0x0. 介绍
大家好呀,在过去的半年到一年时间里,我分享了一些算法解读,算法优化,模型转换相关的一些文章。这篇文章是自己开启学习深度学习编译器的第一篇文章,后续也会努力更新这个系列。这篇文章是开篇,所以我不会太深入讲解TVM的知识,更多的是介绍一下深度学习编译器和TVM是什么?以及为什么我要选择学习TVM,最后我也会给出一个让读者快速体验TVM效果的一个开发环境搭建的简要教程以及一个简单例子。
0x1. 为什么需要深度学习编译器?
深度学习编译器这个词语,我们可以先拆成两个部分来看。
首先谈谈深度学习领域。从训练框架角度来看,Google的TensorFlow和FaceBook的Pytorch是全球主流的深度学习框架,另外亚马逊的MxNet,百度的Paddle,旷视的MegEngine,华为的Mindspore以及一流科技的OneFlow也逐渐在被更多人接受和使用。这么多训练框架,我们究竟应该选择哪个?如果追求易用性,可能你会选择Pytorch,如果追求项目部署落地,可能你会选择TensorFlow,如果追求分布式训练最快可能你会体验OneFlow。所以这个选择题没有确定答案,在于你自己的喜好。从推理框架角度来看,无论我们选择何种训练框架训练模型,我们最终都是要将训练好的模型部署到实际场景的,在模型部署的时候我们会发现我们要部署的设备可能是五花八门的,例如Intel CPU/Nvidia GPU/Intel GPU/Arm CPU/Arm GPU/FPGA/NPU(华为海思)/BPU(地平线)/MLU(寒武纪),如果我们要手写一个用于推理的框架在所有可能部署的设备上都达到良好的性能并且易于使用是一件非常困难的事。
一般要部署模型到一个指定设备上,我们一般会使用硬件厂商自己推出的一些前向推理框架,例如在Intel的CPU/GPU上就使用OpenVINO,在Arm的CPU/GPU上使用NCNN/MNN等,在Nvidia GPU上使用TensorRT。虽然针对不同的硬件设备我们使用特定的推理框架进行部署是最优的,但这也同时存在问题,比如一个开发者训练了一个模型需要在多个不同类型的设备上进行部署,那么开发者需要将训练的模型分别转换到特定框架可以读取的格式,并且还要考虑各个推理框架OP实现是否完全对齐的问题,然后在不同平台部署时还容易出现的问题是开发者训练的模型在一个硬件上可以高效推理,部署到另外一个硬件上性能骤降。并且从之前几篇探索ONNX的文章来看,不同框架间模型转换工作也是阻碍各种训练框架模型快速落地的一大原因。
接下来,我们要简单描述一下编译器。实际上在编译器发展的早期也和要将各种深度学习训练框架的模型部署到各种硬件面临的情况一下,历史上出现了非常多的编程语言,比如C/C++/Java等等,然后每一种硬件对应了一门特定的编程语言,再通过特定的编译器去进行编译产生机器码,可以想象随着硬件和语言的增多,编译器的维护难度是多么困难。还好现代的编译器已经解决了这个问题,那么这个问题编译器具体是怎么解决的呢?
为了解决上面的问题,科学家为编译器抽象出了编译器前端,编译器中端,编译器后端等概念,并引入IR (Intermediate Representation)的概率。解释如下:
编译器前端:接收C/C++/Java等不同语言,进行代码生成,吐出IR
编译器中端:接收IR,进行不同编译器后端可以共享的优化,如常量替换,死代码消除,循环优化等,吐出优化后的IR
编译器后端:接收优化后的IR,进行不同硬件的平台相关优化与硬件指令生成,吐出目标文件
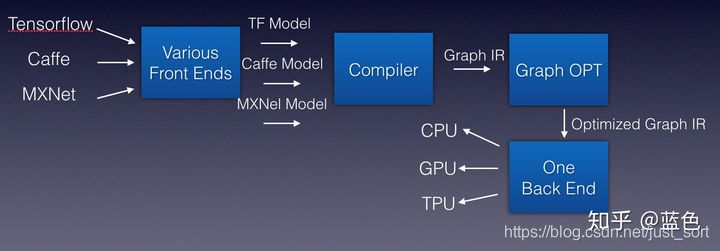
以LLVM编译器为例子,借用蓝色(知乎ID)大佬的图:

受到编译器解决方法的启发,深度学习编译器被提出,我们可以将各个训练框架训练出来的模型看作各种编程语言,然后将这些模型传入深度学习编译器之后吐出IR,由于深度学习的IR其实就是计算图,所以可以直接叫作Graph IR。针对这些Graph IR可以做一些计算图优化再吐出IR分发给各种硬件使用。这样,深度学习编译器的过程就和传统的编译器类似,可以解决上面提到的很多繁琐的问题。仍然引用蓝色大佬的图来表示这个思想。
0x02. TVM
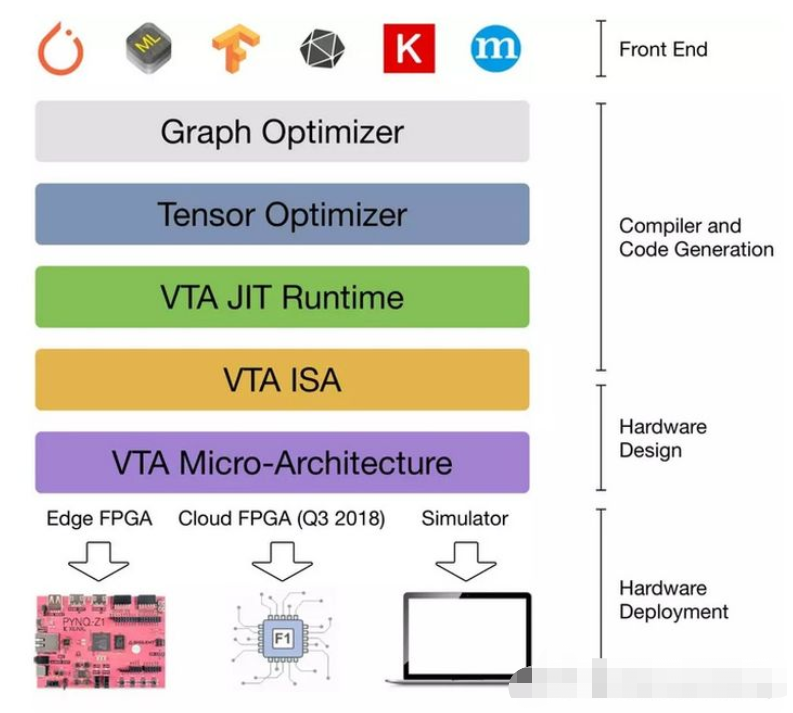
基于上面深度学习编译器的思想,陈天奇领衔的TVM横空出世。TVM就是一个基于编译优化的深度学习推理框架(暂且说是推理吧,训练功能似乎也开始探索和接入了),我们来看一下TVM的架构图。来自于:https://tvm.apache.org/2017/10/06/nnvm-compiler-announcement
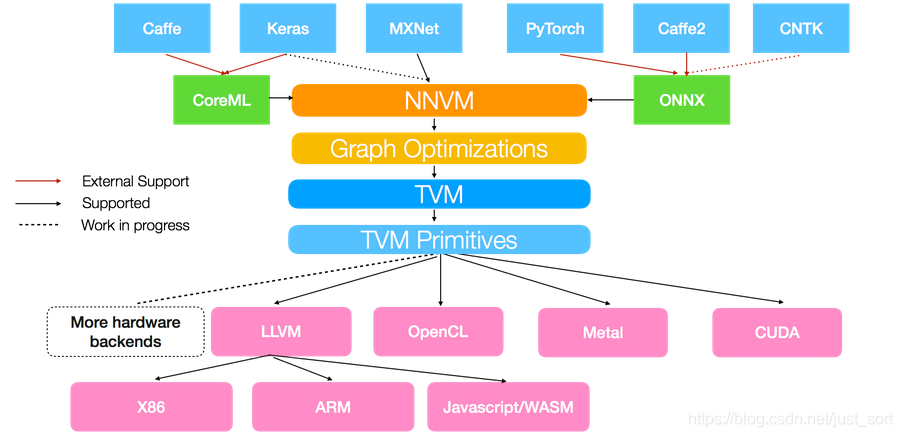
从这个图中我们可以看到,TVM架构的核心部分就是NNVM编译器(注意一下最新的TVM已经将NNVM升级为了Realy,所以后面提到的Relay也可以看作是NNVM)。NNVM编译器支持直接接收深度学习框架的模型,如TensorFlow/Pytorch/Caffe/MxNet等,同时也支持一些模型的中间格式如ONNX、CoreML。这些模型被NNVM直接编译成Graph IR,然后这些Graph IR被再次优化,吐出优化后的Graph IR,最后对于不同的后端这些Graph IR都会被编译为特定后端可以识别的机器码完成模型推理。比如对于CPU,NNVM就吐出LLVM可以识别的IR,再通过LLVM编译器编译为机器码到CPU上执行。
0x03. 环境配置
工欲善其事,必先利其器,再继续探索TVM之前我们先了解一下TVM的安装流程。这里参考着官方的安装文档提供两种方法。
0x03.1 基于Docker的方式
我们可以直接拉安装配置好TVM的docker,在docker中使用TVM,这是最快捷最方便的。例如拉取一个编译了cuda后端支持的TVM镜像,并启动容器的示例如下:
docker pull tvmai/demo-gpu
nvidia-docker run --rm -it tvmai/demo-gpu bash这样就可以成功进入配置好tvm的容器并且使用TVM了。
0x03.2 本地编译以Ubuntu为例
如果有修改TVM源码或者给TVM贡献的需求,可以本地编译TVM,以Ubuntu为例编译和配置的流程如下:
git clone --recursive https://github.com/apache/tvm tvm
cd tvm
mkdir build
cp cmake/config.cmake build
cd build
cmake ..
make -j4
export TVM_HOME=/path/to/tvm
export PYTHONPATH=$TVM_HOME/python:${PYTHONPATH}这样我们就配置好了TVM,可以进行开发和测试了。
我的建议是本地开发和调试使用后面的方式,工业部署使用Docker的方式。
0x04. 样例展示
在展示样例前说一下我的环境配置,pytorch1.7.0 && TVM 0.8.dev0
这里以Pytorch模型为例,展示一下TVM是如何将Pytorch模型通过Relay(可以理解为NNVM的升级版,)构建TVM中的计算图并进行图优化,最后再通过LLVM编译到Intel CPU上进行执行。最后我们还对比了一下基于TVM优化后的Relay Graph推理速度和直接使用Pytorch模型进行推理的速度。这里是以torchvision中的ResNet18为例子,结果如下:
Relay top-1 id: 282, class name: tiger cat
Torch top-1 id: 282, class name: tiger cat
Relay time: 1.1846002000000027 seconds
Torch time: 2.4181047000000007 seconds可以看到在预测结果完全一致的情况下,TVM能带来2倍左右的加速。这里简单介绍一下代码的流程。这个代码可以在这里(https://github.com/BBuf/tvm_learn)找到。
0x04.1 导入TVM和Pytorch并加载ResNet18模型
import time
import tvm
from tvm import relayimport numpy as npfrom tvm.contrib.download import download_testdata# PyTorch imports
import torch
import torchvision######################################################################
# Load a pretrained PyTorch model
# -------------------------------
model_name = "resnet18"
model = getattr(torchvision.models, model_name)(pretrained=True)
model = model.eval()# We grab the TorchScripted model via tracing
input_shape = [1, 3, 224, 224]
input_data = torch.randn(input_shape)
scripted_model = torch.jit.trace(model, input_data).eval()需要注意的是Relay在解析Pytorch模型的时候是解析TorchScript格式的模型,所以这里使用torch.jit.trace跑一遍原始的Pytorch模型并导出TorchScript模型。
0x04.2 载入测试图片
加载一张测试图片,并执行一些后处理过程。
from PIL import Imageimg_url = "https://github.com/dmlc/mxnet.js/blob/main/data/cat.png?raw=true"
img_path = download_testdata(img_url, "cat.png", module="data")
img = Image.open(img_path).resize((224, 224))# Preprocess the image and convert to tensor
from torchvision import transformsmy_preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),]
)
img = my_preprocess(img)
# 新增Batch维度
img = np.expand_dims(img, 0)0x04.3 Relay导入TorchScript模型并编译到LLVM后端
接下来我们将PyTorch的graph导入到Relay成为Relay Graph,这里输入层的名字可以任意指定。然后将Gpath使用给定的配置编译到LLVM目标硬件上。
######################################################################
# Import the graph to Relay
# -------------------------
# Convert PyTorch graph to Relay graph. The input name can be arbitrary.
input_name = "input0"
shape_list = [(input_name, img.shape)]
mod, params = relay.frontend.from_pytorch(scripted_model, shape_list)######################################################################
# Relay Build
# -----------
# Compile the graph to llvm target with given input specification.
target = "llvm"
target_host = "llvm"
ctx = tvm.cpu(0)
with tvm.transform.PassContext(opt_level=3):lib = relay.build(mod, target=target, target_host=target_host, params=params)0x04.4 在目标硬件上进行推理并输出分类结果
这里加了一个计时函数用来记录推理的耗时情况。
######################################################################
# Execute the portable graph on TVM
# ---------------------------------
# Now we can try deploying the compiled model on target.
from tvm.contrib import graph_runtimetvm_t0 = time.clock()
for i in range(10):dtype = "float32"m = graph_runtime.GraphModule(lib["default"](ctx))# Set inputsm.set_input(input_name, tvm.nd.array(img.astype(dtype)))# Executem.run()# Get outputstvm_output = m.get_output(0)
tvm_t1 = time.clock()接下来我们在1000类的字典里面查询一下Top1概率对应的类别并输出,同时也用Pytorch跑一下原始模型看看两者的结果是否一致和推理耗时情况。
#####################################################################
# Look up synset name
# -------------------
# Look up prediction top 1 index in 1000 class synset.
synset_url = "".join(["https://raw.githubusercontent.com/Cadene/","pretrained-models.pytorch/master/data/","imagenet_synsets.txt",]
)
synset_name = "imagenet_synsets.txt"
synset_path = download_testdata(synset_url, synset_name, module="data")
with open(synset_path) as f:synsets = f.readlines()synsets = [x.strip() for x in synsets]
splits = [line.split(" ") for line in synsets]
key_to_classname = {spl[0]: " ".join(spl[1:]) for spl in splits}class_url = "".join(["https://raw.githubusercontent.com/Cadene/","pretrained-models.pytorch/master/data/","imagenet_classes.txt",]
)
class_name = "imagenet_classes.txt"
class_path = download_testdata(class_url, class_name, module="data")
with open(class_path) as f:class_id_to_key = f.readlines()class_id_to_key = [x.strip() for x in class_id_to_key]# Get top-1 result for TVM
top1_tvm = np.argmax(tvm_output.asnumpy()[0])
tvm_class_key = class_id_to_key[top1_tvm]# Convert input to PyTorch variable and get PyTorch result for comparison
torch_t0 = time.clock()
for i in range(10):with torch.no_grad():torch_img = torch.from_numpy(img)output = model(torch_img)# Get top-1 result for PyTorchtop1_torch = np.argmax(output.numpy())torch_class_key = class_id_to_key[top1_torch]
torch_t1 = time.clock()tvm_time = tvm_t1 - tvm_t0
torch_time = torch_t1 - torch_t0print("Relay top-1 id: {}, class name: {}".format(top1_tvm, key_to_classname[tvm_class_key]))
print("Torch top-1 id: {}, class name: {}".format(top1_torch, key_to_classname[torch_class_key]))
print('Relay time: ', tvm_time / 10.0, 'seconds')
print('Torch time: ', torch_time / 10.0, 'seconds')0x05. 小节
这一节是对TVM的初步介绍,暂时讲到这里,后面的文章会继续深度了解和介绍深度学习编译器相关的知识。
0x06. 参考
http://tvm.apache.org/docs/tutorials/frontend/from_pytorch.html#sphx-glr-tutorials-frontend-from-pytorch-py
https://zhuanlan.zhihu.com/p/50529704
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。














![TVM[2] —— TVM简介和发展](https://img-blog.csdnimg.cn/02bb2422b78142aba58da82e9fe1b568.png#pic_center)