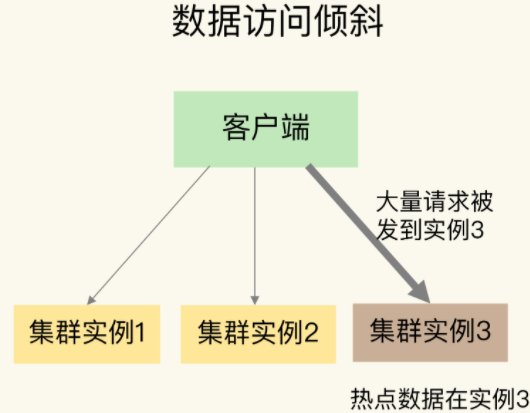
在前期的工作遇到了很多数据倾斜的案例,在此记录下解决的心得
1) 大表join小表:
执行某段sql,出现了Executor OOM的现象,查看其stage的状况:

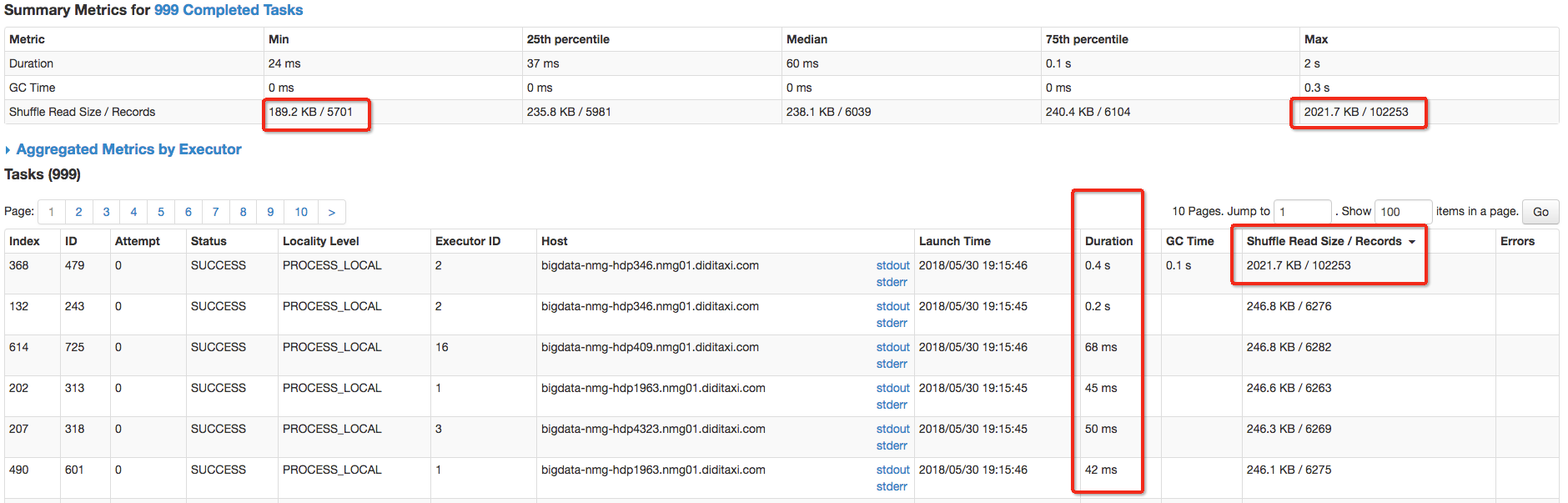
第3个stage读取了21.1G的数据,并shuffle写入了2.6G的数据,由于两个表根据字段进行join,因此必然会触发shuffle操作。最后的stage4 需要从stage3 shuffle read 2.6G的数据,再写入到本地,从图中可知,stage4只shuffle读取了1.2G的数据,然后就失败,因此剩余的1.4G数据倾斜到了一个分区中。
查看下sql执行计划:

从图中可知,左边只读取了107条记录,而右表读取了10亿条数据,但最终执行的join方式为sort merge join。
sort merge join是sparksql中对两张大表进行join的方式之一,基本原理如图所示:

1) 在shuffle阶段,将两张大表根据join key进行重新分区,key相同的记录会被划分到一个分区中
2) 在sort阶段,对单个分区节点的两表数据,按照key进行重新排序
3) 在merge阶段,对排序好的两张表进行join操作,通过顺序移动两边指针,遇到相同的key就merge输出
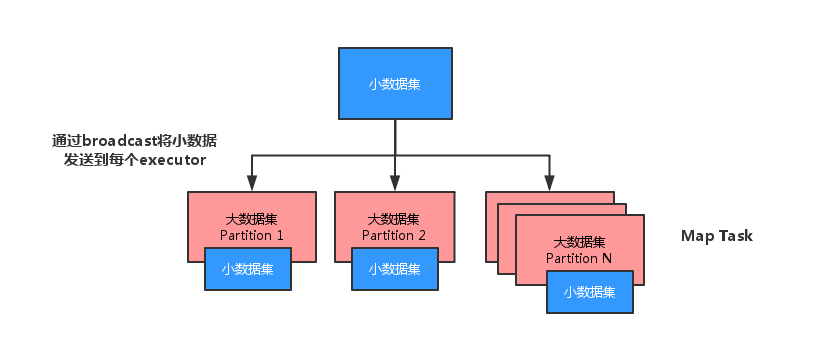
这是一个很典型的小表join大表的例子,因此很容易想到对小表进行广播,sparksql中对小表进行广播的阈值是10M,在这里我们通过sparksql hint手动对小表进行广播:

/*+ mapjoin(t_point)*/ 表示对表t_point进行广播
执行该sql,查看spark的执行stage情况:

从stage情况来看,没有出现shuffle情况,因为小表被广播到了大表所在节点上,因此不会产生跨节点数据传输。

从sql的执行计划来看,执行了broadcast join。
2) 两张大表join
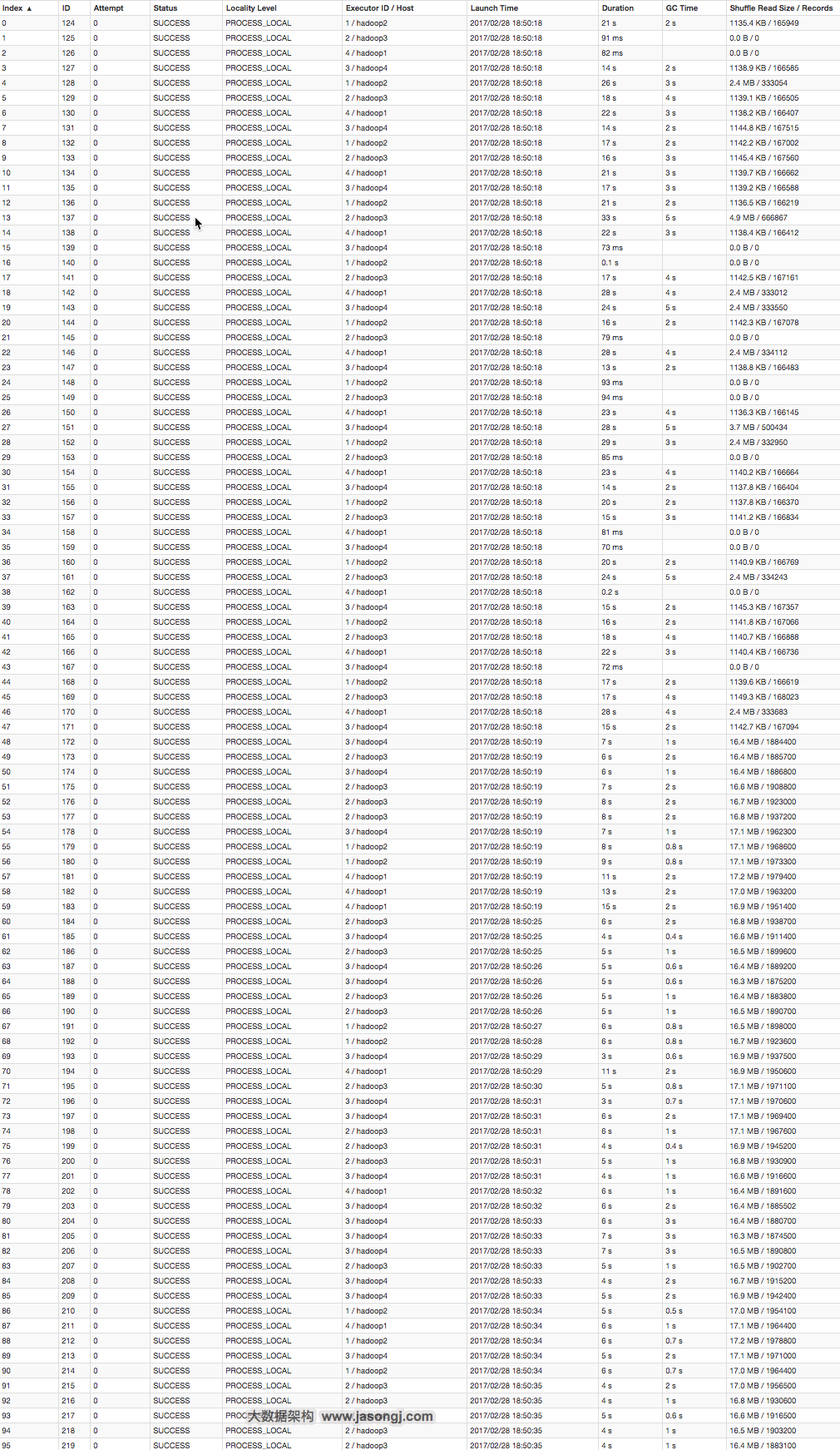
sql逻辑时两张大表根据appid进行join,并且最终提取相关字段,但执行时出现了数据倾斜现象:

从图中可以看出,其中一个task的shuffle数据量明显比其它task多。
经过分析,发现是由于appid为 100IME这个条件的记录非常多,导致该记录出现了数据膨胀的现象。
由于两张表都是大表,因此不能采用第一种对表进行广播的方式。
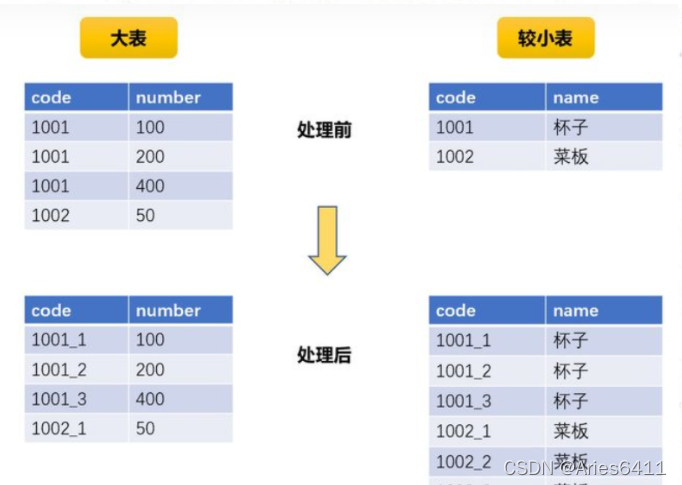
我们将数据输出分为两步,首先在两张表中过滤掉appid为100IME的记录,过滤之后的appid分布较为均匀,因此数据很快跑出;
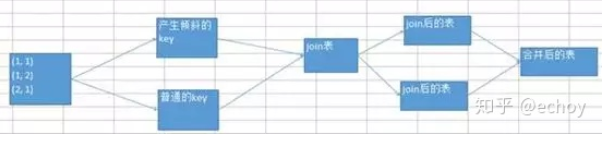
第二步也就是在两张表中筛选appid为100IME的记录,注意这时两张表不能直接进行join,否则所有的数据会落到一个分区中(因为key都是一样)
我们首先将两张表筛选appid为100IME的记录得到两个rdd,然后在两个rdd进行join的地方指定分区函数,见下图的代码:

我们在该分区函数中指定分区数量为200,同时对key进行随机路由,因为这里的key都是100IME,所以我们通过random函数让当前记录随机路由到200个分区中任意一个分区中。
执行该代码后,观察执行图:

从图中可以看到,每个task处理的数据都很均匀,没有出现数据倾斜现象。
最后将两部分的数据合并到一起就完成了整个业务流程。