文章目录
- 前言
- 一、LRU是什么?
- 二、LFU是什么?
- 三、LRU和LFU的比较
- 四、LFU代码实现(看懂LFU就自然懂了LRU了)
- 1、LFU类
- 2、Node类
- 3、测试
- 写在最后,感谢点赞关注收藏转发
前言
现在缓存技术在项目中随处可见,但是有一点,毕竟缓存这个东西还是稀有的,毕竟不像硬盘资源那么广,所以缓存如何高效的使用,不浪费,及时保存热点数据那可是很重要的了。接下来带你了解下大名鼎鼎的LRU以及LFU,以及用代码是如何实现的
一、LRU是什么?
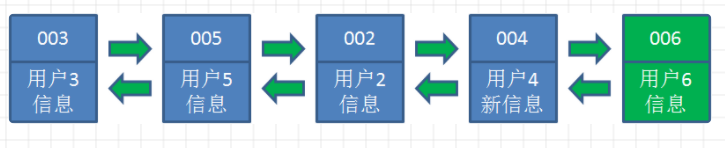
LRU全称 “Least Recently Used”,最近最少使用策略,判断最近被使用的时间,距离目前最远的数据优先被淘汰,作为一种根据访问时间来更改链表顺序从而实现缓存淘汰的算法。
简单介绍:就是经常使用的数据在链表的头部,冷数据在尾部,一旦链表容量不够(缓存空间满了),执行删除尾部策略。一般来说链表的增删是快,但是有个缺点就是查询慢,LRU为了获取元素快,肯定是不能每次逐个遍历获取的元素的,所以还有个HashMap来获取你需要的元素,复杂度O(1)。
二、LFU是什么?
LFU,全称是:Least Frequently Used,最不经常使用策略,在一段时间内,数据被使用频次最少的,优先被淘汰。最少使用(LFU)是一种用于管理计算机内存的缓存算法。主要是记录和追踪内存块的使用次数,当缓存已满并且需要更多空间时,系统将以最低内存块使用频率清除内存.采用LFU算法的最简单方法是为每个加载到缓存的块分配一个计数器。每次引用该块时,计数器将增加一。当缓存达到容量并有一个新的内存块等待插入时,系统将搜索计数器最低的块并将其从缓存中删除。redis启用回收策略就有LFU
三、LRU和LFU的比较
其实LFU比LRU多了一个就是每次添加,获取增加次数记录。在链表的开始插入元素,然后每插入一次计数一次,接着按照次数重新排序链表,如果次数相同的话,按照插入时间排序,然后从链表尾部选择淘汰的数据。
LRU和LFU侧重点不同,LRU主要体现在对元素的使用时间上,而LFU主要体现在对元素的使用频次上。LFU的缺陷是:在短期的时间内,对某些缓存的访问频次很高,这些缓存会立刻晋升为热点数据,而保证不会淘汰,这样会驻留在系统内存里面。而实际上,这部分数据只是短暂的高频率访问,之后将会长期不访问,瞬时的高频访问将会造成这部分数据的引用频率加快,而一些新加入的缓存很容易被快速删除,因为它们的引用频率很低。
四、LFU代码实现(看懂LFU就自然懂了LRU了)
1、LFU类
在这里插入代码片public class LFU<K, V> {/*** 容量*/private int capacity;private Map<K, Node> caches;/*** 添加** @param key* @param value*/public void put(K key, V value) {Node node = caches.get(key);if (node == null) {if (capacity == caches.size()) {//去除不活跃的数据K leastKey = removeLeastCount();caches.remove(leastKey);}node = new Node(key, value, System.nanoTime(), 1);caches.put(key, node);} else {node.value = value;node.setCount(node.getCount() + 1);node.setTime(System.nanoTime());}sort();}/*** 获取元素** @param key* @return*/public V get(K key) {Node node = caches.get(key);if (node != null) {node.setCount(node.getCount() + 1);node.setTime(System.nanoTime());sort();return (V) node.value;}return null;}/*** 排序*/private void sort() {List<Map.Entry<K, Node>> list = new ArrayList<>(caches.entrySet());Collections.sort(list, new Comparator<Map.Entry<K, Node>>() {@Overridepublic int compare(Map.Entry<K, Node> o1, Map.Entry<K, Node> o2) {//调用 Node重写的compable方法return o2.getValue().compareTo(o1.getValue());}});caches.clear();for (Map.Entry<K, Node> kNodeEntry : list) {caches.put(kNodeEntry.getKey(), kNodeEntry.getValue());}}/*** 移除统计数或者时间比较最小的那个** @return*/private K removeLeastCount() {Collection<Node> values = caches.values();//min 方法会调用 Node重写的compable方法Node min = Collections.min(values);return (K) min.getKey();}public LFU() {}public LFU(int size) {this.capacity = size;caches = new LinkedHashMap<>(size);}public int getCapacity() {return capacity;}public void setCapacity(int capacity) {this.capacity = capacity;}public Map<K, Node> getCaches() {return caches;}public void setCaches(Map<K, Node> caches) {this.caches = caches;}
}2、Node类
package com.cloud.order.util;public class Node implements Comparable<Node> {Object key;Object value;long time;int count;@Overridepublic int compareTo(Node o) {//在数目相同的情况下 比较时间int compare = Integer.compare(this.count, o.count);if (compare == 0) {return Long.compare(this.time, o.time);}return compare;}public Node() {}public Node(Object key, Object value, long time, int count) {this.key = key;this.value = value;this.time = time;this.count = count;}public Object getKey() {return key;}public void setKey(Object key) {this.key = key;}public Object getValue() {return value;}public void setValue(Object value) {this.value = value;}public long getTime() {return time;}public void setTime(long time) {this.time = time;}public int getCount() {return count;}public void setCount(int count) {this.count = count;}
}3、测试
package com.cloud.order.util;import java.util.Map;public class TestLru {public static void main(String[] args) {LFU<Integer, String> lfuList = new LFU<>(5);lfuList.put(1, "A");lfuList.put(2, "B");lfuList.put(3, "C");lfuList.put(4, "D");lfuList.put(5, "E");lfuList.put(6, "F");Map<Integer, Node> caches = (Map<Integer, Node>) lfuList.getCaches();for (Map.Entry<Integer, Node> nodeEntry : caches.entrySet()) {System.out.println(nodeEntry.getValue().value);}}
}写在最后,感谢点赞关注收藏转发
欢迎关注我的微信公众号 【猿之村】

来聊聊Java面试
加我的微信进一步交流和学习,微信手动搜索
【codeyuanzhicunup】添加即可
如有相关技术问题欢迎留言探讨,公众号主要用于技术分享,包括常见面试题剖析、以及源码解读、微服务框架、技术热点等。