答提交成功,那么A也必须将自己的数据进行提交,以达到一致。
其实,我们排除了一种最恶心的情况,这就是网络上最臭名昭著的问题,无反馈
无反馈这个情况,在2PC中只会在一个地方出现,因为只有一次网络传输过程:A把自己的状态设置为prepare,然后传递消息给B机器,让B机器做提交操作,然后B反馈A结果
那么,这无反馈意味着什么呢?
1.B成功提交
2.B失败
3.网络断开
以A机器的角度来看,有两类事情无法区分出来:
1)B机器是挂掉了呢?还是网络断掉了?
2)要求B做的操作,是成功了呢?还是失败了呢?
在无反馈的情况下,无法区分是成功了还是失败了,于是最安全和保险的方式就是等…等到B给个反馈,这种在可用性上基本上是0分了;A得不到B的反馈,又为了保证自己的可用性,唯一的选择就是:等待一段时间,超时以后,认为B机器挂掉了,于是自己继续接收新的请求,而不再尝试同步给B。
然而,这个选择会带来更大的问题,左脑和右脑被分开了。我们假定A所在的机房有一组clientA,B机房有一组clientB。开始时,A是master:
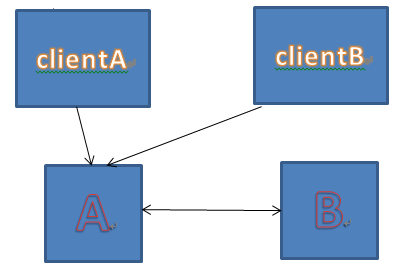
一旦发生断网: 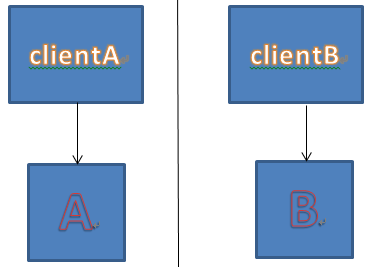
在这种情况下,A无法给B传递信息,为了可用性,只好认为B挂掉了。允许所有clientA提交请求到自己,不再尝试同步给B。而B与A的心跳也因为断网而中断,他也无法知道,A到底是挂掉了呢?还是只是网断了,但为了可用性,只好也把自己设置为主机,允许所有clientB写入数据。于是,出现了两个master。
两阶段提交解决了什么问题,以及存在什么问题?
两阶段提交协议是实现分布式事务的关键;存在的问题是针对无反馈的情况,除了“死等”,缺乏合理的解决方案。
针对“死等”问题,有人提出了三阶段提交协议,增加一段来减少死等的情况。不过3PC基本上没有人在用,因为有其他协议可以做到更多的特性的同时又解决了死等的问题。同时3PC是无法解决脑裂问题的。
针对脑裂,最简单的解决方法是:引入第三视点,Observer.如果问到无反馈时,就去询问Observer. 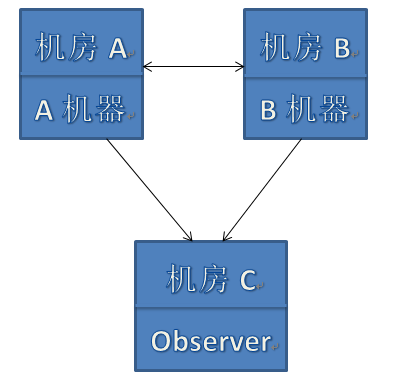
3PC标准协议是canCommit/preCommit/doCommit三个阶段,2PC是preCommit和doCommit两个阶段,Paxos算是比较典型的2PC,在preCommit阶段voting
3PC之于2PC的差异在于多了第一次canCommit通讯,使得Coordinator和Cohorts能够按照约定在相应阶段的timeout时做出准确的操作,而避免了2PC改中coordinator在超时发生时不知所措的窘态
统一思想,做出统一决策–解决脑裂问题->Paxos算法
思路:信使就是消息传递,也就是通过网络将消息传递给其他人的机制;通过parliament(议会)做出决议,基于“少数服从多数”
假设有两个机房,A机房和B机房,A机房有5台机器,B机房有3台机器,他们的网络被物理隔离了,我们来看看有哪些选择:
1.A,B机房独立的都可以提供服务。
这种方式明显是不靠谱的,会出现不可逆转的不一致问题。
2.A,B机房都不可以提供服务
合理的方式,但在高可用上是0分,只保持了一致性而已
3.让B机房的机器服务
好吧,你真的认为剩下三台机器提供服务的安全性比5台高
4.让A机房的机器服务
“民主并不是什么好东西,但它是我们迄今为止所能找到的最不坏的一种”
这就是quorum产生的核心原因
Paxos
当机器变得更多的时候Observer不能只有一个,必须有更多个Observer,但Observer多了,到底听谁的又成了问题。这时候,我们就需要“少数服从多数”。这就是quorum模型。
我们假定有A,B,C,D,E五台机器,KV系统需要put一个数据[key=Whisper,val=3306]到我们这5台机器上,要保证只要反馈为真,任意两台机器挂掉都不会丢失数据,并且保证高可用。怎么做:
1.首先,客户端随机选择一个结点,进行写入提交,这里我们随机选择了C这个结点,这时候C结点就是这次提议的发起人(也叫proposer,在老的2pc协议里也叫coodinator),当C收到这个提议的时候,C首先要做的事情是根据当前结点的最新全局global id,做一次自增操作。我们假定,在当时的全局global id为0,所以,这个议案就被对应了一个编号:1–>[key=Whisper,val=3306].
这里有两个我们经常犯的错误:
1)global id问题,在老的论文里,Lamport没有描述这个自增id是怎么生成的。从我目前能够看到的所有实现里面,基本上就是选择哪一台机器,就是以那台机器当前所保持的全局id(可能不是全局来看的最高值),然后做一下自增就行了。我们后面会看到协议如何保证非全局最高值的globalID提议会被拒绝以至于不能形成决议。
2)golbal id只是对paxos协议有意义,对于数据库,其实只需要关心KeyValue即可,golbal id的作用只是告诉你这些数据的顺序是按照global id来排列的
回到文中,我们已经将这个新的议案标记了从C这台机器看起来最大的global id:1–>[key=Whisper,val=3306].然后,它会尝试将这个信息发送给其余的A,B,D,E这几台机器。
在这个过程中,Paxos将A,B,D,E叫做accepter(老的协议叫做参与者,cohorts),他们的行为模式如下:
如果A,B,D,E这几台机器的globalID小于C给出的决议的GID(1–>[key=Whisper,val=3306]),那么就告诉C,这个决议被批准了。而如果A,B,D,E这几台机器的globalID大于或等于C给出决议的GID,那么就告诉C这个决议不能被批准
我们假定A,B两台机器当时的Max(GID)是0,而D,E的Max(GID)是1。那么,A,B两台机器会反馈给C说协议被接受,这时候,C的议案有3票:A,B,C(算自己的)。所以这个议案有三票,5台机器的半数是3,超过法定人数,于是决议就被同意了。
我们保持这个上下文,来看看D,E这边的情况。首先,要思考的问题是,为什么D,E的Max(GID)是1呢?
其实很简单,D可能在C发起决议的同时,也发起了一个决议,我们假定这个决议是由D发起的,决议是1–>[key=taobao,val=1234].既然D,E的Max(GID)是1,那么意味着E已经告知D,它同意了D的决议,但D马上会发现,A,B,C里面的任意一个都返回了不同意,它的议案只拿到两票,没有通过。
这时候C的决议已经被多数派接受,所以它需要告诉所有人,我的议案1–>[key=Whisper,val=3306]已经被接受,你们去学习吧
这时候还有一个问题是需要被考虑的,如果在C已经达到法定人数,在告知所有人接受之前,C挂了,应该怎么办?
为了解决这个问题,需要要求所有的accepter在接受某个人提出的议案后,额外的记录一个信息:当前accepter接受了哪个提议者的议案。
为什么要记录这个?很简单,我们看一下上面出现这个情况时候的判断标准
A机器:角色accepter,批准的议案1–>[key=Whisper,val=3306],提议人:C
B机器:角色accepter,批准的议案1–>[key=Whisper,val=3306],提议人:C
C机器:角色proposer,挂了
D机器:角色accepter,批准的议案1–>[key=taobao,val=1234],提议人:自己
E机器:角色proposer,“提议的”议案1–>[key=taobao,val=1234],提议人:D
因为有了提议人这个记录,所以在超时后很容易可以判断,议案1–>[key=Whisper,val=3306]是取得了多数派的议案,因为虽然D,E两台机器也是可以达成一致的议案的,但因为有个人本身是提议者,所以可以算出这个议案是少数派。
在这之后,提议者还需要做一件事,就是告诉D,E,被决定的决议已经是什么了。这个过程在文章中叫做Learn。D,E被称为Learner。
这个过程是变数最大的过程,有不少方法可以减少网络传输的量
下面,我们讨论下载2pc/3pc中面临的问题,在paxos里面是怎么被解决的
2pc最主要的问题是死等、脑裂,两个问题。
对于脑裂,paxos给出的解决方案是,少数服从多数,决议发给所有人,尽一切努力送达,总有一个决议会得到多数派肯定,所以,不在纠结于某一台机器的反馈,网络无响应?没有就没有吧,其他人有反馈就行了。
所以,如果出现机房隔离的情况,比如A,B,C在机房1,D,E在机房2,机房1和机房2物理隔离了,那么你会发现,D,E永远也不可能提出能够得到多数派同意的提案。
所以,少数派的利益被牺牲了,换来了多数派的可用性。这是唯一能够既保证数据的一致性,又尽可能提高可用性的唯一方法。
而对于死等问题,解决方法也是一样的,对于某一台机器的无响应,完全不用去管,其他机器有响应就可以了,只要能拿到多数。
那么下面谈谈我对Paxos算法和quorum模型的理解
阶段一:系统只有一个数据结点,不存在数据一致性的问题,但在可用性和可靠性上存在较大的问题,先说可用性,随着系统用户规模(或者说是TPS)的升高,很快就会达到系统瓶颈,延迟增大,响应性急速下降,最终导致系统可用性下降,或不可用。再说可靠性,很明显,数据结点存在单点问题
阶段二:系统有两个数据结点(master-slave模式),提升了系统的可靠性,可以做读写分离,提升系统的可用性,但随着写压力的上升,master很快就会达到瓶颈
阶段三:系统中多个数据结点,没有主次之分,平等关系,这样的分布式系统设计是scalable的,大大的提升了系统的可用性和可靠性,但多个结点数据的一致性问题暴露了出来;但如果要求系统结点的强一致性,那么在数据的同步过程中,系统的可用性就会降低(CAP理论)
而Paxos算法就是为了在分布式系统中的系统可用性和一致性之间寻求一种平衡
Paxos算法是一种基于消息传递的一致性算法(一致性算法有两种实现方式:通过基于锁的共享内存和消息传递),用来解决在分布式系统中的数据一致性问题。
Paxos算法的思想是基于Quorum(法定人数)机制,少数服从多数,对于少数结点的网络异常、宕机、数据不一致,it doesn’t matter,消息尽一切努力送达,数据达到最终一致性
实际案例:
分布式系统中数据存储采用多份数据副本来提供可靠性。当用户提交了一次修改后,那么原先保存的副本显然就和当前数据不一致了。解决这个问题最简单的方案是read only after write all,就是在用户提交修改操作后,系统确保存储的数据所有副本全部完成更新后,再告诉用户操作成功;而读取数据的时候只需要查询其中一个副本数据返回给用户就行了。在很少对存储的数据进行修改的情况下,这种方案很好。但遇到经常需要修改的情形,写操作时延迟就很明显,系统可用性下降。
那么有没有一种方案能够不需要更新完全部数据,但又保证返回给用户的是有效的数据的方案呢?Quorum机制(鸽笼原理)便是其中一种选择,其实质是将write all负载均衡到read only上。
假设共有N个数据副本,其中K个已经更新,N-K个未更新,那么我们任意读取N-K+1个数据的时候就必定至少有一个是属于更新了的K个里面的,也就是quorum的交集,我们只需要比较读取的N-K+1中版本最高的那个数据返回给用户就可以得到最新更新的数据了(满足W+R>N,集群的读写就是强一致的)。
对于写模型,我们只需要完成K个副本的更新后,就可以告诉用户操作完成而不需要write all了,当然告诉用户完成操作后,系统内部还是会慢慢的把剩余的副本更新,这对于用户是透明的。即write上的部分负载转移到了read身上。至于具体转移多少负载比较合适,取决于系统的读写访问比。
那么Paxos有没有什么值得改进的地方?有的,很简单,你会发现,如果在一个决议提议的过程中,其他决议会被否决,否决本身意味着更多的网络io,意味着更多的冲突,这些冲突都是需要额外的开销的,代价很大。
为了解决类似的问题,所有才会有zookeeper对paxos协议的改进。zookeeper的协议叫zab协议
其实,这也是在我们现实生活中经常能够发现的,如果每个议案都要经过议会的讨论和表决,那么这个国家的决策无疑是低效的,怎么解决这个问题呢?弄个总统就行了。zab协议就是本着这个思路来改进paxos协议的
zab协议把整个过程分为两个部分,第一部分叫选总统,第二部分叫进行决议。
选总统的过程比较特殊,这种模式,相对的给人感觉思路来源于lamport的面包房算法,选择的主要依据是:
1.如果有gid最大的机器,那么它就是主机
2.如果好几台主机的gid相同,那么按照序号选择最小的那个
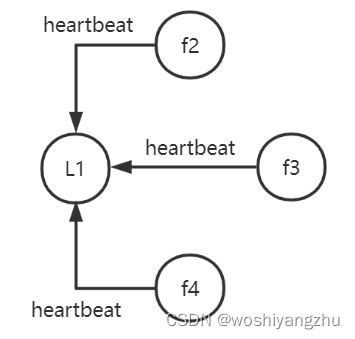
所以,在开始的时候,给A,B,C,D,E进行编号,0,1,2,3,4.第一轮的时候,因为大家的Max(gid)都是0,所以自然而然按照第二个规则,选择A作为主机
然后,所有人都知道A是主机以后,无论谁收到的请求,都直接转发给A,由A机器去做后续的分发,这个分发的过程,叫进行决议。
进行决议的规则就简单很多了,对其他机器进行3pc提交,但与3pc不同的是,因为是群发议案给所有其他机器,所以一个机器无反馈对大局是没有影响的,只有当在一段时间以后,超过半数没有反馈,才是有问题的时候,这时候要做的事情是,重新选择总统。
具体过程是,A会将决议precommit给B,C,D,E。然后等待,当B,C,D,E里面的任意两个返回收到后,就可以进行doCommit()。否则进行doAbort()
为什么要任意两个?原因其实也是一样的,为了防止脑裂,原则上只能大于半数,因为一旦决议成立的投票数少于半数,那么就存在另立中央的可能,两个总统可不是闹着玩的。
定两个,就能够保证,任意“两台”机器挂掉,数据不丢,能够做到quorum.
写zab协议的人否认自己的协议是paxos变种,其实他们是针对一个问题的两种解决方法:
因为他们解决的问题的领域相同
解决网络传输无响应这个问题的方法也一样:也即不在乎一城一池的得失,尽一切努力传递给其他人,然后用少数服从多数的方式,要求网络隔离或自己挂掉的机器,在恢复可用以后,从其他主机那里学习和领会先进经验。
并且也都使用了quorum方式防止脑裂的情况
核心思路是类似的,但解决问题的方法完全是两套。
ps:
活锁,指的是任务或执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试,活锁可以自行解开,可以认为是一种特殊的饥饿。活锁的进程不会block,这会导致耗尽CPU资源。