一、什么是数据倾斜
简单来说,就是在数据计算的时候,数据会分配到不同的task上执行,当数据分配不均匀导致某些大批量数据分配到某几个task上就会造成计算不动或者异常的情况。
二、数据倾斜表现形式
1、大部分的task在计算的时候计算的特别快,耗时很短就计算完,但是就剩下那么几个task一直卡着,要执行很长很长时间,这就是出现数据倾斜了
2、还有一种情况就是,大部分的task很快计算完了,某些task在计算的时候总是报OOM,即使再提交好几次还是报内存溢出一类的异常,这就是出现数据倾斜了
三、产生原因
数据倾斜都是出现在任务执行shuffle操作的时候。因为shuffle的原理就是按照key来进行values的数据的输出、拉取和聚合,同一个key的values一定会被分配到同一个reduce task上进行处理。当某些key的values数据量特别特别大,但是其它多数key的values数据量相比却挺少,那么就会造成某些reduce task上数据量特别特别大,那么在计算的时候就会出现某些task执行的时候特别慢,这就是数据倾斜
四、如何定位问题的位置
1、因为产生shuffle的原因就是你使用了会产生shuffle的算子,就在你的代码中找找 groupByKey、countByKey、reduceByKey、join这类算子
2、要是找不到相应容易产生shuffle的算子,就直接看执行日志,看看到底是哪行代码导致报错的
五、解决方法
对于shuffle算子,主要有 *ByKey和Join这两类,咱们分别对他们做优化
一、*ByKey类算子
1、提高reduce的并行度
这种方法治标不治本
提高reduce task的数量,就可以让每个reduce task能分配到更少的数据量,这样就能缓解数据倾斜的问题,在 groupByKey、countByKey、reduceByKey调用的时候在括号里最后一个参数传入一个并行度的值
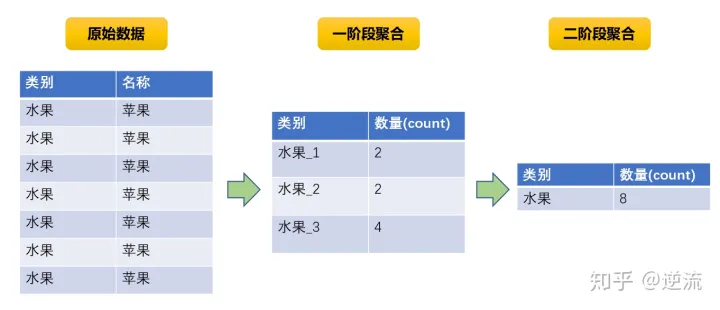
2、随机Key实现双重聚合
这种方法比较治本
第一步:先将Key进行hash打散,也就是平时说的加盐处理,就是在key的前边拼上一个hash过的字符串,这样就能将原本相同的key转换成不一样的key,这样就把一个values数据量特别大的key分成了好多个values数据量比较小的key,然后对这些key进行聚合(这叫做局部聚合)
第二步:将这些key的hash前缀去掉,还原成原来的key,然后对这些数据再进行聚合(这叫做全局聚合)
二、Join类算子
对于join操作有以下三种方法,注意每种的使用场景
1、将reduce join转换为map join
普通的join都是将相同的key对应的values汇聚到同一个task中再进行join,所以都会执行shuffle操作,当然也很容易产生数据倾斜问题

这种情况是适用于某一个数据集(RDD)的数据量比较小的情况,因为这样才能将小数据集广播到每个executor上,在其中block manager缓存一份,这样当与大数据集的每个task上的数据进行join的时候就不会执行shuffle操作了,杜绝了数据倾斜的发生。
注意:这种操作能治本,但是首先得确保其中的一个数据集数据量比较小才行,这样才能加载到内存中
比如一个RDD是100万数据,一个是1万数据;一个是1亿数据,一个是100万数据

2、sample采样倾斜的Key进行两次join
这个首先得用countByKey的方式看一下数据集(RDD)中各个key对应的数据量是多大,当你发现整个数据集中就某几个key数据量特别大,那就将这几个单独拉出来,放到一个单独的RDD中让它单独join,这样这些数据就有可能被分配到多个task中进行执行,最后和不倾斜key的join后的数据进行union
注意:这种只能适用于引起数据倾斜的Key比较少的情况,要是大数据量的Key确实挺多,那就用最后一种方法
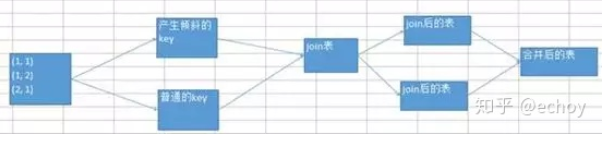
3、使用随机数以及扩容表进行join
这样是前边两种执行效果不大好才做这种操作,就是将一个数据集的key的前缀拼上hash字符串前缀,另一个数据集进行flatmap扩容,这样进行join,就能将数据打散避免汇集到某几个task上执行
第一步、选择一个比较大的数据集,将每条数据的Key都打上一个10以内的随机数
第二步、选择一个比较小的数据集,将每条数据使用flatmap,映射成多条数据(比如10条,这个你得看第一步你用的是多大值以内的随机数),每个映射出来的数据,key值都带有10以内的随机数
第三步、将两个处理后的数据集进行join操作
第四步、将join后的数据的key值还原成原来的key
注意:具体需要扩容多大,就得看数据量了,如果两个RDD数据量都很大,就少扩容点
六、参考文章
面试必问&数据倾斜