写在前面:有博主的文章写的很好,很详细,推荐!
参考:Spark如何处理数据倾斜(甚好,甚详细,很有逻辑,强推!)
spark数据倾斜解决方案汇总
1、什么是数据倾斜
在执行shuffle操作的时候,数据是按照key对每行数据进行拉取、聚合等操作的。同一个key的数据Row,一定是分配到一个task中进行处理的。
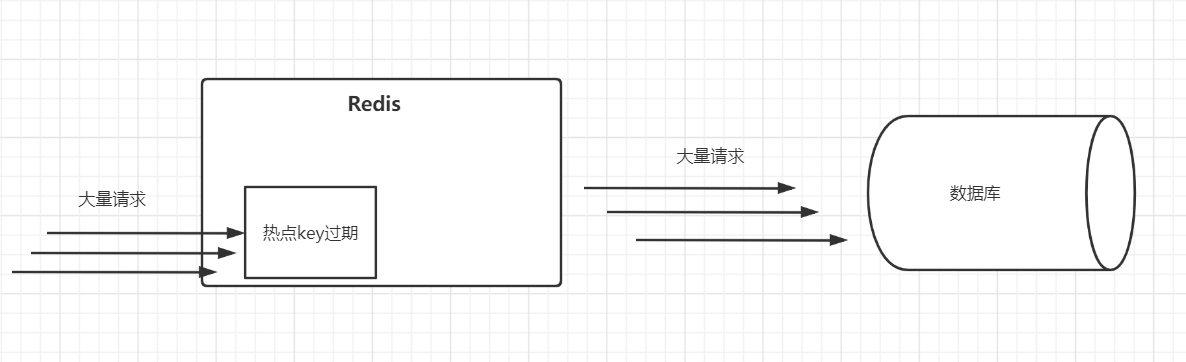
当大量相同key的数据被partition分配到同一个分区里时,就会发生数据倾斜问题。
例子: 有数据行共是90万,可能某个key对应了88万数据,这88万个数据行就会被分配到同一个task上去面去执行。
另外的一些task,会被分配去处理剩下的2万行数据。那么这些task处理的数据比较少,可能1分钟就计算完毕;
但是那个处理88万行数据的task可能就需要30分钟、1小时,甚至更久才能处理完。
2、为什么会发生数据倾斜
数据倾斜容易产生在两个过程,本身数据源的倾斜,这个主要由于本身文件的分布不均,主要是不能切分的文件isSplitable=false ,如.gz文件。
另外的在shuffle阶段,key的分布不均,导致大量的数据集中到单个或者某几个task上导致数据整个stage,执行慢,影响整个job作业,总结主要有以下两个过程:
1、数据源数据文件不均匀
2、计算过程中key的分布不均
(1)单个rdd中进行groupby 的时候key分布不均
(2)多个rdd进行join过程中key的不均匀
3、数据倾斜问题在spark中的常见表现
某个task任务 长时间卡在某一个百分比
1、大部分的task,都执行的特别特别快,剩下几个task,执行的特别特别慢。
2、运行的时候,其他task执行完了,但是有的task,会突然间报OOM,JVM Out Of Memory,内存溢出
4、数据倾斜问题快速定位
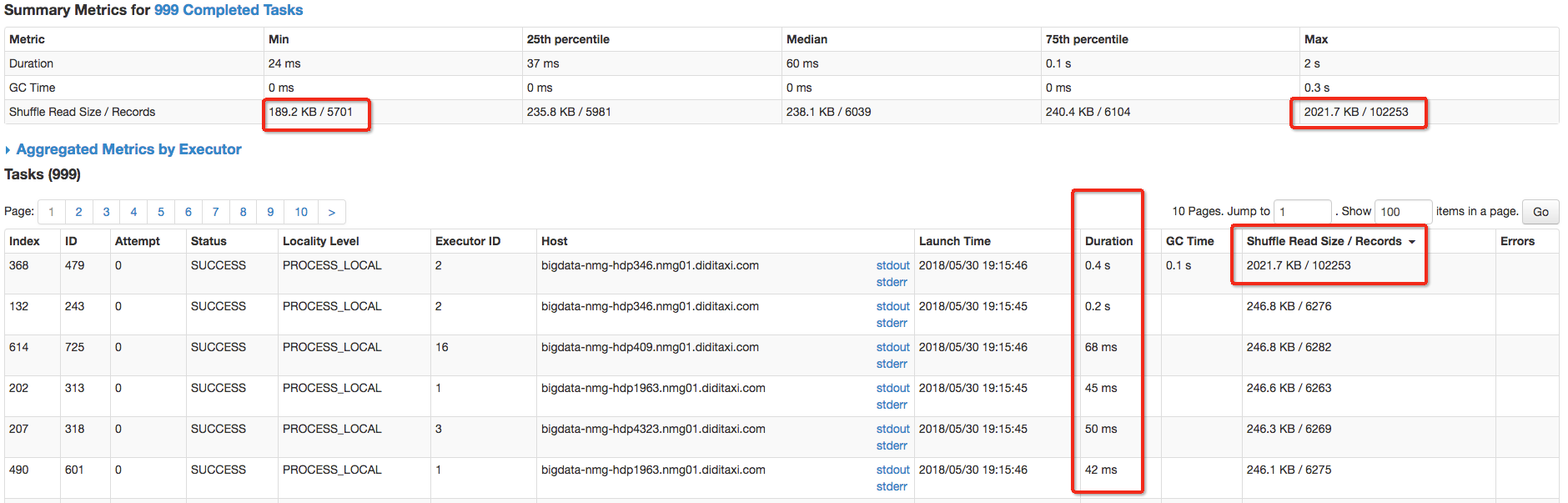
1.根据Spark UI查看metrics,input 以及shuffle read 两个metrics判断task的min,跟max是否差异较大,如果差异非常大,并且影响运行,则需要优化task input 数据源倾斜,input size统计是从外部数据源读入的大小

2.task shuffle 数据倾斜,一般主要是shuffle read拉取数据的时候,数据partition分布不均,导致fetch拉取过程中数据倾斜,可以通过Shuffle Read Size查看min,和max 值,如果差异非常大,并且影响运行,则需要优化

3.另外就是我们在运行中个别task执行特别慢的时候,我们可以看一下该task的input或者shuffle reader的Summary Metrics里面min和max值,一般情况下处理的数据越多,task的运行时间越长,理想情况下所有的task数据均匀分布,运行时长均等,可以定位到task所属的stage,通过stage 描述,可以定位到所属的代码行,进而优化代码
5、怎么处理数据倾斜问题
1、数据源数据文件不均匀
适用场景:对于数据源单个spark input read数据量过大,或者单个task 相对于其他task spark input read较大的情况,读取数据源明显不均匀
解决方式:尽量使用可切割的文本存储,生成尽量多的task进行并行计算
优点:从数据源避免倾斜,并且从源头增大并行度,避免倾斜
缺点:需要改造数据源,支持可切割
2、Shuffle过程中数据分布不均
原理:
Shuffle阶段在分布式并行计算引擎中是常见一个过程,在spark中当一个RDD的数据需要被多个子RDD所使用的时候,我们需要进行shuffle将数据打散,把数据均匀的分配给子RDD进行并行计算,Shuffle过程中spark默认使用HashPartitioner对数据进行分区,在这个过程中可能由于我们的数据分布不均,我们在进行hash取摸的时候,并行度设置不足,导致多数据分配到一个task上,导致倾斜,或者就是相同key的数据hash取摸之后就是比较大,分配同一个task导致数据倾斜等,对于这行情况我们分以下场景进行解决
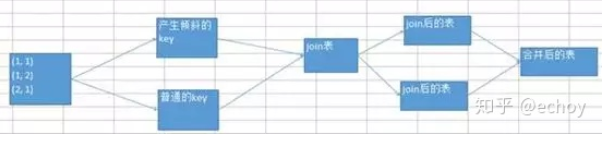
(1) 适用场景:大量的数据分配到相同的task中,导致倾斜
解决方案:通过repartition强制进行shuffle,增大并行度,将数据分布的更加均匀; 设置spark.default.parallelism和自定义分区,增大并行度;如果是sql的话,调整spark.sql.shuffle.partitions增大并行数量,从而将倾斜数据分配到更多的task减少倾斜;
优点:对于部分key倾斜,可以通过增大并行数,或者自定义分区,将数据分布的更加均匀,减少数据倾斜
缺点: 对于单个key倾斜,只能根据业务自定分区,减少数据倾斜
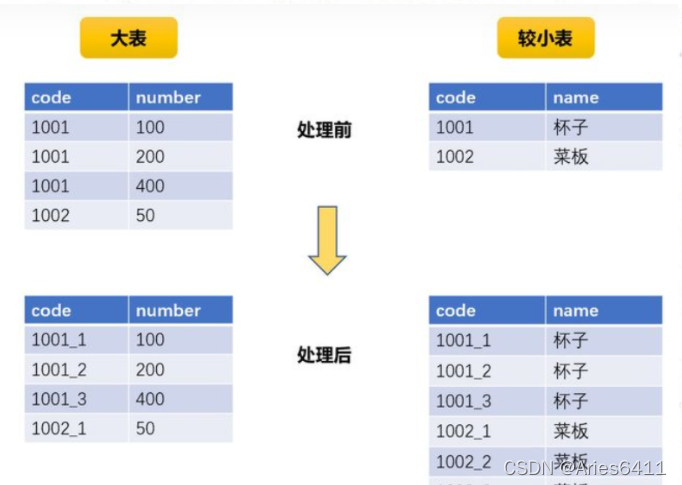
(2)适用场景:两个数据集差别较大,并且出现task数据倾斜,较小的数据集可以放到内存中map中进行join
解决方案:通过增大spark.sql.autoBroadcastJoinThreshold 阈值默认10M
优点:减少大的数据集shuffle,从而导致数据倾斜
缺点: join小表的数据需要足够小,能放到executor storage memory中
6、总结
数据倾斜无法避免,也有没有一劳永逸的解决方式,处理数据倾斜是一个长期的过程需要我们慢慢积累经验,基本思想就是
1.首先从源头选择可以split的数据源,从源头避免倾斜
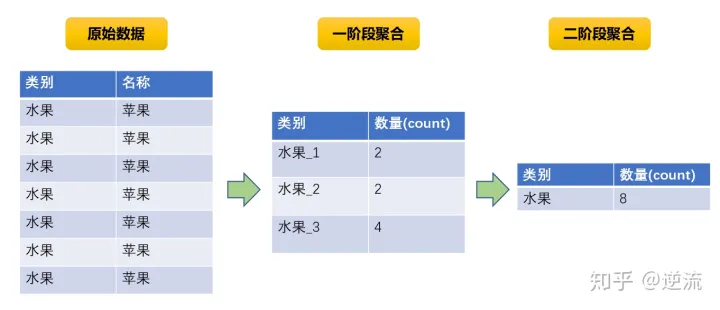
2.shufle过程中,增加并行度,减少shuffle 在map-side进行数据合并,避免reduce fetch数据倾斜
3.sample采样将倾斜的数据,特殊处理,这个方法可以适用于所有的数据倾斜问题,
4.另外,就是我们尽量使用spark-sql,spark-sql里面优化器提供很多基本CRO和CBO的优化策略,不仅帮我们从源头帮我们去除无关的数据减少计算数据量,其次在计算过程中会根据我们的table 的数据量,自动帮我们计算合适task partition数量,和选择合适join策略,从而提升计算性能,也避免shufle 数据倾斜