在最近几十年操作系统的发展过程中,有很多页面交换算法,其中每个算法都有各自的优点和缺点。linux内核中采用的页面交换算法主要是LRU算法和第二次机会法(second chance)。
-
LRU链表
LRU是least recently used(最近最少使用)的缩写,LRU假定最近不使用的页在较短的时间内也不会频繁使用。在内存不足时,这些页面将成为被换出的候选者。内核使用双向链表来定义LRU链表,并且根据页面的类型分为LRU_ANON和LRU_FILE。每种类型根据页面的活跃分为活跃LRU和不活跃LRU,所以内核中一共有如下5个LRU链表。
-
不活跃匿名页面链表LRU_INACTIVE_ANON
-
活跃匿名页面链表LRU_ACTIVE_ANON
-
不活跃文件映射页面链表LRU_INACTIVE_FILE
-
活跃文件映射页面链表LRU_ACTIVE_FILE
-
不可回收页面链表LRU_UNEVICTABLE
LRU链表之所以要分成这样,是因为当内存紧缺时总是优先换出page cache页面,而不是匿名页面。因为大多数情况page cache页面下不需要回写磁盘,除非页面内容被修改,而匿名页面总是要被写入交换分区才能被换出。LRU链表按照zone来配置(在linux4.8内核中已改为基于node的LRU链表),也就是每个zone中都有一整套LRU链表,因此zone数据结构中有一个成员lruvec指向这些链表。枚举类型变量lru_list列举出上述各种LRU链表的类型,struct lruvec 数据结构中定义了上述各种LRU类型的链表。
[include/linux/mmzone.h]
#define LRU_BASE 0
#define LRU_ACTIVE 1
#define LRU_FILE 2enum lru_list {LRU_INACTIVE_ANON = LRU_BASE, //0LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE, //1LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE, //2LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE, //3LRU_UNEVICTABLE, //4NR_LRU_LISTS //5
};
struct lruvec {struct list_head lists[NR_LRU_LISTS];struct zone_reclaim_stat reclaim_stat;
#ifdef CONFIG_MEMCGstruct zone *zone;
#endif
};
struct zone {....../* Fields commonly accessed by the page reclaim scanner */spinlock_t lru_lock;struct lruvec lruvec;.......
}LRU链表是如何实现页面老化的呢?
这需要从页面如何加入LRU链表,以及LRU链表摘取页面说起。加入LRU链表的常用API是lru_cache_add().
lru_cache_add()->__lru_cache_add()
void lru_cache_add(struct page *page)
{VM_BUG_ON_PAGE(PageActive(page) && PageUnevictable(page), page);VM_BUG_ON_PAGE(PageLRU(page), page);__lru_cache_add(page);
}
/*这里使用了页向量(pagevec)数据结构,借助一个数组来保存特定数目的页,可以对这些页面执行同样
的操作。页向量会以"批处理的方式"执行,比单独处理一个页的方式效率要高,查看下面页向量数据结构*/
static void __lru_cache_add(struct page *page)
{/*lru_add_pvec是从哪里来的页呢?*/struct pagevec *pvec = &get_cpu_var(lru_add_pvec);page_cache_get(page);/*判断页向量pagevec是否还有空间,如果没有空间,那么首先调用__pagevec_lru_add()函数把原有的page加入到LRU链表中,然后把新页面添加到页向量pagevec中*/if (!pagevec_space(pvec)){/*下面查看__pagevec_lru_add实现:将原有的page加入到LRU链表*/__pagevec_lru_add(pvec);}/*将新页面添加到页向量pagevec*/pagevec_add(pvec, page);put_cpu_var(lru_add_pvec);
}页向量数据结构定义:
/* 14 pointers + two long's align the pagevec structure to a power of two */
#define PAGEVEC_SIZE 14
struct pagevec {unsigned long nr;/*已经使用的空间,剩余的空间 = PAGEVEC_SIZE - nr*/unsigned long cold;struct page *pages[PAGEVEC_SIZE];
};
回到__lru_cache_add()函数__pagevec_lru_add函数:把原有的page添加到LRU
并例举出了相关的函数__pagevec_lru_add_fn()和pagevec_lru_move_fn()
/** Add the passed pages to the LRU, then drop the caller's refcount* on them. Reinitialises the caller's pagevec.*/
void __pagevec_lru_add(struct pagevec *pvec)
{/*注意__pagevec_lru_add_fn回调函数*/pagevec_lru_move_fn(pvec, __pagevec_lru_add_fn, NULL);
}static void pagevec_lru_move_fn(struct pagevec *pvec,void (*move_fn)(struct page *page, struct lruvec *lruvec, void *arg),void *arg)
{int i;struct zone *zone = NULL;struct lruvec *lruvec;unsigned long flags = 0;/*遍历页向量,将所有的页加入到LRU*/for (i = 0; i < pagevec_count(pvec); i++) {struct page *page = pvec->pages[i];struct zone *pagezone = page_zone(page);if (pagezone != zone) {if (zone)spin_unlock_irqrestore(&zone->lru_lock, flags);zone = pagezone;spin_lock_irqsave(&zone->lru_lock, flags);}lruvec = mem_cgroup_page_lruvec(page, zone);/*调用__pagevec_lru_add_fn函数,将页加入到LRU*/(*move_fn)(page, lruvec, arg);}if (zone)spin_unlock_irqrestore(&zone->lru_lock, flags);release_pages(pvec->pages, pvec->nr, pvec->cold);pagevec_reinit(pvec);
}static void __pagevec_lru_add_fn(struct page *page, struct lruvec *lruvec,void *arg)
{int file = page_is_file_cache(page);int active = PageActive(page);enum lru_list lru = page_lru(page);VM_BUG_ON_PAGE(PageLRU(page), page);SetPageLRU(page);add_page_to_lru_list(page, lruvec, lru);update_page_reclaim_stat(lruvec, file, active);trace_mm_lru_insertion(page, lru);
}static __always_inline void add_page_to_lru_list(struct page *page,struct lruvec *lruvec, enum lru_list lru)
{int nr_pages = hpage_nr_pages(page);mem_cgroup_update_lru_size(lruvec, lru, nr_pages);/*加入到LRU中,并且是将成员加入到了链表头*/list_add(&page->lru, &lruvec->lists[lru]);__mod_zone_page_state(lruvec_zone(lruvec), NR_LRU_BASE + lru, nr_pages);
}
不用回到__lru_cache_add()函数,继续往下lru_to_page(&lru_list)和list_del(&page->lru)函数组合实现从LRU链表摘取页面,其中lru_to_page()的实现如下:
[mm/vmscan.c]
#define lru_to_page(_head) (list_entry((_head)->prev, struct page, lru))
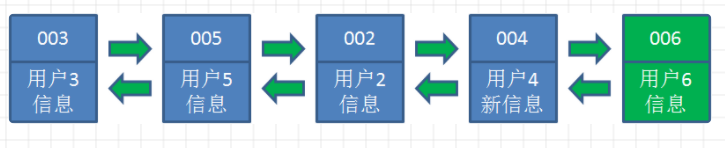
lru_to_page()使用了head->prev,从链表的末尾摘取页面,因此,LRU链表实现了先进先出(FIFO)算法。最先进入LRU的链表的页面,在LRU宏的时间会越长,老化时间也越长。
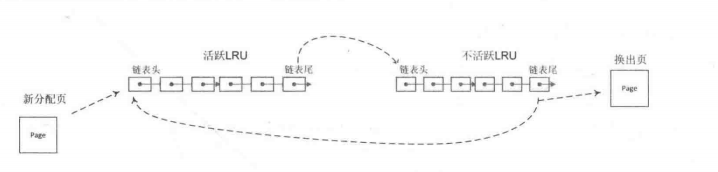
在系统运行过程中,页面总是在活跃LRU链表和不活跃LRU链表之间转移,不是每次访问内存页面都会发生这种转移。而是发生的时间间隔比较长,随着时间的推移,导致一种热平衡,最不常用的页面将慢慢移动到不活跃LRU链表的末尾,这些页面正是页面回收最合适的候选者。
经典LRU链表算法如下图:
2. 第二次机会法
第二次机会法(second chance)在经典LRU算法基础上做了一些改进。在经典LRU链表(FIFO)中,新产生的页面加入到LRU链表的开头,将LRU链表中现存的页面向后移动了一个位置。当系统内存短缺时,LRU链表尾部的页面将会离开被换出。当系统再需要这些页面时,这些页面会重新置于LRU链表的开头。显然这个设计不是很巧妙,在换出页面时,没有考虑该页面的使用情况是频繁使用,还是很少使用。也就是说,频繁使用的页面依然会在LRU链表末尾而被换出。
第二次机会算法的改进是为了避免把经常使用的页面置换出去。当选择置换页面时,依然和LRU算法一样,选择最早置入链表的页面,即在链表末尾的页面。二次机会法设置了一个访问状态位( 硬件控制的比特位,对于linux内核来说,PTE_YOUNG标志位是硬件的比特位,PG_active和PG_referenced是软件比特位),所以要检查页面的访问位。如果访问位是0,就淘汰这页面;如果访问位是1,就给它第二次机会,并选择下一个页面来换出。当该页面得到第二次机会时,它的访问位被清0,如果该页在此期间再次被访问过,则访问位置为1。这样给了第二次机会的页面将不会被淘汰,直至所有其他页面被淘汰过(或者也给了第二次机会)。因此,如果一个页面经常被使用,其访问位总保持为1,它一直不会被淘汰出去。
Linux内核使用PG_active和PG_referenced这两个标志位来实现第二次机会法。PG_active表示该页是否活跃,PG_referenced表示该页是否被引用过,主要函数如下:
-
mark_page_accessed() 标记此页面活跃 mm/swap.c
-
page_referenced() 判断page是否被访问引用过,返回的访问引用pte的个数 mm/rmap.c
-
page_check_references() mm/vmscan.c
3. mark_page_accessed()函数:标记此页面活跃
此函数实现
/** Mark a page as having seen activity.** inactive,unreferenced -> inactive,referenced* inactive,referenced -> active,unreferenced* active,unreferenced -> active,referenced** When a newly allocated page is not yet visible, so safe for non-atomic ops,* __SetPageReferenced(page) may be substituted for mark_page_accessed(page).*/
/*此函数的逻辑
(1) 如果PG_active == 0 && PG_referenced == 1 则:
把该页加入活跃LRU,并设置PG_active = 1
清PG_referenced标志位
(2) 如果PG_referenced == 0, 则:设置PG_referenced标志位
*/
void mark_page_accessed(struct page *page)
{/*PageUnevictable()判断页面不可以回收*/if (!PageActive(page) && !PageUnevictable(page) &&PageReferenced(page)) {/** If the page is on the LRU, queue it for activation via* activate_page_pvecs. Otherwise, assume the page is on a* pagevec, mark it active and it'll be moved to the active* LRU on the next drain.*/if (PageLRU(page))activate_page(page);else__lru_cache_activate_page(page);ClearPageReferenced(page);if (page_is_file_cache(page))workingset_activation(page);} else if (!PageReferenced(page)) {SetPageReferenced(page);}
}4. page_check_references()函数: 扫描不活跃LRU链表时,此函数会被调用,返回值为一个page_references的枚举类型
enum page_references {PAGEREF_RECLAIM, //表示可以尝试回收该页面PAGEREF_RECLAIM_CLEAN,//表示可以尝试回收该页面PAGEREF_KEEP, //表示会继续保留在不活跃链表中PAGEREF_ACTIVATE, //表示该页面会迁移到活跃链表
};
/*在扫描不活跃LRU链表时,此函数会被调用,返回值为一个page_references的枚举类型*/
static enum page_references page_check_references(struct page *page,struct scan_control *sc)
{int referenced_ptes, referenced_page;unsigned long vm_flags;/*page_referenced()检查该页有多少个访问引用pte(referenced_ptes)*/referenced_ptes = page_referenced(page, 1, sc->target_mem_cgroup,&vm_flags);/*TestClearPageReferenced()返回该页面PG_referenced标志位的值,并且清除该标志位*/referenced_page = TestClearPageReferenced(page);/** Mlock lost the isolation race with us. Let try_to_unmap()* move the page to the unevictable list.*/if (vm_flags & VM_LOCKED)return PAGEREF_RECLAIM;/*根据访问引用pte的数目(referenced_ptes变量)和PG_referenced标志位状态(referenced_page变量)来判断该页是留在活跃LRU、不活跃LRU,还是可以被回收。当该页有访问引用pte时,要被放回到活跃LRU链表中的情况如下:(1) 该页是匿名页面(PageSwapBacked(page))(2) 最近第二次访问的page cache 或共享的page cache(3) 可执行文件的page cache其余的有访问引用的页面将会继续保持在不活跃LRU链表中,最后剩下的页面就是可以回收页面的最佳候选者。
*/if (referenced_ptes) {if (PageSwapBacked(page)) /*该页面是匿名页面,直接放到活跃链表*/return PAGEREF_ACTIVATE;/* 如果有大量只访问一次的page cache充斥在活跃LRU链表中,那么在负载比较重的情况下,选择一个合适回收的候选者会变得越来越困难,并且引发分配内存的高延迟,将错误的页面换出。这里的设计是为了优化系统充斥着大量只使用一次的page cache页面的情况(通常是mmap映射的文件访问),在这种情况下,只访问一次的page cache页面涌入活跃LRU链表中,因为shrink_inactive_list()会把这些页面迁移到活跃链表,不利于页面回收。mmap映射的文件访问通常通过filemap_fault()函数产生page cache,在linux2.6.29以前的版本中,这些page cache将不会再调用mark_page_accessed()来设置PG_referenced。因此对于这种页面,第一次访问的状态是有访问引用pte,但是PG_referenced = 0,所以扫描不活跃链表时设置该页为PG_referenced,并且继续保留在不活跃链表中而没有被放入活跃链表。在第二次访问时,发现有访问引用pte但PG_referenced = 1,这时才把该页加入活跃链表中。因此利用PG_referenced做了一个page cache的访问次数的过滤器,过滤掉大量的短时间(多了一个不活跃链表老化的时间)只访问一次的page cache。这样在内存短缺的情况下,kswapd就巧妙地释放了大量短时间只访问一次的page cache。这种大量只访问一个的page cache在不活跃LRU链表中多待一点时间,就越有利于在系统内存短缺时首先把它们释放了,否者这些页面跑到活跃LRU链表,再想把它们释放,那么要经历一个:活跃LRU链表遍历时间+不活跃LRU链表遍历时间*/SetPageReferenced(page);/*referenced_ptes > 1 表示那些第一次在不活跃LRU链表中shared page cache,也就是说如果有多个文件同时映射到该页面,它们应该晋升到活跃LRU链表中。因为它们应该多在LRU链表中一点时间,以便其他用户可以再次访问到。*/if (referenced_page || referenced_ptes > 1)return PAGEREF_ACTIVATE;/** Activate file-backed executable pages after first usage.*/if (vm_flags & VM_EXEC)return PAGEREF_ACTIVATE;return PAGEREF_KEEP;}/* Reclaim if clean, defer dirty pages to writeback */if (referenced_page && !PageSwapBacked(page))return PAGEREF_RECLAIM_CLEAN;return PAGEREF_RECLAIM;
}
总结page_check_references()函数的主要作用如下:
(1) 如果有访问引用pte,那么:
-
该页是匿名页面(PageSwapBacked(page)),则加入活跃链表;
-
最近第二次访问(根据PG_referenced来确定,防止只访问一次的page cache跑到活跃链表)的page cache或shared page cache,则加入活跃链表;
-
可执行文件的page cache,则加入活跃链表;
-
除上述三种情况外,继续留在不活跃链表,例如第一次访问的page cache。
(2) 如果没有访问引用pte,则表示可以尝试回收它。
5. page_referenced()函数:判断page是否被访问引用过,返回的访问引用pte的次数
page->_mapcount已经统计了page被pte引用的次数,为什么还要调用page_refrenced()函数来重新统计page被pte引用的次数呢?
原因是在page_referenced()函数中会去判断此页面最近是否被访问过,并且最近访问的情况不是顺序读,才会被算做一次pte的引用次数,可以防止大量一次访问的page cache充斥到活跃LRU链表。
[page_check_references()->page_referenced()]
/*** page_referenced - test if the page was referenced* @page: the page to test* @is_locked: caller holds lock on the page* @memcg: target memory cgroup* @vm_flags: collect encountered vma->vm_flags who actually referenced the page** Quick test_and_clear_referenced for all mappings to a page,* returns the number of ptes which referenced the page.*/
/*判断page是否被访问引用过,返回的访问引用pte的个数,即访问和引用(referenced)这个页面的用户进程
空间虚拟页面的个数。核心思想是利用反向映射系统来统计访问引用pte的用户个数。*/
int page_referenced(struct page *page,int is_locked,struct mem_cgroup *memcg,unsigned long *vm_flags)
{int ret;int we_locked = 0;struct page_referenced_arg pra = {.mapcount = page_mapcount(page),.memcg = memcg,};struct rmap_walk_control rwc = {.rmap_one = page_referenced_one,.arg = (void *)&pra,.anon_lock = page_lock_anon_vma_read,};*vm_flags = 0;/*判断page->_mapcount引用是否大于0*/if (!page_mapped(page))return 0;/*判断page->mapping是否有地址空间映射*/if (!page_rmapping(page))return 0;if (!is_locked && (!PageAnon(page) || PageKsm(page))) {we_locked = trylock_page(page);if (!we_locked)return 1;}/** If we are reclaiming on behalf of a cgroup, skip* counting on behalf of references from different* cgroups*/if (memcg) {rwc.invalid_vma = invalid_page_referenced_vma;}/*rmap_walk()遍历该页面所有映射的pte,然后调用rmap_one()函数,下面查看rmap_one函数实现,即page_referenced_one*/ret = rmap_walk(page, &rwc);*vm_flags = pra.vm_flags;if (we_locked)unlock_page(page);return pra.referenced;
}
rmap_walk()函数实现
[shrink_active_list()->page_referenced()->rmap_walk()]
int rmap_walk(struct page *page, struct rmap_walk_control *rwc)
{if (unlikely(PageKsm(page)))return rmap_walk_ksm(page, rwc);else if (PageAnon(page))return rmap_walk_anon(page, rwc);elsereturn rmap_walk_file(page, rwc);
}page_referenced_one函数
[shrink_active_list()->page_referenced()->rmap_walk()->rmap_one()即page_referenced_one]
/** arg: page_referenced_arg will be passed*/
static int page_referenced_one(struct page *page, struct vm_area_struct *vma,unsigned long address, void *arg)
{struct mm_struct *mm = vma->vm_mm;spinlock_t *ptl;int referenced = 0;struct page_referenced_arg *pra = arg;/*忽略huge*/if (unlikely(PageTransHuge(page))) {pmd_t *pmd;/** rmap might return false positives; we must filter* these out using page_check_address_pmd().*/pmd = page_check_address_pmd(page, mm, address,PAGE_CHECK_ADDRESS_PMD_FLAG, &ptl);if (!pmd)return SWAP_AGAIN;if (vma->vm_flags & VM_LOCKED) {spin_unlock(ptl);pra->vm_flags |= VM_LOCKED;return SWAP_FAIL; /* To break the loop */}/* go ahead even if the pmd is pmd_trans_splitting() */if (pmdp_clear_flush_young_notify(vma, address, pmd))referenced++;spin_unlock(ptl);} else {pte_t *pte;/** rmap might return false positives; we must filter* these out using page_check_address().*//*由mm和addr获取pte*/pte = page_check_address(page, mm, address, &ptl, 0);if (!pte)return SWAP_AGAIN;if (vma->vm_flags & VM_LOCKED) {pte_unmap_unlock(pte, ptl);pra->vm_flags |= VM_LOCKED;return SWAP_FAIL; /* To break the loop */}/*判断该pte entry最近是否被访问过,如果访问过,L_PTE_YOUNG比特位会被自动置位,并清空PTE中的L_PTE_YOUNG比特位。在x86处理器中指的是_PAGE_ACCESSED比特位,在ARM32 Linux中,硬件上没有L_PTE_YOUNG比特位,那么ARM32 linux如何模拟这个linux版本的L_PTE_YOUNG比特位?ARM32 Linux内核实现了两套页表,一套为了迎合linux内核,一套为了ARM硬件。L_PTE_YOUNG是linux版本页面表项的比特位,当内存映射建立时,会设置该比特位;当解除映射时,要清理掉该比特位。下面查看匿名页面映射时,观察L_PTE_YOUNG比特位*/if (ptep_clear_flush_young_notify(vma, address, pte)) {/** Don't treat a reference through a sequentially read* mapping as such. If the page has been used in* another mapping, we will catch it; if this other* mapping is already gone, the unmap path will have* set PG_referenced or activated the page.*//*这里会排除顺序读的情况,因为顺序读的page cache是需要被回收的最佳候选者,因此对这些page cache做了弱访问引用处理(weak references),而其余的情况会当作pte被引用,最后增加pra->referenced计数和减少pra->mapcount的计数*/if (likely(!(vma->vm_flags & VM_SEQ_READ)))referenced++;}pte_unmap_unlock(pte, ptl);}if (referenced) {pra->referenced++;pra->vm_flags |= vma->vm_flags;}pra->mapcount--;if (!pra->mapcount)return SWAP_SUCCESS; /* To break the loop */return SWAP_AGAIN;
}
匿名页面初次映射时,观察L_PTE_YOUNG比特位在何时第一次置位的?
在do_brk()函数中,在新建一个VMA时会通过vm_get_page_prot()建立VMA属性
static unsigned long do_brk(unsigned long addr, unsigned long len)
{......vma->vm_mm = mm;vma->vm_start = addr;vma->vm_end = addr + len;vma->vm_pgoff = pgoff;vma->vm_flags = flags;vma->vm_page_prot = vm_get_page_prot(flags);vma_link(mm, vma, prev, rb_link, rb_parent);......
}pgprot_t vm_get_page_prot(unsigned long vm_flags)
{return __pgprot(pgprot_val(protection_map[vm_flags &(VM_READ|VM_WRITE|VM_EXEC|VM_SHARED)]) |pgprot_val(arch_vm_get_page_prot(vm_flags)));
}在vm_get_page_prot()函数中,重要的是通过VMA属性来转换成PTE页表项的属性,可以通过查表的方式来获取,protection_map[]定义了很多种属性组合,这些属性组合最终转换为PTE页表的相关比特位。
[arch/arm/include/asm/pgtable.h]
#define _L_PTE_DEFAULT L_PTE_PRESENT | L_PTE_YOUNG#define __PAGE_NONE __pgprot(_L_PTE_DEFAULT | L_PTE_RDONLY | L_PTE_XN | L_PTE_NONE)
#define __PAGE_SHARED __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_XN)
#define __PAGE_SHARED_EXEC __pgprot(_L_PTE_DEFAULT | L_PTE_USER)
#define __PAGE_COPY __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY | L_PTE_XN)
#define __PAGE_COPY_EXEC __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY)
#define __PAGE_READONLY __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY | L_PTE_XN)
#define __PAGE_READONLY_EXEC __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY)上述属性组合都是会设置L_PTE_PRESENT | L_PTE_YOUNG这两个比特位vma->vm_page_prot中。
在匿名页面缺页中断处理中,会根据vma->vm_page_prot来生成一个新的PTE页面表项。
static int do_anonymous_page(struct mm_struct *mm, struct vm_area_struct *vma,unsigned long address, pte_t *page_table, pmd_t *pmd,unsigned int flags)
{.....entry = mk_pte(page, vma->vm_page_prot);......set_pte_at(mm, address, page_table, entry);......
}因此,当匿名页面第一次建立映射时,会设置L_PTE_PRESENT|L_PTE_YOUNG这两个比特位到Linux版本的页面表项中。
当page_referenced()函数计算访问引用PTE的页面个数时,通过RMAP反向映射遍历每个PTE,然后调用ptep_clear_flush_young_notify()函数来检查每个PTE最近是否被访问过。
[page_referenced()->rmap_one()->page_referenced_one()->pmdp_clear_flush_young_notify()]
include/linux/mmu_notifier.h
#define ptep_clear_flush_young_notify(__vma, __address, __ptep) \
({ \int __young; \struct vm_area_struct *___vma = __vma; \unsigned long ___address = __address; \__young = ptep_clear_flush_young(___vma, ___address, __ptep); \__young |= mmu_notifier_clear_flush_young(___vma->vm_mm, \___address, \___address + \PAGE_SIZE); \__young; \
})ptep_clear_flush_young_notify()函数的核心是调用ptep_test_and_clear_young()函数
ptep_clear_flush_young_notify()->ptep_clear_flush_young()->ptep_test_and_clear_young()
mm/pgtable-generic.c
include/asm-generic/pgtable.h
static inline int ptep_test_and_clear_young(struct vm_area_struct *vma,unsigned long address,pte_t *ptep)
{pte_t pte = *ptep;int r = 1;/*利用pte_young宏判断linux版本的页表项中是否包含L_PTE_YOUNG比特位,如果没有设置该比特位,则返回0,表示映射PTE最近没有被访问引用过。如果L_PTE_YOUNG比特位置位,那么需要调用pte_mkold()宏来清这个比特位,然后调用set_pte_at()函数来写入ARM硬件页表*/if (!pte_young(pte))r = 0;elseset_pte_at(vma->vm_mm, address, ptep, pte_mkold(pte));return r;
}static inline pte_t pte_mkold(pte_t pte)
{return clear_pte_bit(pte, __pgprot(L_PTE_YOUNG));
}ptep_test_and_clear_young()->set_pte_at()->cpu_v7_set_pte_ext()
ENTRY(cpu_v7_set_pte_ext)
#ifdef CONFIG_MMUstr r1, [r0] @ linux versionbic r3, r1, #0x000003f0bic r3, r3, #PTE_TYPE_MASKorr r3, r3, r2orr r3, r3, #PTE_EXT_AP0 | 2tst r1, #1 << 4orrne r3, r3, #PTE_EXT_TEX(1)eor r1, r1, #L_PTE_DIRTYtst r1, #L_PTE_RDONLY | L_PTE_DIRTYorrne r3, r3, #PTE_EXT_APXtst r1, #L_PTE_USERorrne r3, r3, #PTE_EXT_AP1tst r1, #L_PTE_XNorrne r3, r3, #PTE_EXT_XN/*当L_PTE_YOUNG被清掉并且L_PTE_PRESENT还在时,这时候保存Linux版本页表不变,把ARM硬件版本的页表清0*/tst r1, #L_PTE_YOUNGtstne r1, #L_PTE_VALIDeorne r1, r1, #L_PTE_NONEtstne r1, #L_PTE_NONEmoveq r3, #0ARM( str r3, [r0, #2048]! ) //写入硬件页表,硬件页表在软件页表+2048ByteTHUMB( add r0, r0, #2048 )THUMB( str r3, [r0] )ALT_SMP(W(nop))ALT_UP (mcr p15, 0, r0, c7, c10, 1) @ flush_pte
#endifbx lr
ENDPROC(cpu_v7_set_pte_ext)当L_PTE_YOUNG被清掉且L_PTE_PRESENT还在时,保存Linux版本页表不变,把ARM硬件版本的页表清0.
因为ARM硬件版本的页表被清0之后,当应用程序再次访问这个页面时会触发缺页中断。注意,此时ARM硬件版本的页表项内容为0,linux版本的页表项内容还在。
[page_referenced()清了L_PTE_YOUNG和ARM硬件页表->应用程序再次访问该页->触发缺页中断]
为什么要清理ARM硬件页表?
在缺页中断中会重新设置Linux版本页表的L_PTE_YOUNG比特位,见下面的handle_pte_fault函数
static int handle_pte_fault(struct mm_struct *mm,struct vm_area_struct *vma, unsigned long address,pte_t *pte, pmd_t *pmd, unsigned int flags)
{pte_t entry;spinlock_t *ptl;/** some architectures can have larger ptes than wordsize,* e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and CONFIG_32BIT=y,* so READ_ONCE or ACCESS_ONCE cannot guarantee atomic accesses.* The code below just needs a consistent view for the ifs and* we later double check anyway with the ptl lock held. So here* a barrier will do.*/entry = *pte;barrier();if (!pte_present(entry)) {if (pte_none(entry)) {if (vma->vm_ops) {if (likely(vma->vm_ops->fault))return do_fault(mm, vma, address, pte,pmd, flags, entry);}return do_anonymous_page(mm, vma, address,pte, pmd, flags);}return do_swap_page(mm, vma, address,pte, pmd, flags, entry);}if (pte_protnone(entry))return do_numa_page(mm, vma, address, entry, pte, pmd);ptl = pte_lockptr(mm, pmd);spin_lock(ptl);if (unlikely(!pte_same(*pte, entry)))goto unlock;if (flags & FAULT_FLAG_WRITE) {if (!pte_write(entry))return do_wp_page(mm, vma, address,pte, pmd, ptl, entry);entry = pte_mkdirty(entry);}/*对于ARM平台,这里重新设置L_PTE_YOUNG比特位*/entry = pte_mkyoung(entry);if (ptep_set_access_flags(vma, address, pte, entry, flags & FAULT_FLAG_WRITE)) {update_mmu_cache(vma, address, pte);} else {/** This is needed only for protection faults but the arch code* is not yet telling us if this is a protection fault or not.* This still avoids useless tlb flushes for .text page faults* with threads.*/if (flags & FAULT_FLAG_WRITE)flush_tlb_fix_spurious_fault(vma, address);}
unlock:pte_unmap_unlock(pte, ptl);return 0;
}总结page_referenced()函数所做的主要工作如下:
-
利用RMAP系统遍历所有该页面的pte。
-
对于每个pte,如果L_PTE_YOUNG比特位置位,说明之前被访问过,referenced计数加1。然后清空L_PTE_YOUNG比特位,对于ARM32处理器来说,会清空硬件页表项内容,人为制造一个缺页中断,当再次访问该pte时,缺页中断中设置L_PTE_YOUNG比特位。这样就可以很好的监听这个页面是否最近被访问过
-
返回referenced计数,表示该页有多少个访问引用pte
小结:
为了评估页的活动程序,kernel引入了PG_referenced和PG_active两个标志位。为什么需要两个标志位呢?假定只使用一个PG_active来标识页是活动,在页被访问时,设置该位,但是何时清除呢?为此需要维护大量的内核定时器,这种方法注定是要失败的。
使用两个标志,可以实现一种更精巧的方法,其核心思想是:一个标识当前活跃程度,一个表示最近是否被引用过,下图说明了基本算法:

基本上有以下步骤:
(1) 如果页是活动的,设置PG_active,并保存在ACTIVE_LRU链表;反之在INACTIVE;
(2) 每次访问时,设置PG_referenced位,复制该工作的是mark_page_accessed()函数;
(3) PG_referenced以及由反向映射提供的信息用来确定页面活跃程度,每次清除该位时,都会检测页面活跃程序,page_referenced函数实现了该行为;
(4) 再次进入mark_page_accessed()。如果发现PG_refenced已被置位,意味着page_referenced没有执行检查,因而对于mark_page_accessed()的调用比page_referenced()更频繁,这意味着页面经常被访问。如果该页位于INACTIVE链表,将其移动到ACTIVE,此外还会设置PG_active标志位,清除PG_referenced;
(5) 反向的转移也可能的,在页面活动程度减少时,可能连续调用两次page_referenced而中间没有mark_page_accessed()。
如果对于内存页的访问是稳定的,那么对page_referenced和mark_page_accessed()的调用在本质上是均衡的,因而页面保持在当前LRU链表,这种方案同时确保了内存页不会再ACTIVE与INACTIVE链表间快速跳跃。