(好吧,这又是一篇软文,适合初学者)
一、通用概念:
1.
有监督学习方法与非监督学习方法:
- 必须要有训练集与测试样本,模型在训练集中寻找规律,训练结束对测试样本使用这种规律进行预测【所有的回归和分类算法都属于监督学习,常见的比如:线性回归(Linear Regression), 多项式回归(Ploynomial Regression)——处理非线性, 岭回归(Ridge Regression),Lasso回归和弹性网络回归(ElasticNet Regression);朴素贝叶斯、决策树、随机森林、集成学习分类版,一些神经网络】。而非监督学习没有训练集,只有一组数据,在该组数据集内寻找规律(比如聚类算法)。
- 有监督学习的方法就是识别事物,识别的结果表现在给待识别数据加上了标签。因此训练样本集必须由带标签的样本组成。而非监督学习方法只有要分析的数据集的本身,预先没有什么标签。如果发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不予以某种预先分类标签对上号为目的。
- 非监督学习在寻找数据集中的规律性,这种规律性并不一定要达到划分数据集的目的,也就是说不一定要“分类”。
这一点是比有监督学习方法的用途要广。 譬如分析一堆数据的主分量,或分析数据集有什么特点都可以归于非监督学习方法的范畴。
- (简而言之,有训练样本的,训练集有输入有输出,就是监督型学习)。 包括所有的回归算法分类算法,比如线性回归 决策树 神经网络。无监督学习一般指的是聚类算法,我们事先不知道样本的类别,通过某种办法,把相似的样本放在一堆。
训练集只有输入没有输出是无监督,包括所有的聚类算法,比如k-means PCA gmm等
半监督学习:
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。
2.泛化:
当某一反应与某种刺激形成条件联系后,这一反应也会与其它类似的刺激形成某种程度的条件联系,这一过程称为泛化——换句话说,模型适应未知数据的能力。
3.过拟合和欠拟合:
过拟合和欠拟合是机器学习算法表现差的两大原因:
过拟合:当某个模型过度的学习训练数据中的细节和噪音,以至于模型在新的数据上表现很差,我们称过拟合发生了。这意味着训练数据中的噪音或者随机波动也被当做概念被模型学习了。而问题就在于这些概念不适用于新的数据,从而导致模型泛化性能的变差。
随着时间进行,算法不断地学习,模型在训练数据和测试数据上的错误都在不断下降。但是,如果我们学习的时间过长的话,模型在训练数据上的表现将继续下降,这是因为模型已经过拟合并且学习到了训练数据中的不恰当的细节以及噪音。同时,测试数据集上的错误率开始上升,也即是模型的泛化能力在下降。
欠拟合:欠拟合指的是模型在训练和预测时表现都不好的情况。
一个欠拟合的机器学习模型不是一个良好的模型并且由于在训练数据上表现不好
欠拟合通常不被讨论,因为给定一个评估模型表现的指标的情况下,欠拟合很容易被发现。矫正方法是继续学习并且试着更换机器学习算法。
- 过拟合:在训练数据上表现良好,在未知数据上表现差。
- 欠拟合:在训练数据和未知数据上表现都很差
实际中过拟合出现较多,欠拟合情况非常少
详细参考:http://www.cnblogs.com/nxld/p/6058782.html
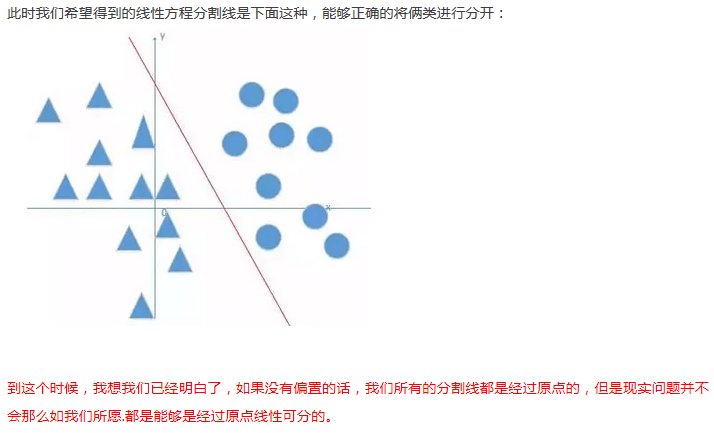
4.偏置:(有的地方也叫做截距项)
简单说就是方便进行更复杂的分类
详细参考:http://blog.csdn.net/xwd18280820053/article/details/70681750
5.
激励(活)值指的就是输出值
6.
损失函数=代价函数=误差函数
7. 阀值:
当外界刺激达到一定的阀值时,神经元才会受刺激,影响下一个神经元
8. 激活函数:
为什么要引入激活函数:http://blog.csdn.net/u010002387/article/details/52797287
不使用激励函数的话,神经网络的每层都只是做线性变换,没有激活函数网络仅是一个线性分类器。多层输入叠加后也还是线性变换。因为线性模型的表达能力不够,激励函数可以引入非线性因素。
常见的几种激活函数:
- sigmoid 函数:函数饱和使梯度消失
当函数激活值接近于0或者1时,函数的梯度接近于0。在反向传播计算梯度过程中:δ(l)=(W(l))Tδ(l+1)∗f′(z(L)),每层残差接近于0,计算出的梯度也不可避免地接近于0。这样在参数微调过程中,会引起参数弥散问题,传到前几层的梯度已经非常靠近0了,参数几乎不会再更新。
);函数不是关于原点中心对称的(这个特性会导致后面网络层的输入也不是零中心的,进而影响梯度下降的运作) - tanh 函数:同样存在饱和问题,但它的输出是零中心的,因此实际中 tanh 比 sigmoid 更受欢迎。
- ReLU函数:较于 sigmoid 和 tanh 函数,ReLU 对于 SGD 的收敛有巨大的加速作用;ReLU 的缺点是,它在训练时比较脆弱并且可能“死掉”(合理设置学习率,会降低这种情况的发生概率)
- Leaky ReLU: 解决了ReLUctant的“假死”问题,缺点是是的计算更复杂缓慢
详细参考:点击打开链接
9. 常用的数据处理方法:
- PCA:
PCA的具有2个功能,一是维数约简(可以加快算法的训练速度,减小内存消耗等),一是数据的可视化。
PCA并不是线性回归,因为线性回归是保证得到的函数是y值方面误差最小,而PCA是保证得到的函数到所降的维度上的误差最小。另外线性回归是通过x值来预测y值,而PCA中是将所有的x样本都同等对待。
在使用PCA前需要对数据进行预处理,首先是均值化,即对每个特征维,都减掉该维的平均值,然后就是将不同维的数据范围归一化到同一范围,方法一般都是除以最大值。但是比较奇怪的是,在对自然图像进行均值处理时并不是不是减去该维的平均值,而是减去这张图片本身的平均值。因为PCA的预处理是按照不同应用场合来定的。
自然图像指的是人眼经常看见的图像,其符合某些统计特征。一般实际过程中,只要是拿正常相机拍的,没有加入很多人工创作进去的图片都可以叫做是自然图片,因为很多算法对这些图片的输入类型还是比较鲁棒的。在对自然图像进行学习时,其实不需要太关注对图像做方差归一化,因为自然图像每一部分的统计特征都相似,只需做均值为0化就ok了。不过对其它的图片进行训练时,比如首先字识别等,就需要进行方差归一化了。
有一个观点需要注意,那就是PCA并不能阻止过拟合现象。表明上看PCA是降维了,因为在同样多的训练样本数据下,其特征数变少了,应该是更不容易产生过拟合现象。但是在实际操作过程中,这个方法阻止过拟合现象效果很小,主要还是通过规则项来进行阻止过拟合的。 并不是所有ML算法场合都需要使用PCA来降维,因为只有当原始的训练样本不能满足我们所需要的情况下才使用,比如说模型的训练速度,内存大小,希望可视化等。如果不需要考虑那些情况,则也不一定需要使用PCA算法了。
- 白化(Whitening):
Whitening的目的是去掉数据之间的相关联度,是很多算法进行预处理的步骤。比如说当训练图片数据时,由于图片中相邻像素值有一定的关联,所以很多信息是冗余的。这时候去相关的操作就可以采用白化操作。数据的whitening必须满足两个条件:一是不同特征间相关性最小,接近0;二是所有特征的方差相等(不一定为1)。常见的白化操作有PCA whitening和ZCA whitening。
PCA whitening是指将数据x经过PCA降维为z后,可以看出z中每一维是独立的,满足whitening白化的第一个条件,这是只需要将z中的每一维都除以标准差就得到了每一维的方差为1,也就是说方差相等。
ZCA whitening是指数据x先经过PCA变换为z,但是并不降维,因为这里是把所有的成分都选进去了。这是也同样满足whtienning的第一个条件,特征间相互独立。然后同样进行方差为1的操作,最后将得到的矩阵左乘一个特征向量矩阵U即可。
10.权值随机初始化:
“小随机数”用来保证网络不会因权值过大而进入饱和状态,从而导致训练失败;“不同”用来保证网络可以正常地学习。实际上,如果用相同的数去初始化权矩阵,则网络无能力学习
11.学习率:
实际和信号分析里的时间常数是一样的,学习率越小 学习会越精细,但同时学习速度也会降低,因为现实中很多模型都是非线性的,犹如一条曲线,梯度下降采用很多小直线迭代去逼近非线性的曲线,如果每一步跨度太大(学习率)就会失去很多曲线的扭曲信息,局部直线化过严重,跨度太小你要到达曲线的尽头就需要很多很多步,这就需要更多的样本,所以这个也要考虑实际问题再来决定学习率的。
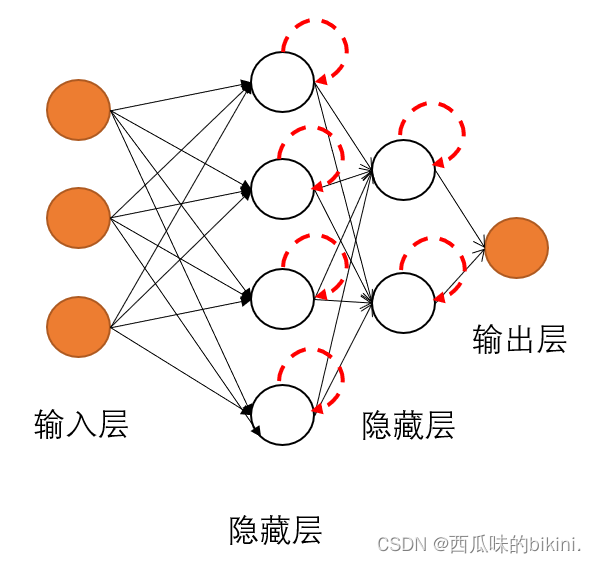
二、神经网络优缺点(BP):
1. 全连接进行大量数据的训练时太耗时太复杂
详细参考:BP神经网络优缺点
三、CNN
- 局部感受野:在一副图像中,距离较远的像素,它们的相关性一般较弱(打个比方:我们的衣领和脸),所以每个神经元没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就可得到全局信息。

- 权值共享:有的地方的特性是相似的。所以对于每个神经元,我们用同一个卷积核去卷积图像

- 多卷积核和多卷积层:权值共享虽然好,但这也就意味着这些卷积核提取的是同一个特征(说到提取的特征,与计算机视觉有关,比如锐化、边缘检测就是通过改变卷积核权值实现的),但是对于分类问题,提取一个特征肯定是远远不够的,比如判断是否是一只熊,仅仅提取出熊掌的特征是不足的,因此需要多个高级语义特征的组合,在这里就又引入了多卷积核概念。为什么CNN要设计这么多层呢?识别一个物体,CNN是从像素,边缘,局部形状一直到整体形状进行感知,也就是说它得将低级特征组合而来的高级特征在进一步变成语义特征。

- 池化层(也叫降采样层、下采样层):
压缩数据和参数的量,有减小过拟合的作用