一:Redis内存驱逐的几种策略
检测易失数据(可能会过期的数据集server.db[i].expires )
① volatile-lru:挑选最近最少使用的数据淘汰
② volatile-lfu:挑选最近使用次数最少的数据淘汰
③ volatile-ttl:挑选将要过期的数据淘汰
④ volatile-random:任意选择数据淘汰
检测全库数据(所有数据集server.db[i].dict )
⑤ allkeys-lru:挑选最近最少使用的数据淘汰
⑥ allkeys-lfu:挑选最近使用次数最少的数据淘汰
⑦ allkeys-random:任意选择数据淘汰
放弃数据驱逐
⑧ no-enviction(驱逐):禁止驱逐数据( redis4.0中默认策略),会引发错误OOM( Out Of Memory)
二:传统的LRU算法
采用map+双向链表实现。

LRU 算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
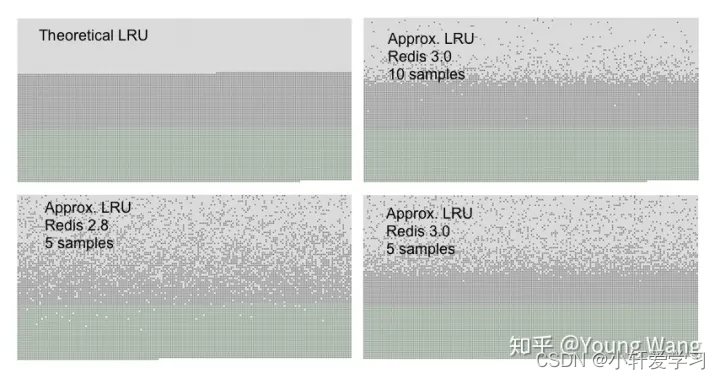
传统的lru算法是强制移除头部元素,头部元素表示最早插入并且最长时间没有使用,数据之间有严格的边界,数据分布如下图:
绿色:新加入的数据
深灰色:未删除的数据
浅灰色:已经删除的数据

- 图 1
三:Redis中的LRU
首先redis并没有使用传统的lru算法进行内存驱逐,是因为传统的lru算法需要额外的双向链表,链表本身需要记录key,还要有前指针和后指针,链表中的引用和指针和key占据的内存在链表长度过大的时候是非常恐怖的(链表的数据空间的占据甚至有可能超过数据本身!),并且这个链表如果应用在redis,可是redis服务全局的链表,链表长度可想而知,redis是基于内存的数据库,内存是宝贵的资源,为了尽可能的降低内存的使用,作者在redis实现中自己去实现了lru算法,舍弃掉了传统lru中的双向链表,但是这个lru并不是很严格,是有可能移除新插入的数据的,redis不同版本中的lru算法实现逻辑还不一样,我们分版本去讲解。
1) Redis 2.8版本中的LRU
简单说一下2.8版本中的lru实现
redis有一个24位的全局时钟,该全局时钟每一段时间会更新,每次在redis中存储/使用数据都会更新redis服务器的当前时钟至该数据,当需要内存驱逐的时候,获得当前服务器的时钟,随机抽取maxmemory-samples设置的n条数据,然后从中找到一个距离当前服务器时间戳差距最大的key,就是需要淘汰的key
图2中 5 samples为参数设置maxmemory-samples:5,刚插入的数据有可能被删除掉,所以,作者在3.0版本中又对lru做了些优化。
绿色:新加入的数据
深灰色:未删除的数据
浅灰色:已经删除的数据

2) Redis 3.0版本中的LRU
3.0版本内部维护了一个pool(大小为16),pool中的key的时钟是有序的,接下来只有小于(更早)第一个的时钟的key才能放进去,等pool满了,再次放入的时候会把最大的拿出来,该次的放进去,这样pool中维护的数据都是更加长久没有访问的,时钟更小的,等待需要逐出的时候,把pool中时钟最小的淘汰,该pool其实就是一个局部lru池。
数据分布如下图,边界相比2.8版本的较为清晰,但是相比传统lru,还是有一定差距,但是很大程度上减少了刚插入数据的淘汰。
绿色:新加入的数据
深灰色:未删除的数据
浅灰色:已经删除的数据