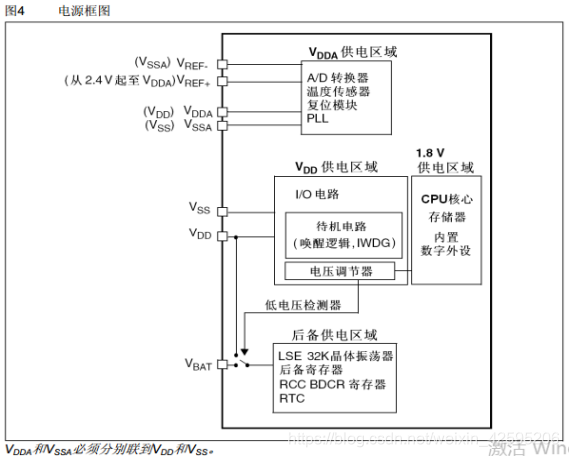
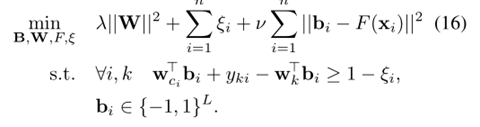今天又是一篇Transformer梳理文章,这次应用场景是时间序列预测。Transformer的序列建模能力,让其天然就比较适合时间序列这种也是序列类型的数据结构。但是,时间序列相比文本序列也有很多特点,例如时间序列具有自相关性或周期性、时间序列的预测经常涉及到周期非常长的序列预测任务等。这些都给Transformer在时间序列预测场景中的应用带来了新的挑战,也使业内出现了一批针对时间序列任务的Transformer改造。下面就给大家介绍7篇Transformer在时间序列预测中的应用。
其他Transformer相关文章推荐:
图学习?Transformer:我也行!
从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程
Transformer提效之路干货笔记——一文梳理各种魔改版本Transformer
1
Autoformer

论文题目:Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting(NIPS 2021)
下载地址:https://arxiv.org/pdf/2106.13008.pdf
Autoformer是Transformer的升级版本,针对时间序列问题的特性对原始Transformer进行了一系列优化。模型的整体结构如下图,核心是Series Decomposition Block模块和对多头注意力机制的升级Auto-Correlation Mechanism。这里推荐想详细了解Autoformer细节的同学参考杰少的这篇文章:当前最强长时序预测模型--Autoformer详解,整理的非常全面深入。下面给大家简单介绍一下Auroformer的各个模块。
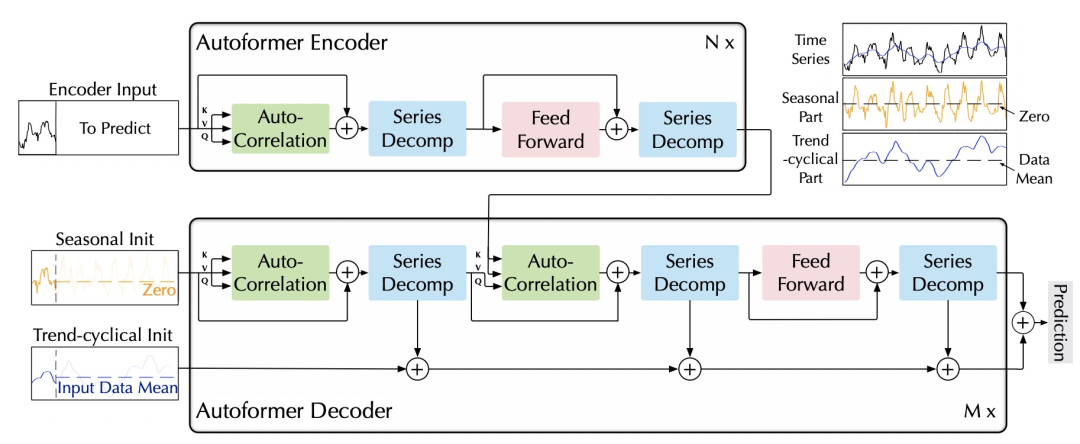
第一个模块是Series Decomposition Block,这个模块主要目的是将时间序列分解成趋势项和季节项。在最基础的时间序列分析领域,一个时间序列可以被视为趋势项、季节项、周期项和噪声。对于这4个因素的拆解,有加法模型、乘法模型等,其中加法模型认为这4个因素相加构成了当前时间序列。本文采用了加法模型,认为时间序列由趋势项+季节项构成。为了提取出季节项,本文采用了滑动平均法,通过在原始输入时间序列上每个窗口计算平均值,得到每个窗口的趋势项,进而得到整个序列的趋势项。同时,根据加法模型,将原始输入序列减去趋势项,即可得到季节项。整个Series Decomposition Block的公式可以表示为:
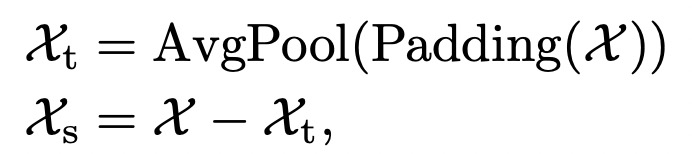
模型的输入结合Series Decomposition Block模块。Encoder部分输入历史时间序列,Decoder部分的输入包括趋势项和季节项两个部分。趋势项由两部分组成,一部分是历史序列经过Series Decomposition Block分解出的趋势项的后半部分,相当于用历史序列近期的趋势项作为Decoder的初始化;趋势项的另一部分是0填充的,即目前尚不知道的未来序列的趋势项,用0进行填充。季节项和趋势项类似,也是由两部分组成,第一部分为Encoder分解出的近期季节项,用于初始化;第二部分为Encoder序列均值作为填充,公式如下。

Encoder部分的主要目的是对复杂的季节项进行建模。通过多层的Series Decomposition Block,不断从原始序列中提取季节项。这个季节项会作为指导Decoder在预测未来时季节项的信息。Encoder部分的公式如下,Auto-correlation代表Auto-Correlation Mechanism,我们在下面再进行介绍。

Decoder部分也是类似的结构,利用Encoder信息和Decoder输入进行预测,公式如下:

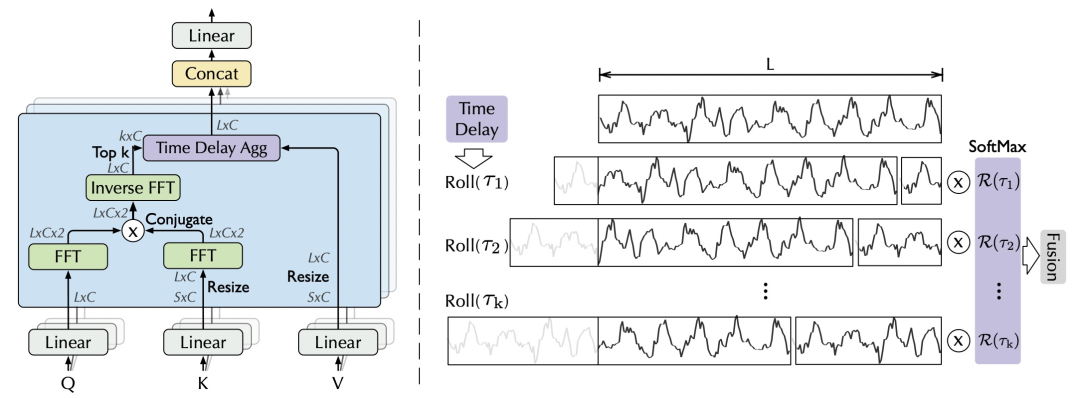
第二个模块是Auto-Correlation Mechanism,是对传统Transformer在时间序列预测场景的升级。Auto-Correlation Mechanism的核心思路是利用时间序列的自相关系数,寻找时间序列最相关的片段。时间序列的自相关系数计算时间序列和其滑动一个步长后的时间序列的相关系数。举例来说,如果一个时间序列是以年为周期,那么序列平移365天后,原序列和平移后的序列相关系数是很高的。AutoFormer利用了这个性质,计算各个滑动步长的自相关系数,并选择相关系数top k的滑动步长。
在具体实现上,Auto-Correlation Mechanism替代了Transformer中的self-attention结构,其公式如下。首先,将输入的时间序列通过全连接映射成Q、K、V,这和multi-head attention相同。接下来,计算Q和K之间各个周期的相关系数,选择相关系数最高的top k,这k个周期代表着Q和K的高相关性周期。这个过程可以理解为计算attention,与以往attention不同的是,这里计算的是片段的相似关系而非点的相似关系。最后,利用softmax得到每个周期归一化的权重,对V的对应周期平移结果进行加权求和。
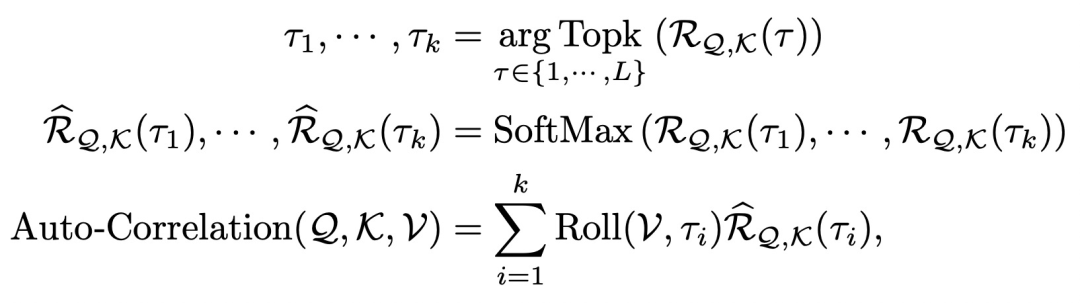
文中使用快速傅里叶变换(FFT)计算自相关系数。下图分别展示了Auto-Correlation Mechanism,以及这种自相关机制相比Transformer中的自注意力机智的区别。自相关机制利用时间序列的平移寻找相似的片段,而自注意力机制关注点之间的关系。
2
Pyraformer

论文题目: Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting(ICLR 2022)
下载地址:https://openreview.net/pdf?id=0EXmFzUn5I
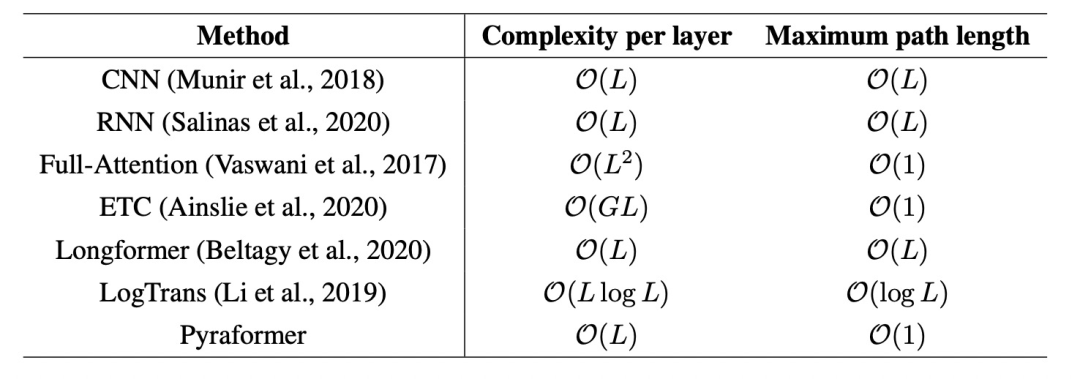
在长周期的时间序列预测问题中,如何平衡运算复杂度以及缩短两个时间点之间的交互距离一直是研究的焦点(如下表为各个模型的运算复杂度及两点最长路径)。RNN、CNN这种模型对于输入长度为L的序列,两个时间点的最长路径为L,在长周期中节点之间信息交互比较困难。而Transformer引入了Attention机制,让两两节点之间可以直接交互,但是提升了时间复杂度。
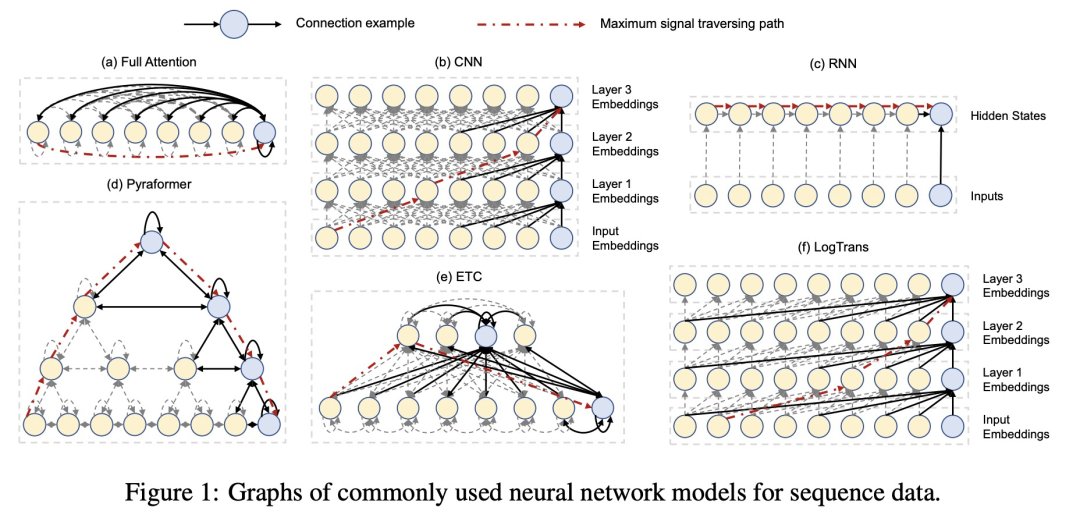
本文提出了一种树形结构的Transformer,用于解决长周期时间序列预测问题。从下到上,时间序列的粒度逐渐变粗。最底层为原始输入的时间序列,上层为使用卷积聚合得到的粗粒度序列。每个节点和3种节点做attention:该节点的子节点、该节点的相邻邻居节点、该节点的父节点。通过这种方式,任何两个节点之间都可以直接交互,并且时间复杂度大幅降低。
在预测时,一种是把经过上述编码得到的表示直接接全连接映射到预测空间。另一种方法是使用一个额外的Decoder,采用类似Transformer中的方式进行解码。
3
Informer

论文题目: Informer: Beyond efficient transformer for long sequence timeseries forecasting(AAAI 2021)
下载地址:https://arxiv.org/pdf/2012.07436.pdf
Informer针对长周期时间序列预测,主要从效率角度对Transformer进行了优化,这篇工作也是AAAI 2021的best paper。对于长周期时间序列,输入的维度很高,而Transformer的时间复杂度随着输入序列长度增加指数增长。为了提升Transformer在长序列上的运行效率,通过让key只和关键query形成稀疏的attention减少大量运算量。作者通过实验方法,attention score具有非常明显的长尾性,少数的score比较大,大多数score很小,因此只要重点建模那些重要的关系即可。如果一个query和其他key的attention score接近均匀分布,那么这个query就是简单的把其他value加和求平均,意义不大。因此Informer中提出计算每个query的attention score打分分布和均匀分布的KL散度,对于重要性不大的query,key就不和这些query计算attention,形成了sparse attention的结构,带来计算效率的大幅提升。
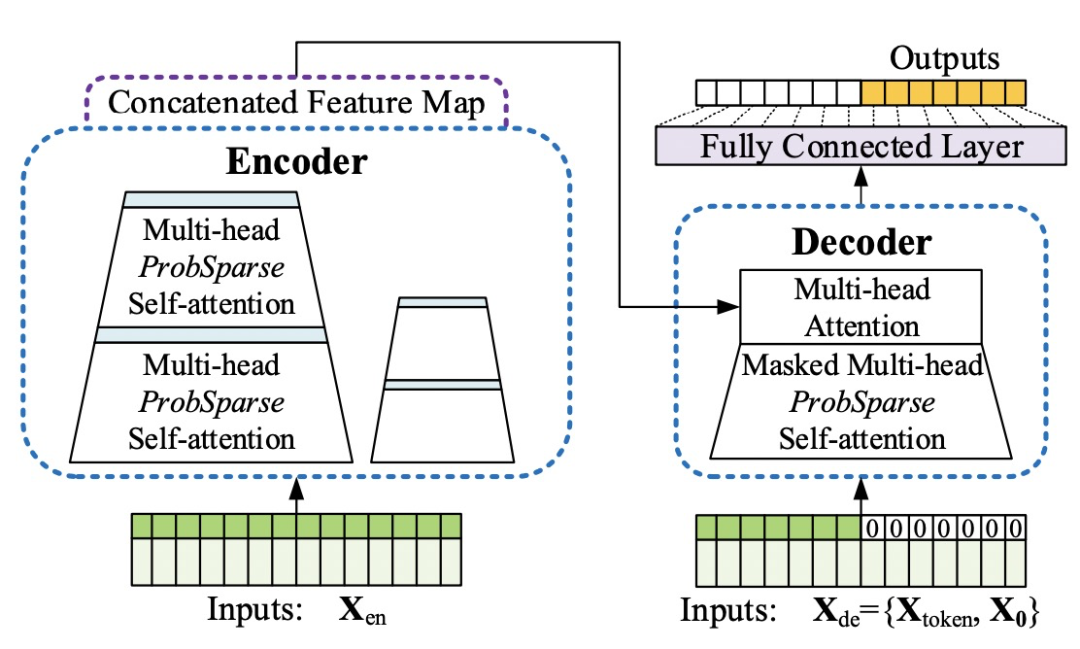
此外,针对时间序列任务,Informer还引入了self-attention distillation,在每两层Transformer之间增加一个卷积,将序列长度缩减一半,进一步减少了训练开销。在Decoder阶段,则采用了一次性预测多个时间步结果的方法,相比传统GPT等autoregressive的方法缓解了累计误差问题。

4
FEDformer

论文题目:FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting(2022)
下载地址:https://arxiv.org/pdf/2201.12740.pdf
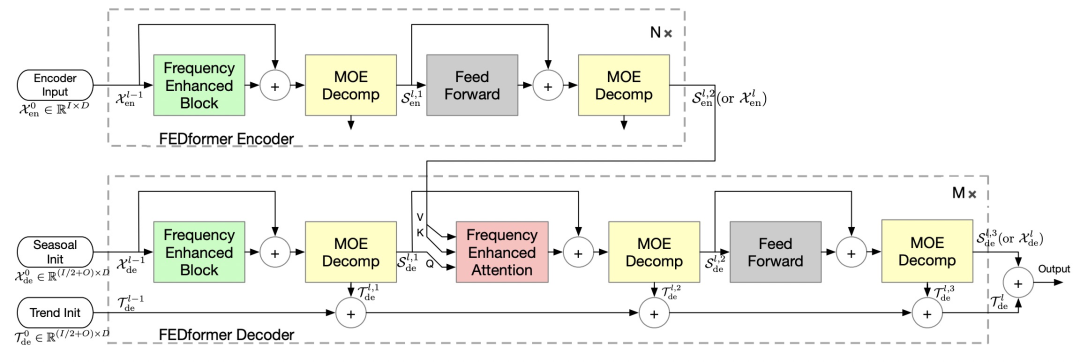
FEDformer的主要思路也是将Transformemr和 seasonal-trend decomposition结合起来。使用普通的Transformer进行时间序列预测时,经常会出现预测的数据分布和真实分布存在比较大的gap。这主要是由于Transformer在进行预测每个时间点是独立的利用attention预测的,这个过程中可能会忽略时间序列整体的属性。为了解决这个问题,本文采用了两种方法,一种是在基础的Transformer中引入 seasonal-trend decomposition,另一种是引入傅里叶变换,在频域使用Transformer,帮助Transformer更好的学习全局信息。
FEDformer的核心模块是傅里叶变换模块和时序分解模块。傅里叶变换模块将输入的时间序列从时域转换到频域,然后将Transformer中的Q、K、V替换成傅里叶变换后的频域信息,在频域中进行Transformer操作。
5
Log-Sparse Transformer

论文题目:Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting(2019)
下载地址:https://arxiv.org/pdf/1907.00235.pdf
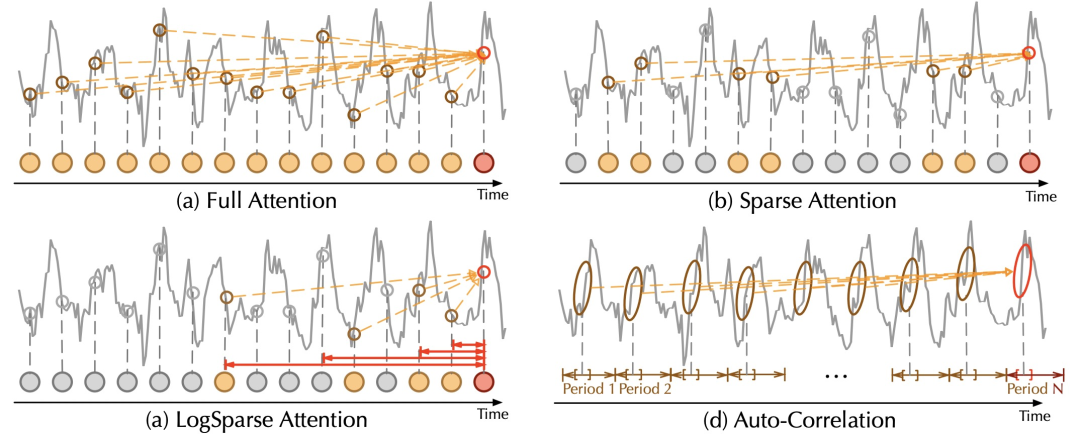
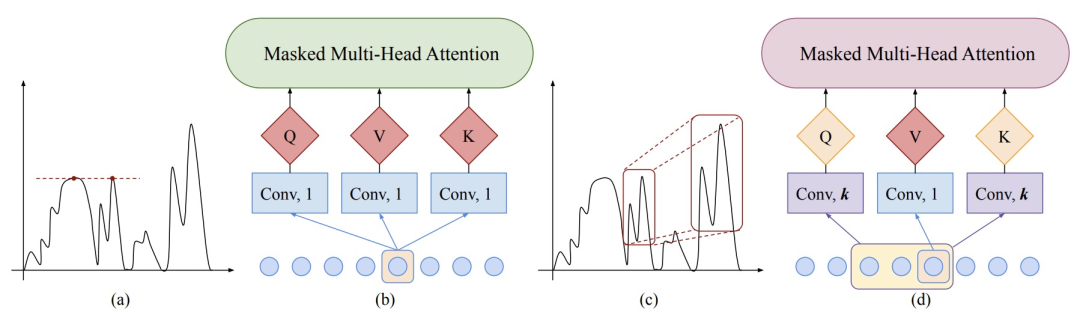
Transformer的Attention操作是点对点的,而时间序列上上下文信息非常重要。例如下图中,左侧虽然两个点时间序列值相同,但是由于周边序列形状差异很大,因此这两个点之间不具有参考价值。而右侧图中,虽然两个区域的时间序列值差别很大,但是整体形状是非常相似的,因此这两个部分具有较大参考价值,应该增加attention权重。从这个例子可以看出,在时间序列问题中,不能只用类似NLP中的两点之间的注意力机制,而应该考虑点周围的上下文信息。
本文采用卷积+Transformer的方式,时间序列会首先输入到一个一维卷积中,利用卷积提取每个节点周围的信息,然后再使用多头注意力机制学习节点之间的关系。这样就能让attention不仅考虑每个点的值,也能考虑每个点的上下文信息,将具有相似形状的区域建立起联系。
6
TFT

论文题目:Temporal fusion transformers for interpretable multi-horizon time series forecasting(2019)
下载地址:https://arxiv.org/pdf/1912.09363.pdf
这篇文章中则采用了LSTM+Transformer的方式。时间序列首先输入到LSTM中,这里的LSTM既可以起到类似于CNN提取每个点上下文信息的作用,也可以起到Position Encoding的作用,利用LSTM的顺序建模能力,替代原来Transformer中随模型训练的Position Embedding。对于特征的输入,TFT也进行了详细设计,在每个时间步的输入特征上,都会使用一个特征选择模块(一个attention)给当前时间步每个特征计算重要性。这个重要性后面也被用于对时间序列预测结果进行可视化分析,看每个时刻各个特征对于预测的重要性狂。

7
Transformer无监督预训练

论文题目:A transformer-based framework for multivariate time series representation learning(KDD 2021)
下载地址:https://arxiv.org/pdf/1912.09363.pdf
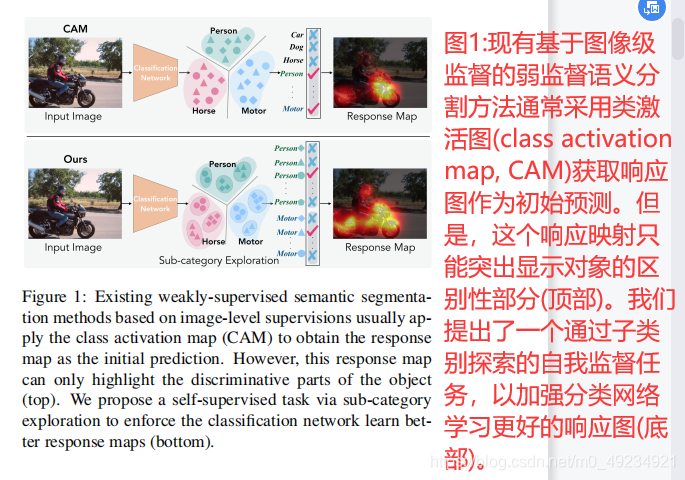
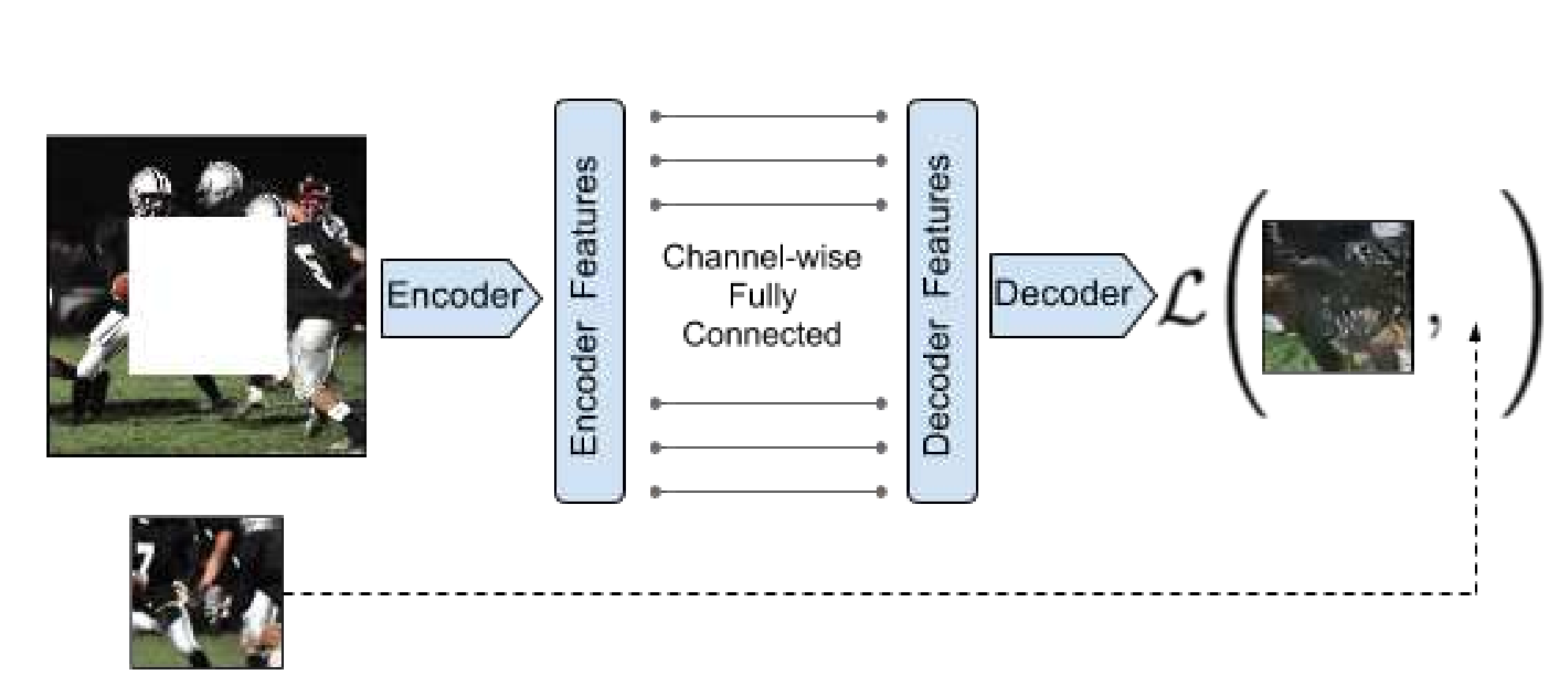
这篇文章借鉴了预训练语言模型Transformer的思路,希望能够在多元时间序列上通过无监督的方法,借助Transformer模型结构,学习良好的多元时间序列表示。本文重点在于针对多元时间序列设计的无监督预训练任务。如下图右侧,对于输入的多元时间序列,会mask掉一定比例的子序列(不能太短),并且每个变量分别mask,而不是mask掉同一段时间的所有变量。预训练的优化目标为还原整个多元时间序列。通过这种方式,让模型在预测被mask掉的部分时,既能考虑前面、后面的序列,也能考虑同一时间段没有被mask的序列。
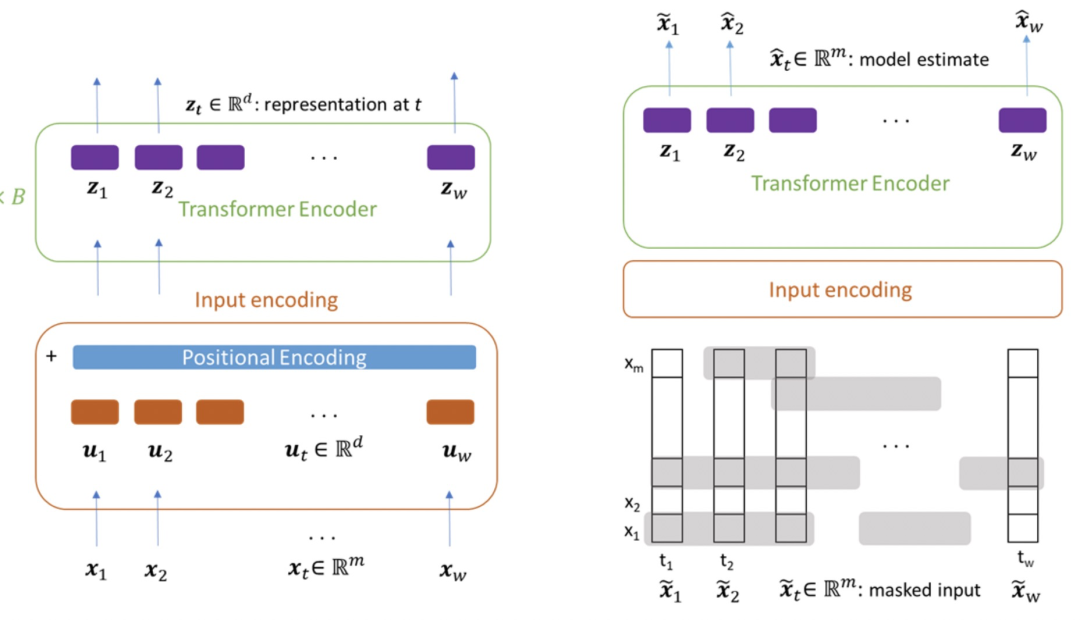
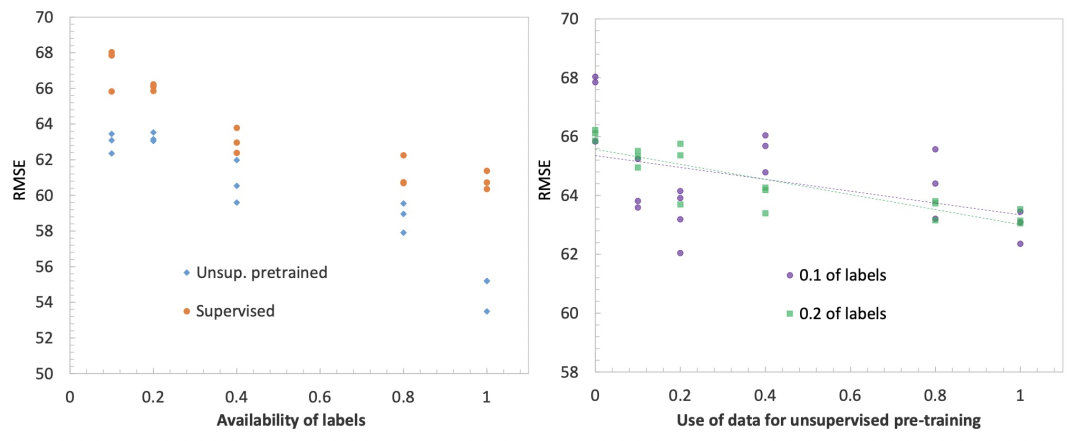
下图展示了无监督预训练时间序列模型对时间序列预测任务带来的效果提升。左侧的图表示,不同有label数据量下,是否使用无监督预训练的RMSE效果对比。可以看到,无论有label数据量有多少,增加无监督预训练都可以提升预测效果。右侧图表示使用的无监督预训练数据量越大,最终的时间序列预测拟合效果越好。
8
总结
这篇文章给大家汇总了Transformer在时间序列中的应用,也给大家推荐一篇时间序列Transformer的综述类文章,2022年发表的,比较新,介绍的Transformer在时间序列中的应用也比较全:Transformers in Time Series: A Survey(2022)。

《人工智能量化实验室》知识星球

加入人工智能量化实验室知识星球,您可以获得:(1)定期推送最新人工智能量化应用相关的研究成果,包括高水平期刊论文以及券商优质金融工程研究报告,便于您随时随地了解最新前沿知识;(2)公众号历史文章Python项目完整源码;(3)优质Python、机器学习、量化交易相关电子书PDF;(4)优质量化交易资料、项目代码分享;(5)跟星友一起交流,结交志同道合朋友。(6)向博主发起提问,答疑解惑。