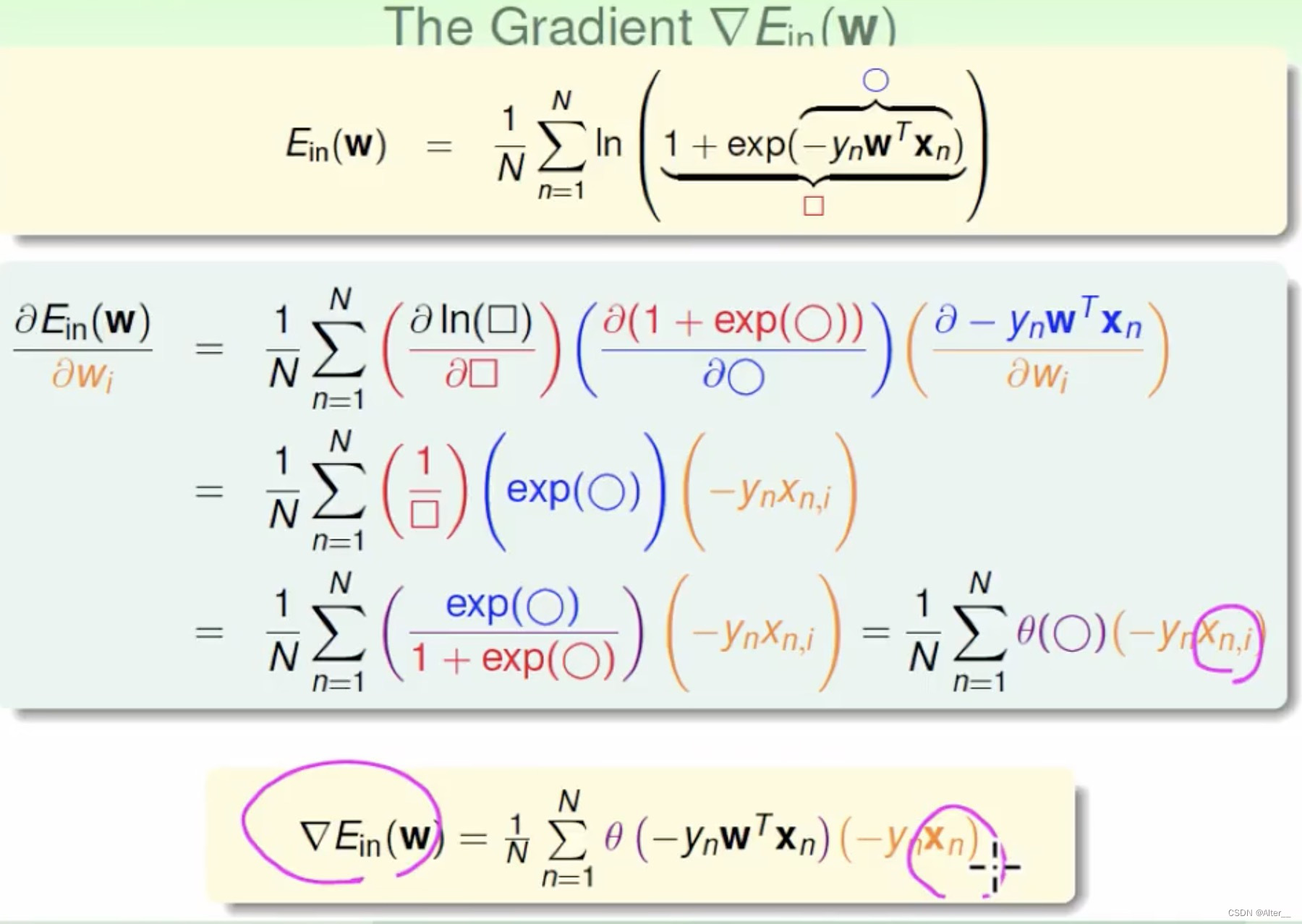
一、SolrJ介绍
1. SolrJ是什么?
Solr提供的用于JAVA应用中访问solr服务API的客户端jar。在我们的应用中引入solrj:
<dependency><groupId>org.apache.solr</groupId><artifactId>solr-solrj</artifactId><version>7.3.0</version> </dependency>
2. SolrJ的核心API
SolrClient
SolrRequest
SolrResponse

3. SolrClient 的子类
HttpSolrClient – 与指定的一个solr节点通信的客户端
LBHttpSolrClient –负载均衡地访问一组节点的客户端
CloudSolrClient – 访问solrCloud的客户端
ConcurrentUpdateSolrClient –并发更新索引用的客户端
4. 创建客户端时通用的配置选项
4.1 Base URL:
http://hostname:8983/solr/core1
http://hostname:8983/solr
4.2 Timeouts
final String solrUrl = "http://localhost:8983/solr"; return new HttpSolrClient.Builder(solrUrl).withConnectionTimeout(10000).withSocketTimeout(60000).build();
5. 用SolrJ索引文档
//获取solr客户端 final SolrClient client = getSolrClient();//创建一个solr文档doc添加字段值 final SolrInputDocument doc = new SolrInputDocument(); doc.addField("id", UUID.randomUUID().toString()); doc.addField("name", "Amazon Kindle Paperwhite");//把solr文档doc通过客户端提交到内核techproducts中去 final UpdateResponse updateResponse = client.add("techproducts", doc); // 索引文档必须被提交 client.commit("techproducts");
6. 用SolrJ查询
//获取solr客户端 final SolrClient client = getSolrClient(); //创建查询的map参数 final Map<String, String> queryParamMap = new HashMap<String, String>(); queryParamMap.put("q", "*:*"); queryParamMap.put("fl", "id, name"); queryParamMap.put("sort", "id asc"); //把查询的map参数放到MapSolrParams里面去 MapSolrParams queryParams = new MapSolrParams(queryParamMap); //通过客户端用查询参数queryParams去内核techproducts里面查询数据 final QueryResponse response = client.query("techproducts", queryParams); //从响应结果里面获取查询的document final SolrDocumentList documents = response.getResults(); out("Found " + documents.getNumFound() + " documents"); //遍历document取出结果 for(SolrDocument document : documents) {final String id = (String) document.getFirstValue("id");final String name = (String) document.getFirstValue("name");out("id: " + id + "; name: " + name); }
7. Java 对象绑定
public static class TechProduct {@Field public String id;@Field public String name;public TechProduct(String id, String name) {this.id = id; this.name = name;}public TechProduct() {} }
索引:
final SolrClient client = getSolrClient();final TechProduct kindle = new TechProduct("kindle-id-4", "Amazon Kindle Paperwhite"); final UpdateResponse response = client.addBean("techproducts", kindle);client.commit("techproducts");
查询:
final SolrClient client = getSolrClient();final SolrQuery query = new SolrQuery("*:*"); query.addField("id"); query.addField("name"); query.setSort("id", ORDER.asc);final QueryResponse response = client.query("techproducts", query); final List<TechProduct> products = response.getBeans(TechProduct.class);
8.详细API介绍
SolrClient的API
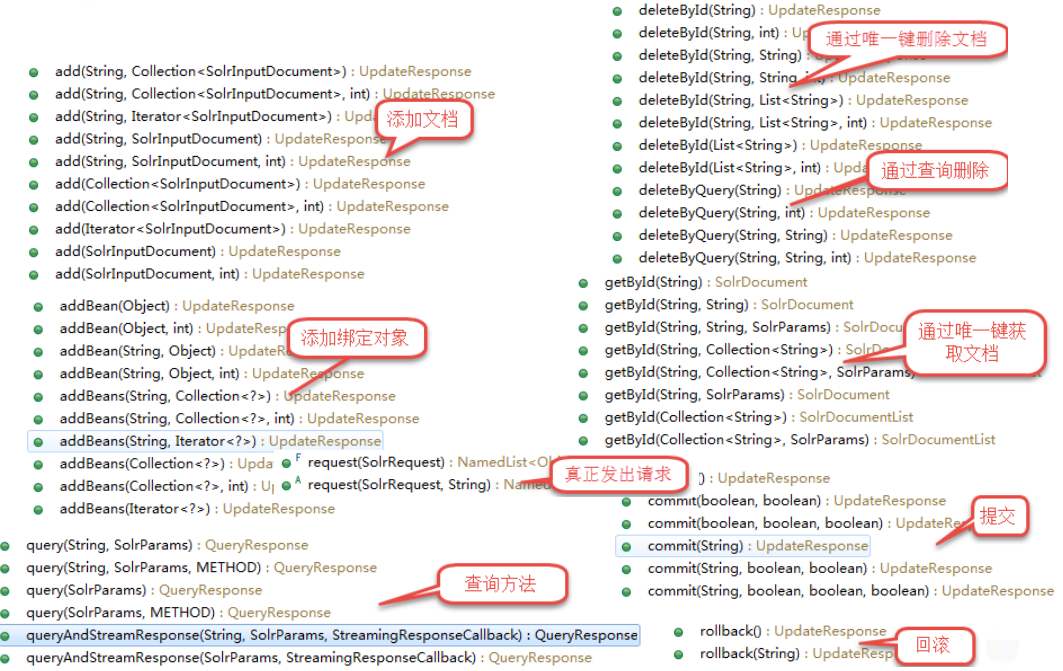
SolrRequest 的API

SolrRequest 的子类

SolrResponse 的API
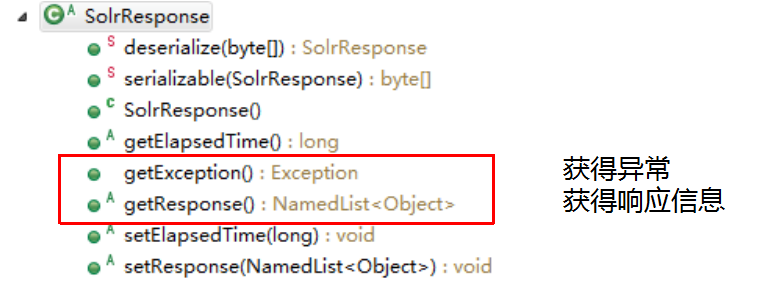
SolrResponse 的子类

9. 示例代码
package com.dongnao.solr.demo.client;import java.util.ArrayList; import java.util.List; import java.util.Optional; import java.util.UUID;import org.apache.solr.client.solrj.SolrClient; import org.apache.solr.client.solrj.impl.CloudSolrClient; import org.apache.solr.client.solrj.impl.HttpSolrClient; import org.apache.solr.client.solrj.impl.LBHttpSolrClient; import org.apache.solr.client.solrj.response.UpdateResponse; import org.apache.solr.common.SolrInputDocument;public class SolrJClientDemo {// baseSolrUrl 示例private static String baseSolrUrl = "http://localhost:8983/solr/";private static String baseSolrUrlWithCollection = "http://localhost:8983/solr/techproducts";/*** HttpSolrClient:与一个solr Server 通过http进行通信*/public static SolrClient getHttpSolrClient(String baseSolrUrl) {return new HttpSolrClient.Builder(baseSolrUrl).withConnectionTimeout(1000).withSocketTimeout(6000).build();}public static SolrClient getHttpSolrClient() {return new HttpSolrClient.Builder(baseSolrUrl).withConnectionTimeout(1000).withSocketTimeout(6000).build();}/*** LBHttpSolrClient: 负载均衡的httpSolrClient <br>* 负载均衡方式: 轮询给定的多个solr server url。* 当某个url不通时,url地址会从活跃列表移到死亡列表中,用下一个地址再次发送请求。<br>* 对于死亡列表中的url地址,会定期(默认每隔1分钟,可设置)去检测是否变活了,再加入到活跃列表中。 <br>* 注意: <br>* 1、不可用于主从结构master/slave 的索引场景,因为主从结构必须通过主节点来更新。 <br>* 2、对于SolrCloud(leader/replica),使用CloudSolrClient更好。* 在solrCloud中可用它来进行索引更新,solrCloud中的节点会将请求转发到对应的leader。*/public static SolrClient getLBHttpSolrClient(String... solrUrls) {return new LBHttpSolrClient.Builder().withBaseSolrUrls(solrUrls).build();}private static String baseSolrUrl2 = "http://localhost:7001/solr/";public static SolrClient getLBHttpSolrClient() {return new LBHttpSolrClient.Builder().withBaseSolrUrls(baseSolrUrl, baseSolrUrl2).build();}/*** 访问SolrCloud集群用CloudSolrClient<br>* CloudSolrClient 实例通过访问zookeeper得到集群中集合的节点列表,<br>* 然后通过LBHttpSolrClient来负载均衡地发送请求。<br>* 注意:这个类默认文档的唯一键字段为“id”,如果不是的,通过 setIdField(String)方法指定。*/public static SolrClient getCloudSolrClient(List<String> zkHosts,Optional<String> zkChroot) {return new CloudSolrClient.Builder(zkHosts, zkChroot).build();}private static String zkServerUrl = "localhost:9983";public static SolrClient getCloudSolrClient() {List<String> zkHosts = new ArrayList<String>();zkHosts.add(zkServerUrl);Optional<String> zkChroot = Optional.empty();return new CloudSolrClient.Builder(zkHosts, zkChroot).build();}public static void main(String[] args) throws Exception {// HttpSolrClient 示例:SolrClient client = SolrJClientDemo.getHttpSolrClient();SolrInputDocument doc = new SolrInputDocument();doc.addField("id", UUID.randomUUID().toString());doc.addField("name", "HttpSolrClient");UpdateResponse updateResponse = client.add("techproducts", doc);// 记得要提交client.commit("techproducts");System.out.println("------------ HttpSolrClient ------------");System.out.println("add doc:" + doc);System.out.println("response: " + updateResponse.getResponse());client.close();// LBHttpSolrClient 示例client = SolrJClientDemo.getLBHttpSolrClient();doc.clear();doc.addField("id", UUID.randomUUID().toString());doc.addField("name", "LBHttpSolrClient");updateResponse = client.add("techproducts", doc);// 记得要提交client.commit("techproducts");System.out.println("------------ LBHttpSolrClient ------------");System.out.println("add doc:" + doc);System.out.println("response: " + updateResponse.getResponse());client.close();// CloudSolrClient 示例client = SolrJClientDemo.getCloudSolrClient();doc.clear();doc.addField("id", UUID.randomUUID().toString());doc.addField("name", "CloudSolrClient");updateResponse = client.add("techproducts", doc);// 记得要提交client.commit("techproducts");System.out.println("------------ CloudSolrClient ------------");System.out.println("add doc:" + doc);System.out.println("response: " + updateResponse.getResponse());client.close();}}
二、索引 API 详解
1. Solr提供的数据提交方式简介
Solr中数据提交进行索引都是通过http请求,针对不同的数据源solr提供了几种方式来方便提交数据。
1.1 基于Apache Tika 的 solr cell(Solr Content Extraction Library ),来提取上传文件内容进行索引。
1.2 应用中通过Index handler(即 index API)来提交数据。
1.3 通过Data Import Handler 来提交结构化数据源的数据
2. Index handler 是什么?
Index handler 索引处理器,是一种Request handler 请求处理器。
solr对外提供http服务,每类服务在solr中都有对应的request handler来接收处理,solr中提供了默认的处理器实现,如有需要我们也可提供我们的扩展实现,并在conf/solrconfig.xml中进行配置。
在 conf/solrconfig.xml中,requestHandler的配置就像我们在web.xml中配置servlet-mapping(或spring mvc 中配置controller 的requestMap)一样:配置该集合/内核下某个请求地址的处理类。
Solrconfig中通过updateHandler元素配置了一个统一的更新请求处理器支持XML、CSV、JSON和javabean更新请求(映射地址为/update),它根据请求提交内容流的内容类型Content-Type将其委托给适当的ContentStreamLoader来解析内容,再进行索引更新。
3. 配置一个requestHandler示例
<requestHandler name=“/update" class="solr.UpdateRequestHandler" />
4. Xml 格式数据索引更新
提交操作可以在solr的web控制台中进行

请求头中设置 Content-type: application/xml or Content-type: text/xml
4.1 添加、替换文档
<add> 操作,支持两个可选属性:
commitWithin:限定在多少毫秒内完成
overwrite:指定当唯一键已存在时是否覆盖,默认true。
<add><doc><field name="authors">Patrick Eagar</field><field name="subject">Sports</field><field name="dd">796.35</field><field name="numpages">128</field><field name="desc"></field><field name="price">12.40</field><field name="title">Summer of the all-rounder</field><field name="isbn">0002166313</field><field name="yearpub">1982</field><field name="publisher">Collins</field></doc><doc>...</doc> </add>
4.2 删除文档
<delete><id>0002166313</id><id>0031745983</id><query>subject:sport</query><query>publisher:penguin</query> </delete>
<delete> 操作,支持两种删除方式:
1、根据唯一键
2、根据查询
4.3 组合操作
添加和删除文档
<update><add><doc><!-- doc 1 content --></doc></add><add><doc><!-- doc 2 content --></doc></add><delete><id>0002166313</id></delete> </update>
响应结果:Status=0表示成功 Qtime是耗时
<response><lst name="responseHeader"><int name="status">0</int><int name="QTime">127</int></lst> </response>
4.4 提交、优化、回滚操作
<commit waitSearcher="false"/> <commit waitSearcher="false" expungeDeletes="true"/> <optimize waitSearcher="false"/> <rollback/>
commit、optimize 属性说明:
waitSearcher:默认true,阻塞等待打开一个新的IndexSearcher并注册为主查询searcher,来让提交的改变可见。
expungeDeletes: (commit only) 默认false,合并删除文档量占比超过10%的段,合并过程中删除这些已删除的文档。
maxSegments: (optimize only) 默认1,优化时,将段合并为最多多少个段
5. JSON 格式数据索引更新
提交操作可以在solr的web控制台中进行
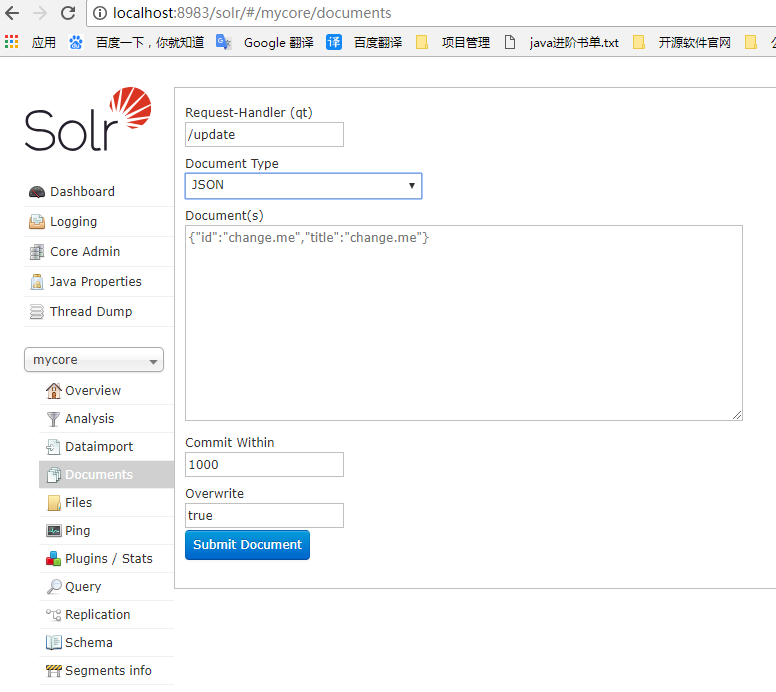
请求头中设置 Content-Type: application/json or Content-Type: text/json
5.1 添加、替换一个文档
{"id": "1","title": "Doc 1"
} 5.2 添加、替换多个文档
[{"id": "1","title": "Doc 1"},{"id": "2","title": "Doc 2"}
]
5.3 在json中指定操作
{"add": {"doc": {"id": "DOC1","my_field": 2.3,"my_multivalued_field": [ "aaa", "bbb" ] }},"add": {"commitWithin": 5000, "overwrite": false, "doc": {"f1": "v1", "f1": "v2"}},"commit": {},"optimize": { "waitSearcher":false },"delete": { "id":"ID" }, "delete": { "query":"QUERY" }
} 5.4 根据唯一键删除的简写方式
{ "delete":"myid" }
{ "delete":["id1","id2"] }
5.5 针对 JSON 格式数据提供的两个专用path
不需要在请求头中设置 Content-Type: application/json or Content-Type: text/json
/update/json
/update/json/docs 专门用于提交json格式的文档 如:product.json
三、结构化数据导入DIH
1. Solr结构化数据导入简介
Solr支持从关系数据库、基于http的数据源(如RSS和ATOM提要)、电子邮件存储库和结构化XML 中索引内容。
我们如何触发solr进行数据导入?
1.1 需要在solrconfig.xml配置一个requestHandler,通过发出http请求来触发,这个requestHander称为Data import Handler (DIH)
<requestHandler name="/dataimport" class="solr.DataImportHandler"><lst name="defaults"><str name="config">/path/to/my/DIHconfigfile.xml</str></lst> </requestHandler>
DataImportHandler这个类所在jar并没有包含在类目录中,我们需要在solrconfig.xml中引入这个jar; 它还需要一个配置文件
1.2 在solrconfig.xml中引入DataImportHandler的jar
在solrconfig.xml中找到<lib>的部分,加入下面的
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" />
solr接到请求后,它如何知道该从何处取什么数据进行索引?
这就需要一个配置文件来定义这些了:
<requestHandler name="/dataimport" class="solr.DataImportHandler"><lst name="defaults"><str name="config">dih-data-config.xml</str></lst> </requestHandler>
配置文件可以是绝对路径、或相对集合conf/的相对路径。
2. DIH 核心概念

字段对应规则说明:
1、自动进行名字相同配对;
2、对于名字不同的通过显式配置 field的column、name属性指定
配置示例:
在solr安装目录中的example/example-DIH/solr/ 下可以看到好几个导入示例
1、请查看各示例的solrconfig.xml中通过<lib>导入了哪些数据导入相关的jar。
2、请查看各示例的DIH配置文件的定义。
3、请重点看看从关系数据库导入的示例。

练习:从关系数据库导入数据到solr实践
数据库:mysql
表结构如下:
//商品表 create table t_product(prod_id varchar(64) PRIMARY key,name varchar(200) not null,simple_intro LONGTEXT,price bigint,uptime datetime,brand_id varchar(64),last_modify_time datetime ); //商品的品牌表 create table t_brand(id varchar(64) PRIMARY key,name varchar(200) not null,last_modify_time datetime ); //商品的种类表 create table t_cat(id varchar(64) PRIMARY key,name varchar(200) not null,last_modify_time datetime ); //商品和商品种类的关系映射表 create table t_prod_cat(prod_id varchar(64),cat_id varchar(64) ,last_modify_time datetime ); //初始化数据 INSERT INTO t_brand VALUES ('b01', '华为', '2018-5-17 00:00:00'); INSERT INTO t_brand VALUES ('b02', '戴尔', '2018-5-18 00:00:00');INSERT INTO t_cat VALUES ('c01', '台式机', '2018-5-17 00:00:00'); INSERT INTO t_cat VALUES ('c02', '服务器', '2018-5-17 00:00:00');INSERT INTO t_product VALUES ('tp001', '华为(HUAWEI)RH2288HV3服务器', '12盘(2*E5-2630V4 ,4*16GB ,SR430 1G,8*2TSATA,4*GE,2*460W电源,滑轨) ', 4699900, '2018-5-8 00:00:00', 'b01', '2018-5-8 00:00:00'); INSERT INTO t_product VALUES ('tp002', '戴尔 DELL R730 2U机架式服务器', '戴尔 DELL R730 2U机架式服务器(E5-2620V4*2/16G*2/2T SAS*2热/H730-1G缓存/DVDRW/750W双电/导轨)三年', 2439900, '2018-5-18 15:32:13', 'b02', '2018-5-18 17:32:23');INSERT INTO t_prod_cat VALUES ('tp001', 'c01', '2018-5-8 14:48:56'); INSERT INTO t_prod_cat VALUES ('tp001', 'c02', '2018-5-8 14:49:15'); INSERT INTO t_prod_cat VALUES ('tp002', 'c01', '2018-5-18 15:32:48'); INSERT INTO t_prod_cat VALUES ('tp002', 'c02', '2018-5-18 18:29:23');
前期准备:
1、创建一个集合或内核 myproducts,配置集用 _default。
D:\solr-7.3.0\bin>solr.cmd create -c myproducts -d _default -p 8983
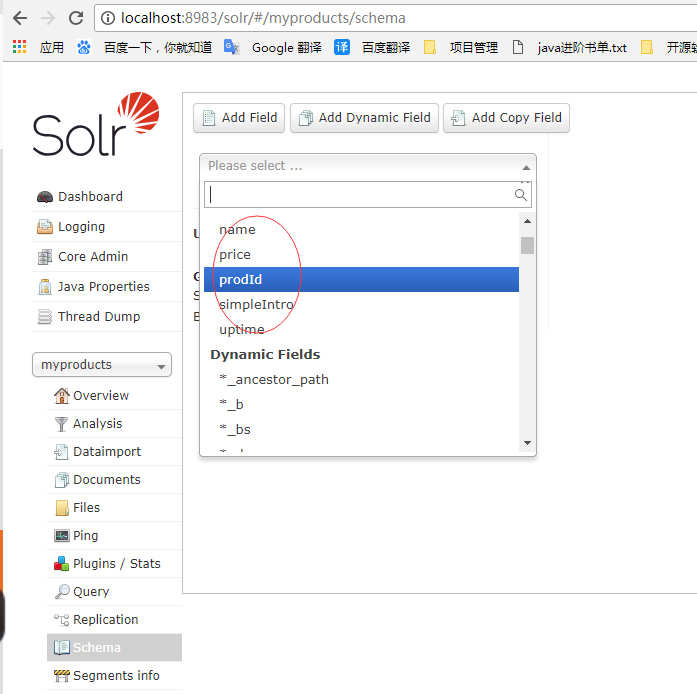
2、为myproducts添加如下字段定义(分词的要用中文分词器)。
2.1 在myproducts的D:\solr-7.3.0\server\solr\myproducts\conf\managed-schema模式文件下配置中文分词器
<!-- 自定义中文分词器 begin --><fieldType name="ik_zh_CN" class="solr.TextField"><analyzer><tokenizer class="com.study.lucene.demo.analizer.ik.IKTokenizer4Lucene7Factory" useSmart="true"/></analyzer></fieldType><!-- 自定义中文分词器 end -->
2.2 在myproducts的D:\solr-7.3.0\server\solr\myproducts\conf\managed-schema模式文件下配置如下字段
prodId:商品id,字符串,索引、存储;
name: 商品名称,字符串,分词、索引、存储
simpleIntro:商品简介,字符串,分词、索引、不存储
price:价格,整数(单位分),索引,存储
uptime:上架时间,索引、docValues 支持排序
brand:品牌,不分词、索引、docValues 支持分面查询
cat:分类,多值,不分词、索引、docValues <field name="prodId" type="string" indexed="true" stored="true" required="true" multiValued="false" /><field name="name" type="ik_zh_CN" indexed="true" stored="true" required="true" /><field name="simpleIntro" type="ik_zh_CN" indexed="true" stored="flase" /><field name="price" type="pint" indexed="true" stored="true" docValues="true" useDocValuesAsStored="true" /><field name="uptime" type="pdate" indexed="true" stored="true" docValues="true" useDocValuesAsStored="true" /><field name="brand" type="string" indexed="true" stored="true" docValues="true" useDocValuesAsStored="true" /><field name="cat" type="strings" indexed="true" stored="true" docValues="true" useDocValuesAsStored="true" />
3、将myproducts模式(D:\solr-7.3.0\server\solr\myproducts\conf\managed-schema)的唯一键字段设为 prodId。
<uniqueKey>prodId</uniqueKey>
从新加载内核myproducts可以看到配置生效了
从关系数据库导入实践-步骤
1. 拷贝mysql的驱动jar包mysql-connector-java-5.1.34_1.jar到solrD:\solr-7.3.0\server\solr-webapp\webapp\WEB-INF\lib目录下
2. 在myproducts集合的solrconfig.xml中配置<lib>和DIH
2.1 配置lib
<!--导入mysql结构化数据需要的lib包 begin --><lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" /><!--导入mysql结构化数据需要的lib包 end -->
2.2 配置DIH
<!--导入mysql结构化数据需要的DIH begin --><requestHandler name="/dataimport" class="solr.DataImportHandler"><lst name="defaults"><str name="config">db-data-config.xml</str></lst></requestHandler><!--导入mysql结构化数据需要的DIH end -->
3. 在myproducts集合的conf/目录下创建dih配置文件db-data-config.xml
3.1 配置数据源
单数据源
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost/dbname" user="db_username" password="db_password"/>
多数据源
<dataSource type="JdbcDataSource" name="ds-1" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://db1-host/dbname" user="db_username" password="db_password"/> <dataSource type="JdbcDataSource" name="ds-2" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://db2-host/dbname" user="db_username" password="db_password"/>
说明:
(1) . name、type 是通用属性,type默认是jdbcDataSource
(2) 其他属性是非固定的,不同type可有不同的属性,可随意扩展。
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/study?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT" user="root" password="123456" />
说明: serverTimezone=GMT是为解决引入最新版mysql驱动jar报时区错误而加入的连接请求参数。
3.2 . 配置document对应的实体(导入的数据)。
<document> 下可包含一个或多个 <entity>数据实体
entity 数据实体通用属性说明
name (required) : 标识实体的唯一名 processor : 当数据源是非RDBMS 时,必须指定处理器。(默认是SqlEntityProcessor) transformer : 要应用在该实体上的转换器。 dataSource : 当配置了多个数据源时,指定使用的数据源的名字。 pk : 实体的主键列名。只有在增量导入时才需要指定主键列名。和模式中的唯一键是两个不同的东西。 rootEntity : 默认document元素的子entity是rootEntity,如果把rootEntity属性设为false值,则它的子会被作为rootEntity(依次类推)。rootEntity返回的每一行会创建一个document。 onError : (abort|skip|continue) . 当处理entity的行为document的过程中发生异常该如何处理:默认是 abort,放弃导入。skip:跳过这个文档,continue:继续索引该文档。 preImportDeleteQuery : 在全量导入前,如需要进行索引清理cleanup,可以通过此属性指定一个清理的索引删除查询,否则用的是‘*:*’(删除所有)。只有<document>的直接子Entity设置此属性有效。 postImportDeleteQuery : 指定全量导入后需要进行索引清理的delete查询。只有<document>的直接子Entity设置此属性有效.
SqlEntityProcessor 的 entity 属性说明
query (required) : 从数据库中加载实体数据用的SQL语句。 deltaQuery : 仅用于增量导入,指定增量数据pk的查询SQL。 parentDeltaQuery : 指定增量关联父实体的pk的查询SQL。 deletedPkQuery :仅用于增量导入,被删除实体的pk查询SQL。 deltaImportQuery : (仅用于增量导入) .指定增量导入实体数据的查询SQL。如果没有指定该查询语句,solr将使用query属性指定的语句,经修改后来查询加载增量数据(这很容易出错)。在该语句中往往需要引用deltaQuery查询结果的列值,
通过 ${dih.delta.<column-name>} 来引用,如:select * from tbl where id=${dih.delta.id}
3.3. 在实体的query属性里面配置查询数据的SQL
7. 配置获取关联表数据
entity 关系表示
实体关系(一对一、一对多、多对一、多对多),用子实体来表示,在子实体的SQL查询语句中可用${parentEntity.columnName}来引用父实体数据的列值。
一个实体可包含多个子实体。
配置完的db-data-config.xml最终内容如下:
<dataConfig><!--配置数据源 --><dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/study?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT" user="root" password="123456" /><document><!--配置document对应的实体(导入的数据) 配置查询数据的SQL(这里偷了一下懒,用一个sql查出了需要的数据,实际上还可以通过配置子实体关联到需要的数据)--><entity name="item" pk="prodId" query="SELECTtp.prod_id prodId,tp.name prodname,tp.simple_intro simpleIntro,tp.price,tp.uptime,tb.name brand,tc.name cat FROM t_product tp LEFT JOIN t_brand tb ON tp.brand_id = tb.id LEFT JOIN t_prod_cat tpc ON tp.prod_id = tpc.prod_id INNER JOIN t_cat tc ON cat_id = tc.id GROUP BY tp.prod_id"><!--配置sql查询的列和模式里面定义字段的对应关系 begin --><field column="prodId" name="prodId" /><field column="prodname" name="name" /><field column="simpleIntro" name="simpleIntro" /><field column="price" name="price" /><field column="uptime" name="uptime" /><field column="brand" name="brand" /><field column="cat" name="cat" /><!--配置sql查询的列和模式里面定义字段的对应关系 end --></entity></document> </dataConfig>
8.在solr的web控制台从新加载集合myproducts以后执行同步,可以看到数据库的数据已经成功导入到solr里面来了
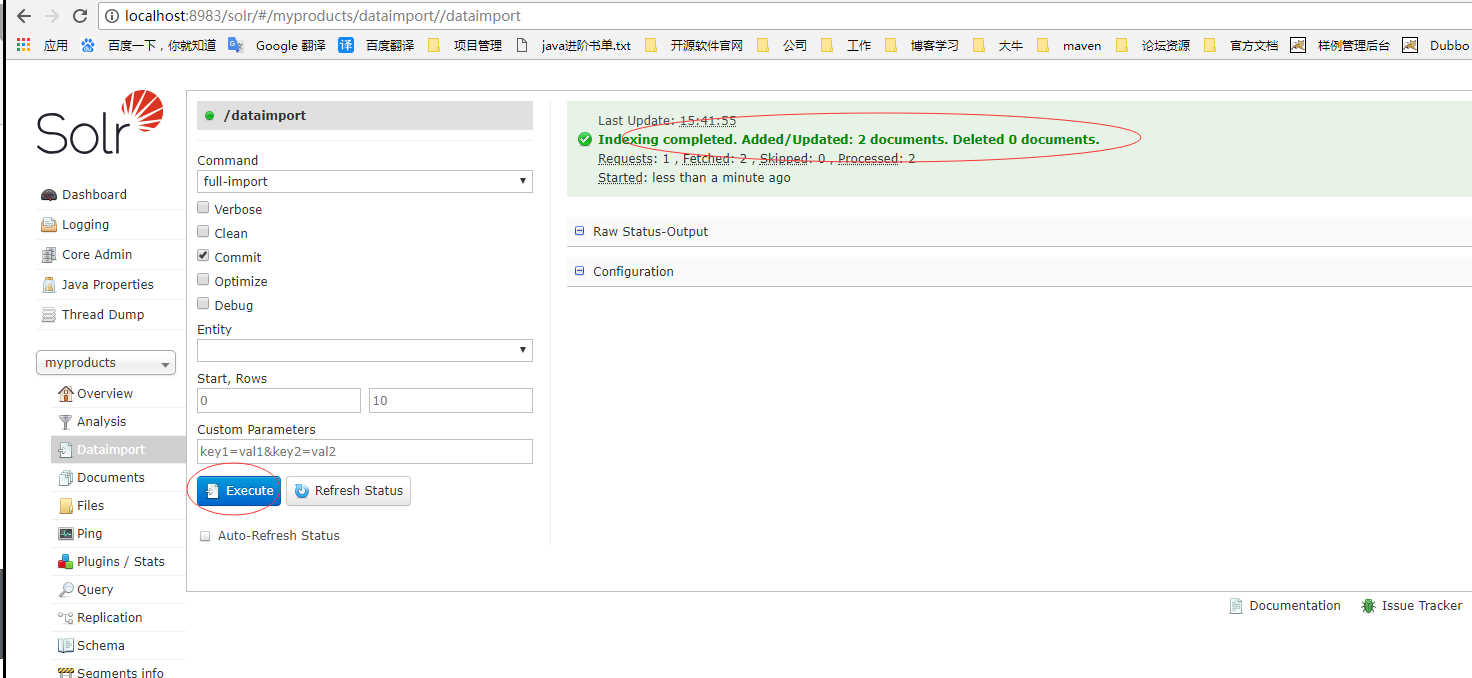
3. 增量导入中的特殊变量${dataimporter.last_index_time} 说明
这个变量是上次导入的开始时间。默认存储在conf/请求处理器名.properties文件中。我们可以在<dataConfig>下配置一个propertyWriter元素来设置它。
<propertyWriter dateFormat="yyyy-MM-dd HH:mm:ss" type="SimplePropertiesWriter" directory="data" filename="dataimport.properties" locale="en_US" />
说明:type在非cloud模式下默认是SimplePropertiesWriter,在cloud模式下默认是ZKPropertiesWriter
4. DIH配置文件中使用请求参数
如果你的DIH配置文件中需要使用请求时传人的参数,可用${dataimporter.request.paramname}表示引用请求参数。
配置示例:
<dataSource driver="org.hsqldb.jdbcDriver" url="${dataimporter.request.jdbcurl}" user="${dataimporter.request.jdbcuser}" password="${dataimporter.request.jdbcpassword}" />
请求传参示例:
http://localhost:8983/solr/dih/dataimport?command=full-import&jdbcurl=jdbc:hsqldb:./example-DIH/hsqldb/ex&jdbcuser=sa&jdbcpassword=secret
四、总结
1. Solr支持从很多种数据源导入数据
2. 实现了很多的处理器及转换器
3. 实际工作过程中如碰到了别的数据源的导入,一定要想到solr中应该有对应的解决方案。参考地址:
http://lucene.apache.org/solr/guide/7_3/uploading-structured-data-store-data-with-the-data-import-handler.html
https://wiki.apache.org/solr/DataImportHandle