目录
第七章 数据倾斜
7.1 数据倾斜的产生,表现与原因
7.1.1 数据倾斜的定义
7.1.2 数据倾斜的危害
7.1.3 数据倾斜发生的现象
7.2 数据倾斜倾斜造成的原因
7.3 几种常见的数据倾斜及其解决方案
7.3.1 空值引发的数据倾斜
7.3.2 不同数据类型引发的数据倾斜
7.3.3 表连接时引发的数据倾斜
7.3.4 group by分组时候key值分布不均
7.3.5 count distinct去重的时候key值分布不均
7.3.6 排序过程
7.2.7 数据膨胀引起
7.4 实践与定位
第七章 数据倾斜
7.1 数据倾斜的产生,表现与原因
7.1.1 数据倾斜的定义
数据倾斜是指在并行进行数据处理的时候,由于单个partition的数据显著多余其他部分,分布不均匀,导致大量数据集中分布到一台或者某几台计算节点上,使得该部分的处理速度远低于平均计算速度,成为整个数据集处理的瓶颈,从而影响整体计算性能。
7.1.2 数据倾斜的危害
对于分布式系统来说,理想的处理方式应该是各台机器共同工作,整体耗时随着计算节点数量的增加而线性下降。但在实际情况下,很多机器所分配的任务是不均匀的,例如大部分任务被分配到个别机器上,其他机器只处理小部分任务,则执行效率提升不明显,远低于理想值。由此可见,根据“水桶效应”,分布式系统的计算能力由耗时最长的任务所决定,对于大数据系统来说,可怕的不是大数据量,而是数据倾斜。
当数据出现数据倾斜的时候,某机器计算耗时远高于其他机器,带来的主要问题有两点:一是整体耗时过大,不能充分发挥分布式系统的并行计算优势;二是部分机器处理的数据量过大,可能导致内存不足,任务失败。
7.1.3 数据倾斜发生的现象
通过检查日志可以看到,出现数据倾斜主要有一下3种现象:
-
绝大多数任务执行的很快,但个别Executor执行时间很长,导致整体任务卡在某一阶段不能结束,整体执行时间过长;
-
原本能够正常执行的Spark作业,爆出内存溢出异常,无法正常产出数据;
-
个别Reduce处理的数据量与平均数据量相比差异过大,通常可达3倍甚至更多,远远超过其他正常reduce,
7.2 数据倾斜倾斜造成的原因
数据倾斜产生原因主要有以下几点:数据key值分布不均,机器配置和数据量比例不合理,业务数据本身特性导致。
-
key-value值分布不均
例如join连接,group by分组,distinct去重
-
机器配置不合理
当机器配置与所需的数据量不相匹配的时候,总会出现部分需要处理的key值数量超出机器处理能力的情况,由此造成Reduce进程卡顿。
-
业务数据自身特性
除了技术上的原因,业务本身的特性也会导致数据分布不均匀的情况,如不同品牌门店的数据量,订单量。
-
小文件过多,笛卡尔积造成的数据膨胀等
7.3 几种常见的数据倾斜及其解决方案
7.3.1 空值引发的数据倾斜
-
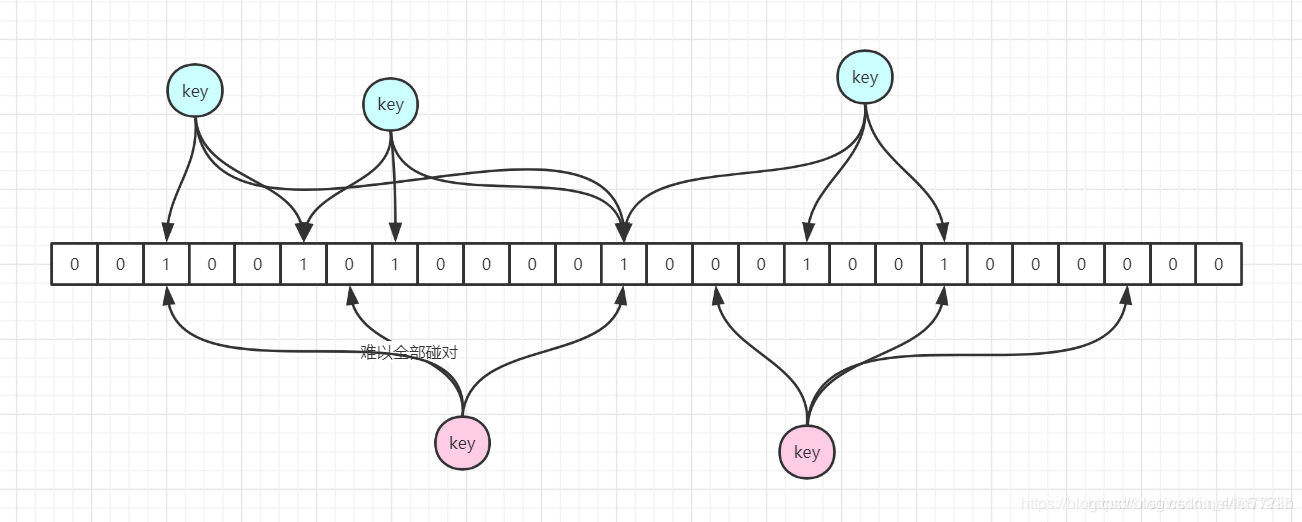
问题描述:实际业务中有些大量的null值或者一些无意义的数据参与到计算作业中,表中如果有大量的null值,如果表之间进行join操作,就会有shuffle产生,这样所有的null值都会被分配到一个reduce中,必然产生数据倾斜。
-
注意:a,b两个表进行join操作,假设a表需要join的字段为null,但是b表需要join的字段不为null,这两个字段根本就join不上,为什么还会放在同一个reduce中呢?我们要注意的是,数据放到同一个reduce中的原因不是因为字段能不能join上,而是因为shuffle阶段的hash操作,只要key值相同,他们就会被拉到同一个reduce中。
-
解决方案1:直接不让null值参与join操作,也就是不让null值有shuffle阶段
select *from log ajoin users bon a.user_id is not null and a.user_id = b.user_idunion all select *from log a where a.user_id is null;-
解决方案2:对null值进行随机赋值。因为null值参与shuffle时的hash结果是一样的,那么我们可以给null值随机赋值(注意:使用concat连接某一个字符串,防止与其他真实数据冲突出现问题),这样他们的hash结果就不一样,就会进到不同的reduce中。
select * from log aleft join users bon case when a.user.id is null then concat(‘hive_’,rand())else a.user_id end= b.user_id;7.3.2 不同数据类型引发的数据倾斜
-
问题描述:对于两个表join,表a中需要join的字段key为int,表b中key字段既有string类型,也有int类型。当按照key进行两个表的join操作时,默认的hash操作会按int型的id来进行分配,这样所有的string类型都被分配成同一个id,结果就是所有的string类型的字段进入到一个reduce中,引发数据倾斜。
-
原因:既有字符串又有int类型的时候,就是很多字符串数据被当做同一个int的id进行分配,导致所有的字符串数据被分配到同一个reduce里面了。
-
解决方案:如果key值既有string类型也有int类型,默认的hash都会按照int类型来分配,那我们直接把int类型都转为string就好了,这样key字段都为string,hash时候就按照string类型分配了。
7.3.3 表连接时引发的数据倾斜
-
问题描述:大小表
-
说明:在map阶段进行join,而不是像普通的join那样在Reduce阶段按照join列进行分发后在每个Reduce节点上进行join,一来省去了Shuffle这个代价,二来不需要分发。
-
解决方案:将其中做连接的小表(全量数据)分发到所有MapTask端进行join,从而避免了reduceTask,前提要求是内存足以装下该全量数据。也就是说我们在map端进行了join操作,省去了reduce阶段,即没有shuffle过程,没有reduce任务,避免了数据倾斜。(参考:https://www.modb.pro/db/86447)
-
补充:在map端进行join,其原理是broadcast join,即把小表作为一个完整的驱动表来进行join操作。在通常情况下,需要连接的各个表里面的数据会分布到不同的Map中进行处理。即同一个key对应的value可能存在不同的Map中,这样就必须等到Reduce中去连接。需要使mapJoin能够顺利进行,那就必须满足这样的条件:除了一份表的数据分布在不同的Map中,其他连接的表的数据必须在每个Map中都有完整的拷贝。Map Join会把小表全部读入内存中,在Map阶段直接拿另外一个表的数据和内存中表数据做匹配(这时候可以使用Distributed Cache将小表分发到各个节点上,提供Mapper加载使用),由于在map时进行了join操作,省去了reduce运行的效率也会高很多
7.3.4 group by分组时候key值分布不均
-
问题描述:由于key值分布不均匀,在使用group by分组的时候产生了数据倾斜
-
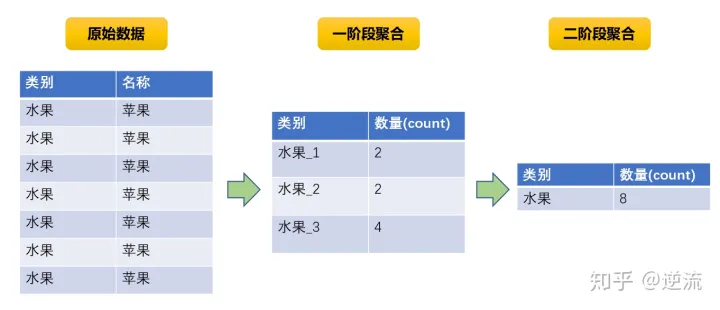
解决方案:采用两阶段聚合的方式。两阶段聚合指的是先局部聚合再全局聚合。局部聚合时候给每个key值加上随机前缀进行打散,原本相同的key值会变成不同的新key值,便可以让原来由一个task处理的数据根据加上随机前缀后的新key值分散到多个Task上做聚合,从而缓解单个task处理数据量过多的问题。再去除随机前缀做全局聚合,既可以得到最终结果。
-
优点:对于聚合类操作导致的数据倾斜效果明显,可以大幅缓解数据倾斜问题,提升作业执行效率。缺点在于只适用于聚合类场景,不适用于join等其它操作。

7.3.5 count distinct去重的时候key值分布不均
-
问题描述:大多数是因为空值造成的。
-
解决方案1:将空值部门与非空值部分拆分成两个部分单独处理后再做合并
-
解决方案2:使用sum() group by来替代count(distinct )。
7.3.6 排序过程
问题描述:order by会对输入做全局排序,当只有一个reducer的时候,如果输入规模较大,会消耗较长的计算时间。
解决方案:?
7.2.7 数据膨胀引起
-
问题描述:在多维聚合计算时,如果进行分组聚合的字段过多,如下:
select a,b,c,count(1) from log group by a,b,c with rollup;
-
解决方案:通过参数hive.new.job.grouping.set.cardinality配置的方式自动控制作业的拆解,该参数默认值是30,表示针对grouping sets/rollups/cubes这类多维聚合的操作,如果最后拆解的键组合大于该值,会启用新的任务去处理大于该值之外的组合,某个分组聚合的列有较大的倾斜,可以适当调小该值。
7.4 实践与定位
因为实际上,绝大部分的数据倾斜都产生在Shuffle阶段,我们治理的办法一般是发现问题--定位问题--根据问题原因分类优化(例如join,group by , count distinct)
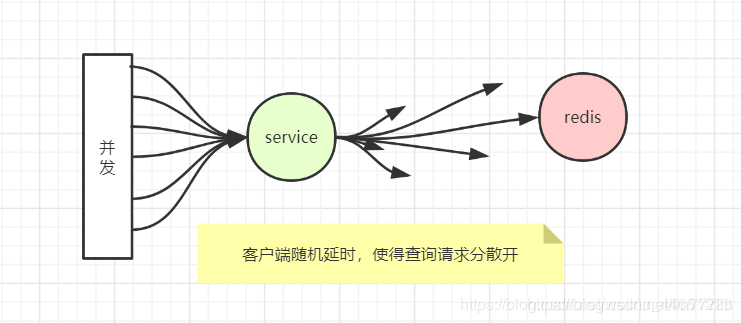
我们首先找到执行时间较长的stage,判断stage是否倾斜。倾斜的指标:stage的其task的执行时长和处理数据量的(max/mid)的值都大于2,且该stage的执行时长大于1800s)可能会有多个执行执行时间比较长的stage存在数据倾斜,请分别定位治理。注意,存在数据倾斜的stage不一定执行时间最长。
找到stage后,根据提示信息即可定位大致的问题,找到SQL问题位置,然后分析表的key值分布,表的大小,确定问题,进行程序优化。