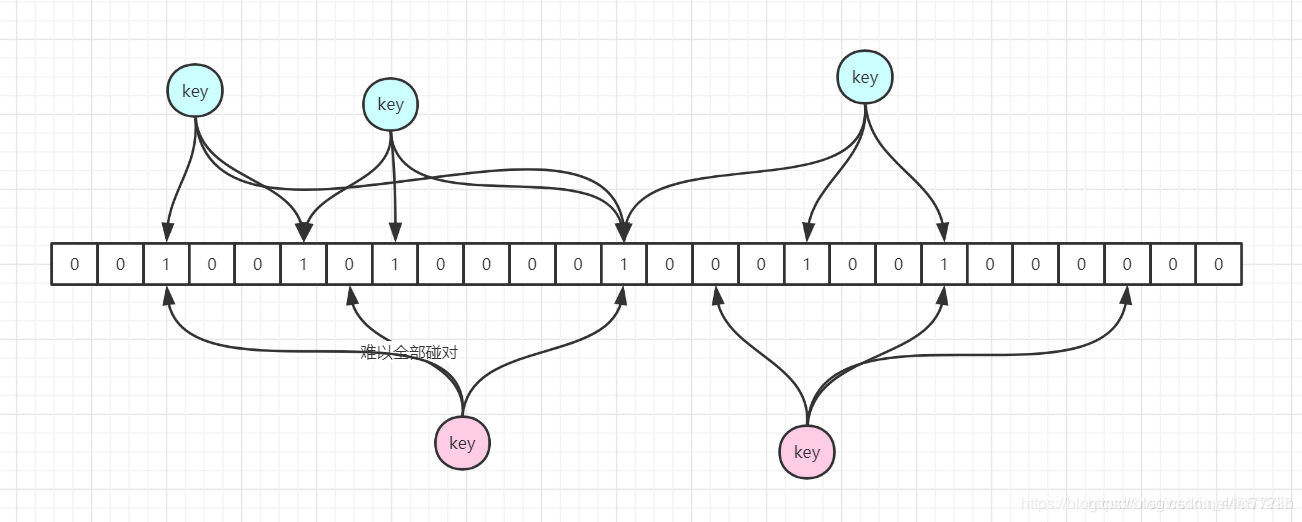
数据倾斜的概念
数据倾斜这四个字经常会在学习MapReduce中遇到。所谓数据分区,就是数据分区分布因为数据本身或者分区方法的原因变得极为不一致,大量的数据被划分到了同一个区。由于Reducer Task每次处理一个区的数据,这导致Reducer Task处理有着大量数据的分区时任务繁重,而其他区分到的任务过于轻松,从而导致整体的任务效率大幅降低。“一个人累死,其他人闲死”。
数据倾斜发生原理
一般来说,数据倾斜会因为两种情况发生:
- 数据的key非常少,极少数的key中记录了非常多的记录值。这属于相同key分到同一个分区导致分区数据过多。
- 数据的key比较多,但有某些key的记录值远远多于其他key,在分区的时候将有着大量记录值的key分到了同一个区。这属于不同key因为分区方法分到同一个区导致分区数据过多。
数据倾斜现象
- 大部分的Task运行速度很快,但是小部分Task运行速度很慢
- 原本能正常执行的Spark作业,某天突然爆出OOM(内存溢出)异常。观察异常栈,是我们写的业务代码造成的。
数据倾斜解决方法
1. 调参解决方法:
增加JVM的内存。这适用于第一种情况(数据的key非常少),往往只能通过硬件的手段来进行调优,增加jvm内存可以显著的提高运行效率。
增加Reduce的个数,或者说叫提高Shuffle的并行度。这适用于第二种情况。第二种情况是因为有较多记录值的key都被分到了同一个分区,才导致了数据倾斜。如MapReduce,它的分区默认是HashPartitioner,让key的哈希值对设定的Reducer Task个数取余。如果我们增加Reduce的个数(修改numReduceTasks值),就会让一些key被分到不同的分区。虽然工作量仍然会不均衡,但是已不会有这么严重的数据倾斜。
set spark.sql.shuffle.partitions= [num_tasks]
2. 聚合类型的数据倾斜解决方法:
聚合类型出现数据倾斜主要是使用group by、distinct造成的。针对聚合类的数据倾斜,有以下方法:
通过加随机前缀重新设计key。比如,我们可以在map阶段随机加上一个固定长度的随机数,使得分区的时候不会像之前那样分到同一个节点,完成一次局部聚合。在这之后将前缀去除,重新进行一次全局聚合即可。
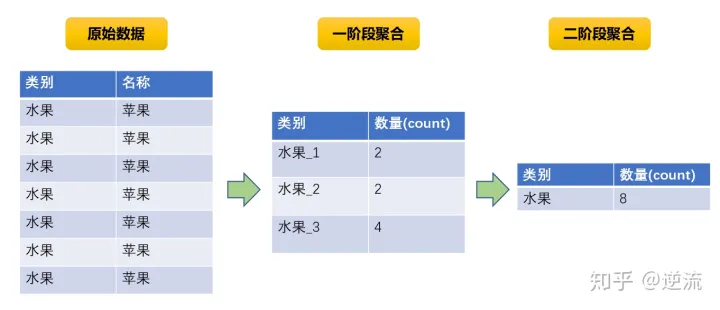
--水果字段名为category
select count (substr(x.category,1,2))
from
(select concat(category,'_',cast(round(10*rand())+1 as string))
from table1
group by concat(category,'_',cast(round(10*rand())+1 as string))
) x --1阶段聚合
group by substr(x.category,1,2); --2阶段聚合
(选自:https://zhuanlan.zhihu.com/p/332368318)
使用combiner合并。Map阶段会将环形缓冲区的数据排序并溢写,在溢写之前,使用combiner将相同key数据进行合并(如累加)。这减轻了数据倾斜的现象,减轻了map端向reduce端发送的数据量(减轻了网络带宽),也减轻了map端和reduce端中间的shuffle阶段的数据拉取数量(本地化磁盘IO速率),推荐使用这种方法。
3. 大表Join小表的数据倾斜解决办法:
set hive.auto.convert.join = true; -- hive是否自动根据文件量大小,选择将common join转成map join 。
set hive.mapjoin.smalltable.filesize =25000000; --大表小表判断的阈值,如果表的大小小于该值25Mb,则会被判定为小表。则会被加载到内存中运行,将commonjoin转化成mapjoin。一般这个值也就最多几百兆的样子。
当一个大表Join小表的时候,可以将小表直接读到内存中,进行Map Join,省去了Shuffle阶段。
4. 大表Join大表的数据倾斜解决办法:
对表分桶排序后Join。当两个大表都做了分桶处理,且分桶数量相同或者成倍数的时候,可以让相同桶的数据进行Map Join。
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
将大表拆分,对倾斜部分单独处理。我们可以根据业务中几乎一定会出现数据倾斜的数据拆分出来,将倾斜与未倾斜的部分分别做处理,再将结果合并。
例如,当需要将订单信息表和卖家评级表进行Join,用于获取不同评级的订单量。因为两个表都很大,并且肯定会出现二八法则,即少部分卖家会占有大量买家,而大部分卖家只有很少的买家。在这种情况下,我们可以从订单信息表中将大卖家的评级挑出来放到临时表中,再处理非大卖家的评级,最后做一个union all即可。
5. 其他解决方法
自定义分区。我们可以自定义一个分区类并继承partition类,自己编写分区策略,这种方法比较显著。
参考:https://blog.csdn.net/weixin_35353187/article/details/84303518
https://zhuanlan.zhihu.com/p/332368318