概念
-
LRU是 Least Recently Used 的缩写,即最近最少使用页面置换算法,是为虚拟页式存储管理服务的,是根据页面调入内存后的使用情况进行决策了。由于无法预测各页面将来的使用情况,只能利用“最近的过去”作为“最近的将来”的近似,因此,LRU算法就是将最近最久未使用的页面予以淘汰。
-
操作系统里,在内存不够的场景下,淘汰旧内容的策略。LRU … Least Recent Used,淘汰掉最不经常使用的。因为计算机体系结构中,最大的最可靠的存储是硬盘,容量很大,并且内容可以固化,但是访问速度很慢,所以需要把使用的内容载入内存中;内存速度很快,但是容量有限,并且断电后内容会丢失,并且为了进一步提升性能,还有CPU内部的 L1 Cache,L2 Cache 等概念。因为速度越快的地方,它的单位成本越高,容量越小,新的内容不断被载入,旧的内容肯定要被淘汰,所以就有这样的使用背景。
原理
最近最少使用算法,核心思想是:最近使用的数据很大概率将会再次被使用。而最近一段时间都没有使用的数据,很大概率不会再使用。做法:把最长时间未被访问的数据置换出去。这种算法是完全从最近使用的时间角度去考虑的。
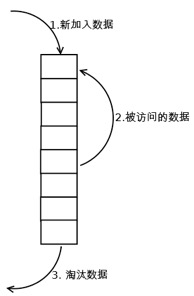
执行过程理解:
- 在缓存中查找客户端需要访问的数据 如果缓存命中,则将访问的数据中队列中取出,重新加入到缓存队列的头部。
- 如果没有命中,表示缓存穿透,将需要访问的数据从磁盘中取出,加入到缓存队列的尾部;
- 如果此时缓存满了,则需要先置换出去一个数据,淘汰队列尾部的数据,然后再在队列头部加入新数据。
存在的问题:
- 缓存污染:如果某个客户端访问大量历史数据时,可能使缓存中的数据被这些历史数据替换,其他客户端访问数据的命中率大大降低。
题目
设计和构建一个“最近最少使用”缓存,该缓存会删除最近最少使用的项目。缓存应该从键映射到值(允许你插入和检索特定键对应的值),并在初始化时指定最大容量。当缓存被填满时,它应该删除最近最少使用的项目。
它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
解题思路
LRU 总体上是这样的,最近使用的放在前边(最左边),最近没用的放到后边(最右边),来了一个新的数,如果内存满了,把旧的数淘汰掉,那位了方便移动数据,我们肯定不能考虑用数组,呼之欲出,就是使用链表了,解决方案:链表(处理新老关系)+ 哈希(查询在不在),分析如下:
- 底层应该用链表,按照数据的新旧程度来排列,旧的在左边,新的在右边,新来一个加到尾部(你可以想象自己从左往右画一条链表),删除是删头,除了这两个操作,还有就是把一个数据从中间拿出来放尾巴上(这个数组就很难做到)
- 这里还有一个需求,就是要知道这个数据有没有存在于链表中,如果不在链表中,加到尾巴即可,如果已经在链表中,就只要更细数据的位置,如何查找这个数据在不在呢,这就用哈希表。
- 考虑删除操作,要把当前节点的前一个节点的指针的改变,获取它前一个节点,方便的数据结构就是 双向链表
所以我们用的数据结构就是 LinkedList (底层是双向链表)+ HashMap,也直接用 LinkedHashMap 更为方便。看面试官要求是啥了。
ps:其实也可以用单链表,只要在 map 中不存当前节点,而是存当前节点的前驱即可。
算法实现
算法一:LinkedHashMap
class LRUCache {int capacity;Map<Integer, Integer> map;public LRUCache(int capacity) {this.capacity = capacity;map = new LinkedHashMap<>();}public int get(int key) {if (!map.containsKey(key)){return -1;}// 先删除旧的位置,再放入新位置Integer value = map.remove(key);map.put(key, value);return value;}public void put(int key, int value) {if (map.containsKey(key)){map.remove(key);map.put(key, value);return;}map.put(key, value);// 超出capacity,删除最久没用的,利用迭代器删除第一个if(map.size() > capacity){map.remove(map.entrySet().iterator().next().getKey());}}
}/*** Your LRUCache object will be instantiated and called as such:* LRUCache obj = new LRUCache(capacity);* int param_1 = obj.get(key);* obj.put(key,value);*/
算法二:双链表+HashMap
class LRUCache {//定义双向链表节点public class ListNode{int key;int value;ListNode pre;ListNode next;public ListNode(int key, int value){this.key = key;this.value = value;pre = null;next = null;}}private int capacity;private Map<Integer, ListNode> map;private ListNode head;private ListNode tail;public LRUCache(int capacity) {this.capacity = capacity;map = new HashMap<>();head = new ListNode(-1, -1);tail = new ListNode(-1, -1);head.next = tail;tail.pre = head;}public int get(int key) {if(!map.containsKey(key)) {return -1;}ListNode node = map.get(key);// 先删除该节点,再接到尾部node.pre.next = node.next;node.next.pre = node.pre;moveToTail(node);return node.value;}public void put(int key, int value) {// 直接调用这边的get方法,如果存在,它会在get内部被移动到尾巴,不用再移动一遍,直接修改值即可if(get(key) != -1) {map.get(key).value = value;return;}// 若不存在,new一个出来,如果超出容量,把头去掉ListNode node = new ListNode(key, value);map.put(key, node);moveToTail(node);if(map.size() > capacity) {map.remove(head.next.key);head.next = head.next.next;head.next.pre = head;}}// 把节点移动到尾巴private void moveToTail(ListNode node) {node.pre = tail.pre;tail.pre = node;node.pre.next = node;node.next = tail;}
}/*** Your LRUCache object will be instantiated and called as such:* LRUCache obj = new LRUCache(capacity);* int param_1 = obj.get(key);* obj.put(key,value);*/
算法三:单链表
class LRUCache {// 定义单链表节点private class ListNode{int key;int value;ListNode next;public ListNode(int key, int value){this.key = key;this.value = value;this.next = null;}}private int capacity;private Map<Integer, ListNode> map;private ListNode head;private ListNode tail;public LRUCache(int capacity) {this.capacity = capacity;map = new HashMap<>();head = new ListNode(-1, -1);tail = head;}public int get(int key) {if(!map.containsKey(key)){return -1;}// map中存放的是要找的节点的前驱ListNode pre = map.get(key);ListNode cur = pre.next;// 把当前节点删掉并移到尾部if(cur != tail){pre.next = cur.next;// 更新它后面 node 的前驱map.put(cur.next.key, pre);map.put(cur.key, tail);moveToTail(cur);}return cur.value;}public void put(int key, int value) {if(get(key) != -1){map.get(key).next.value = value;return;}// 若不存在则 new 一个ListNode node = new ListNode(key, value);// 当前 node 的 pre 是 tailmap.put(key, tail);moveToTail(node);if(map.size() > capacity){map.remove(head.next.key);map.put(head.next.next.key, head);head.next = head.next.next;}}public void moveToTail(ListNode node){node.next = null;tail.next = node;tail = tail.next;}
}
LRU 在 MySQL 中的应用
MySQL 中的 Buffer Pool 也是用来加速查询的缓存,当 Buffer Pool的容量被占满时,也需要淘汰数据,其中数据的淘汰也是基于LRU算法的。
所有从磁盘上读取的数据首先都会缓存在 Buffer Pool中。当对存放大量冷数据的表进行查询时,会在短时间内将大量冷数据加载到 Buffer Pool 中,如果 Buffer Pool 被占满之后就会根据 LRU 算法淘汰数据,可能就把之间的热点数据淘汰了,从而导致的缓存命中率下降。
为了避免因为冷数据表的查询导致热点数据被淘汰的问题,MySQL 对 LRU 算法进行了改进,将 Buffer Pool 分成 young 和 old 两个区域,所有数据被加载进 Buffer Pool 时都是先放在 old 区,当在 old 区待足够长的时间或被访问次数达到阈值时数据才会被放到 young 区。数据淘汰也是优先从 old 区淘汰。这样就能避免大量冷数据加载导致的热点数据淘汰问题。
LRU 在 Redis 中的应用
Redis 中淘汰数据有两个方式:
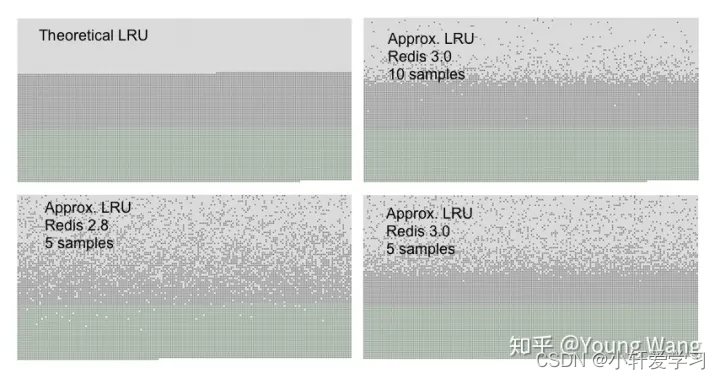
- 定期删除:Redis 有后台线程,会定时扫描数据,从中选择应该淘汰的过期数据将其删除。假如每次删除都对所有的 key 进行一次最近访问时间排序的话,对性能消耗非常大,Redis 采用的是随机抽样的方式进行删除,例如 LRU 算法删除,则随机抽取 20 个 key,从中找出最近未访问的 key 进行删除。这样随机抽取能提高性能,但是不能覆盖到所有的 key,会存在一个问题,对于设计了过期时间的数据,理论上来说应该将其删除,但是多次随机抽取均为选中,因此未被淘汰。
- 惰性删除:针对定期删除不能完全淘汰所有应该淘汰的数据的问题,当 Redis 访问了 key 之后,Redis 会判断 key 是否已经过期,如果已经过期就直接删掉。
Redis 的6种内存淘汰策略,设置参数: maxmemory-policy noeviction, 内存设置参数: maxmemory
- noenviction:默认策略,写请求失败,读请求正常,del 请求正常;
- volatile-lru:在设置了过期键的键空间中移除最近最少使用的 key;
- volatile-random:在设置过过期键的键空间中随机移除部分 key;
- volatile-ttl:在设置过期键的键空间中挑选将要过期的数据淘汰;
- allkeys-lru:在所有键空间中移除最近最少使用的可以;
- allkeys-random:在所有键空间中随机移除部分随机移除部分 key;
实际应用
LRU 算法也可以用于一些实际的应用中,如你要做一个浏览器,或类似于淘宝客户端的应用的就要用到这个原理。大家都知道浏览器在浏览网页的时候会把下载的图片临时保存在本机的一个文件夹里,下次再访问时就会,直接从本机临时文件夹里读取。但保存图片的临时文件夹是有一定容量限制的,如果你浏览的网页太多,就会一些你最不常使用的图像删除掉,只保留最近最久使用的一些图片。这时就可以用到 LRU 算法 了,这时上面算法里的这个特殊的栈就不是保存页面的序号了,而是每个图片的序号或大小;所以上面这个栈的元素都用 Object 类来表示,这样的话这个栈就可以保存的对象了。
漫画图解



用户信息当然是存在数据库里。但是由于我们对用户系统的性能要求比较高,显然不能每一次请求都去查询数据库。所以,在内存中创建了一个哈希表作为缓存,每次查找一个用户的时候先在哈希表中查询,以此提高访问性能。









让我们以用户信息的需求为例,来演示一下 LRU 算法的基本思路:
-
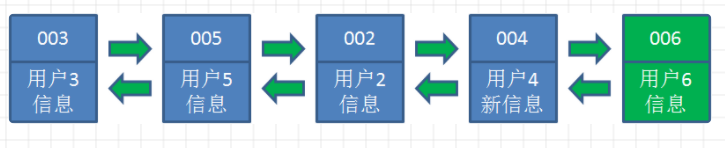
假设我们使用哈希链表来缓存用户信息,目前缓存了 4个用户,这 4 个用户是按照时间顺序依次从链表右端插入的。
-
业务方访问用户 5,由于哈希链表中没有用户 5 的数据,我们从数据库中读取出来,插入到缓存当中。这时候,链表中最右端是最新访问到的用户 5,最左端是最近最少访问的用户 1。

-
业务方访问用户 2,哈希链表中存在用户 2 的数据,我们怎么做呢?我们把用户 2 从它的前驱节点和后继节点之间移除,重新插入到链表最右端。这时候,链表中最右端变成了最新访问到的用户 2,最左端仍然是最近最少访问的用户 1。


-
业务方请求修改用户 4 的信息。同样道理,我们把用户 4 从原来的位置移动到链表最右侧,并把用户信息的值更新。这时候,链表中最右端是最新访问到的用户 4,最左端仍然是最近最少访问的用户 1。


5.后来业务方换口味了,访问用户 6,用户 6 在缓存里没有,需要插入到哈希链表。假设这时候缓存容量已经达到上限,必须先删除最近最少访问的数据,那么位于哈希链表最左端的用户1就会被删除掉,然后再把用户 6 插入到最右端。


参考链接
LRU算法思想及手写LRU实现
全面讲解LRU算法
漫画:什么是LRU算法?