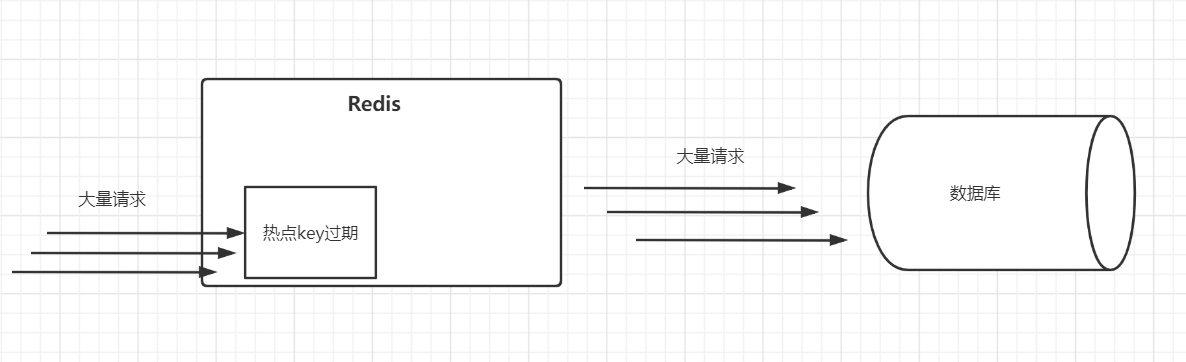
一、什么是数据倾斜
在分布式集群计算中,数据计算时候数据在各个节点分布不均衡,某一个或几个节点集中80%数据,而其它节点集中20%甚至更少数据,出现了数据计算负载不均衡的现象。
数据倾斜在MR编程模型中是十分常见的,用最通俗的话来讲,数据倾斜就是大量的相同key被分配到一个partition里,而其它partition被分配了少量的数据。这时候我们就认为是数据倾斜了
二、数据倾斜的影响
造成了“少数人累死,多数人闲死”的情况,这种情况是我们不能接受的,这也违背了分布式计算的初衷。集群中一个或几个节点要承受着巨大的计算压力,而其它节点计算完毕后要一直等待忙碌的节点计算完成,也拖累了整体的计算时间,直接导致计算效率低下,甚至出现最终executor撑爆,OOM结果。
小结如下:
(1)拖慢运行速度,计算效率低下。特别是对于一些几十亿到百亿的大表,倾斜情况下不夸张的情况下,运行十几个小时也不一定结束
(2)撑爆executor,OOM风险。大量的数据涌向同一个task中的executor执行,直接结果是OOM率,任务运行失败
三、数据倾斜的解决
1、数据倾斜的定位及解决
对于spark-program应用而言
(1)倾斜key的定位方法:
选取key,对数据进行抽样,统计出现的次数,根据出现次数大小排序取出前几个
df.select("key").sample(false,0.1).(k=>(k,1)).reduceBykey(_+_).map(k=>(k._2,k._1)).sortByKey(false).take(10)
经过分析,倾斜的数据主要有以下三种情况:
(1)null(空值)或是一些无意义的信息()之类的,大多是这个原因引起。
(2)无效数据,大量重复的测试数据或是对结果影响不大的有效数据。
(3)有效数据,业务导致的正常数据分布。
(2)解决办法
对于第(1),(2)种情况,直接对数据进行过滤即可。对于第(3)种情况则需要进行一些特殊操作,常见的有以下几种做法。
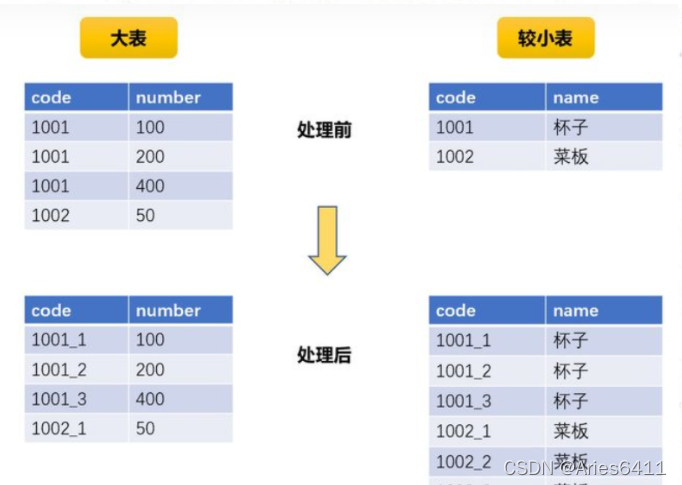
(1)将异常的key过滤出来单独处理,最后与正常数据的处理结果进行union操作
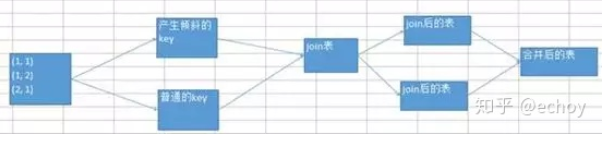
(2)或对所有key先添加随机值,进行操作后,去掉随机值,再继续后续操作
对于spark-sql应用而言
首先,可以对尝试distribute by rand()操作,打乱数据分布
其次,可通过配置开启倾斜key检测
由于Join语义限制,对于A left join skewed B之类的场景,无法对B进行划分处理,否则会导致数据正确性问题,这也是Spark项目所面临的难题。如果开启以上功能依然不能处理数据倾斜,可以通过开启倾斜key检测功能来定位是哪些key导致了倾斜或膨胀,继而进行过滤等处理。
spark.sql.adaptive.enabled=true
spark.sql.adaptive.shuffle.detectSkewness=true (默认false,由于采样计算会导致性能回归,正常任务不要开启)
其他参数:
spark.sql.adaptive.shuffle.sampleSizePerPartition (默认100,每个Task中的采样数,如果Task数量不大,可以酌情调大
在spark-ui上看到hot keys,如下图中的hot keys

2、Spark常见倾斜的场景及解决
Spark的数据倾斜一般由Shuffle时数据不均匀导致的,一般有三类算子会产生Shuffle:Aggregation (groupBy)、Window、Join
Aggregation
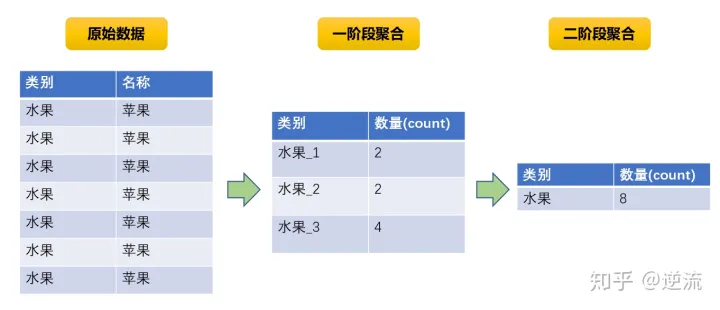
建议打散key进行二次聚合:采用对非constant值、与key无关的列进行hash取模
以DataFrame API示例:
dataframe
.groupBy(col("key"), pmod(hash(col("some_col")), 100)).agg(max("value").as("partial_max"))
.groupBy(col("key")).agg(max("partial_max").as("max"))
Window
目前支持该模式下的倾斜window,(仅支持spark3.0)
select (... row_number() over(partition by ... order by ...) as rn)where rn [==|<=|<] k and other conditionsspark.sql.rankLimit.enabled=true (目前支持基于row_number的topK计算逻辑)
Join
Shuffled Join
在spark2.4版本
开启功能:
spark.sql.adaptive.enabled=true
spark.shuffle.statistics.verbose=true
spark.sql.adaptive.skewedJoin.enabled=true
spark.sql.adaptive.allowAdditionalShuffle=true如果不能处理,建议用户自行定位热点数据进行处理
在spark3.0版本
数据倾斜(Join)
spark.sql.adaptive.enabled=true
spark.sql.adaptive.skewJoin.enabled=true (默认true)
spark.sql.adaptive.skewJoin.enhance.enabled=true (通用倾斜算法,可处理更多场景)
spark.sql.adaptive.forceOptimizeSkewedJoin=true (允许插入额外shuffle,可处理更多场景)其他参数:
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes=256MB (默认为256MB,分区大小超过该阈值才可被识别为倾斜分区,如果希望调整的倾斜分区小于该阈值,可以酌情调小)
spark.sql.adaptive.skewJoin.skewedPartitionFactor=5 (默认为5,分区大小超过中位数Xfactor才可被识别为倾斜分区,一般不需要调整)
spark.sql.adaptive.skewJoin.enhance.maxJoins=5 (默认5,通用倾斜算法中,如果shuffled join超过此阈值则不处理,一般不需要调整)
spark.sql.adaptive.skewJoin.enhance.maxSplitsPerPartition=1000 (默认1000,通用倾斜算法中,尽量使得每个倾斜分区的划分不超过该阈值,一般不需要调整)
数据膨胀(Join)
在开启数据倾斜功能的基础上,额外开启:
spark.sql.adaptive.skewJoin.inflation.enabled=true (默认false,由于采样计算会导致性能回归,正常任务不要开启)
spark.sql.adaptive.skewJoin.inflation.factor=50 (默认为100,预估的分区输出大小超过中位数Xfactor才可被识别为膨胀分区,由于预估算法存在误差,一般不要低于50)
spark.sql.adaptive.shuffle.sampleSizePerPartition=500 (默认100,每个Task中的采样数,基于该采样数据预估Join之后的分区大小,如果Task数量不大,可以酌情调大)
参考案例(该膨胀导致后续stage反复失败,运行时长超10h)

Read: Max/Read=5.7,Write: Max/Med=142
开启功能后:整个job 23min运行完
参考:
解决spark中遇到的数据倾斜问题_breeze_lsw的博客-CSDN博客_spark中的数据倾斜问题解决spark中遇到的数据倾斜问题一. 数据倾斜的现象多数task执行速度较快,少数task执行时间非常长,或者等待很长时间后提示你内存不足,执行失败。二. 数据倾斜的原因数据问题key本身分布不均匀(包括大量的key为空)key的设置不合理spark使用问题shuffle时的并发度不够计算方式有误三. 数据倾斜的后果spark中一个stage的执行时间受限于最后那个执行完的task,https://blog.csdn.net/lsshlsw/article/details/52025949
参考:Performance Tuning - Spark 3.2.1 Documentation![]() https://spark.apache.org/docs/latest/sql-performance-tuning.html#optimizing-skew-join
https://spark.apache.org/docs/latest/sql-performance-tuning.html#optimizing-skew-join