1.什么是LRU算法
LRU算法又称最近最少使用算法,它的基本思想是长期不被使用的数据,在未来被用到的几率也不大,所以当新的数据进来时我们可以优先把这些数据替换掉。
在LRU算法中,使用了一种有趣的数据结构,称为哈希链表。我们知道哈希表是由多个<Key,Value>对组成的,哈希链表是将这写节点链接起来,每一个节点都有一个前驱结点和后驱节点,就像双向链表中的节点一样。哈希表拥有了固定的排列顺序。

基于哈希链表的有序性,我们就可以把<Key,Value>按照最后的使用时间来排列。
2.LRU算法的基本思路
假设我们使用哈希链表来缓存用户信息,目前缓存了4个用户,用户按照时间顺序从链表右端插入:
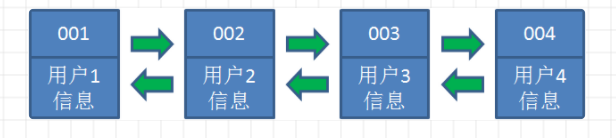
情景一:当访问用户5时,由于哈希链表中没有用户5的数据,从数据库中读取出来插入到缓存中
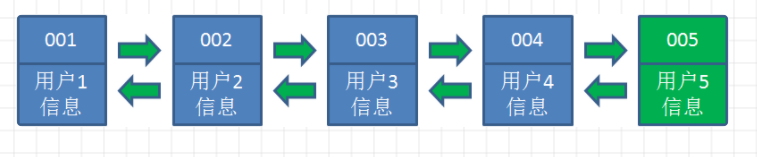
情景二:挡访问用户2时,由于哈希链表中有用户2的数据,我们把它掐断,放到链表最右段

情景三:同情景二,这次访问用户4的数据
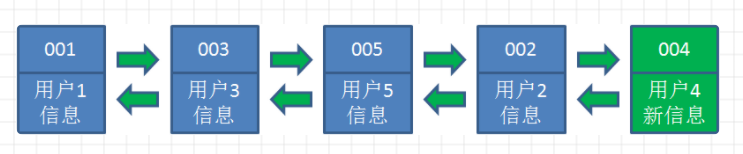
情景四:当用户访问用户6,用户6在缓存中没有,需要插入到链表中,但此时链表长度已满,我们把最左端的用户删掉,然后插入用户6
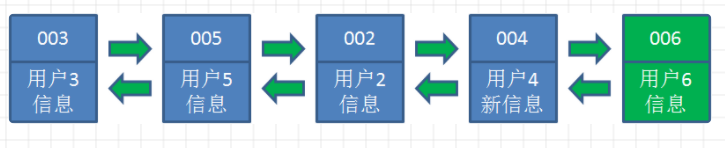
说明:我们仔细回顾一下,当缓存命中时,我们就把它放到最右端,也就是说排在右边的是最近被使用过的,那左边的当然是相对较少被访问过的,所以当缓存不命中的时候,我们就把最左边的剔除掉,所以这里就体现了最近最少使用的原则。
3.LRU算法的基本实现
// 此方法 是将最近使用最多的放在最左端,较少的放在最右端
class LRUCache {class Node {// 键和值int k, v;// 左右结点Node l, r;Node(int _k, int _v) {k = _k;v = _v;}}int n;Node head, tail;// 头结点和尾结点Map<Integer, Node> map;public LRUCache(int capacity) {n = capacity;map = new HashMap<>();head = new Node(-1, -1);tail = new Node(-1, -1);head.r = tail;tail.l = head;}public int get(int key) {if (map.containsKey(key)) {Node node = map.get(key);refresh(node);return node.v;}return -1;}public void put(int key, int value) {Node node = null;if (map.containsKey(key)) {node = map.get(key);node.v = value;} else {if (map.size() == n) {Node del = tail.l;map.remove(del.k);delete(del);}node = new Node(key, value);map.put(key, node);}refresh(node);}// refresh 操作分两步:// 1. 先将当前节点从双向链表中删除(如果该节点本身存在于双向链表中的话)// 2. 将当前节点添加到双向链表头部void refresh(Node node) {delete(node);node.r = head.r;node.l = head;head.r.l = node;head.r = node;}// delete 操作:将当前节点从双向链表中移除// 由于我们预先建立 head 和 tail 两位哨兵,因此如果 node.l 不为空,则代表了 node 本身存在于双向链表(不是新节点)void delete(Node node) {if (node.l != null) {Node left = node.l;left.r = node.r;node.r.l = left;}}
}