注:本文分析基于linux-4.18.0-193.14.2.el8_2内核版本,即CentOS 8.2
1、 关于LRU
LRU即Least recently used,也就是最近最少使用,一般用作缓存淘汰上,它的核心思想是——如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。
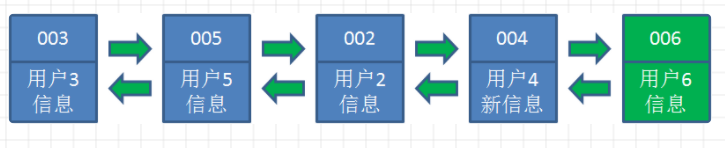
LRU在Linux上用作内存页面回收的策略,通过active链表和inactive链表,将经常被访问的处于活跃状态的页面放在active链表上,而不经常使用的页面则会被放到inactive链表上。同时页面会在这两个链表中移动,也会在同个链表中移动。通过不断把活跃的页面移动到active链表,以及把不活跃的页面移动到inactive链表,那些最近最少使用的页面会被移到inactive链表尾部。在系统内存不足,回收页面时,操作系统就从inactive链表的尾部开始进行回收。
2、LRU链表类型
目前4.8内核版本中,系统上LRU链表以节点为粒度,即每个节点上有一个LRU管理结构,在之前的内核中,这个结构存在于zone结构体中,即每个zone有一个LRU管理结构。
typedef struct pglist_data {...//LRU链表管理结构struct lruvec lruvec;...
} pg_data_t;
除了根据页面的活跃和非活跃性,还进一步把该内存页是否是文件页作为区分,以及是否可以回收,将页面分为5种类型,并为每种页面创建了一个LRU链表。关于内存页类型,可以参考之前的文章——内存页类型。
#define LRU_BASE 0
#define LRU_ACTIVE 1
#define LRU_FILE 2enum lru_list {LRU_INACTIVE_ANON = LRU_BASE, //非活动匿名页LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE, //活动匿名页 LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE, //非活动文件页LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE, //活动文件页LRU_UNEVICTABLE, //不可回收页,被mlock锁住的页面NR_LRU_LISTS
};struct lruvec {struct list_head lists[NR_LRU_LISTS]; //五个LRU链表struct zone_reclaim_stat reclaim_stat;/* Evictions & activations on the inactive file list */atomic_long_t inactive_age;/* Refaults at the time of last reclaim cycle */unsigned long refaults;struct pglist_data *pgdat; //指向所属node节点
};
3、LRU链表工作原理
Linux引入了PG_active和PG_referenced两个页面标志符,用于标识页面的活跃程度。
- PG_active 用于表示页面当前是否是活跃的,如果该位被置位,则表示该页面是活跃的
- PG_referenced 用于表示页面最近是否被访问过,每次页面被访问,该位都会被置位
对于active链表,当页面被访问时,如果PG_referenced未被设置,则设置;如果已设置,则不操作。如果PG_referenced标志未被设置,一段时间之后,如果该页面还是没有被访问,那么PG_active标志也会被清除,并挪到inactive链表上,这操作在shrink_active_list执行。
对于inactive链表,当页面被访问时,如果PG_referenced未被设置,则设置;如果已设置,则意味着该页面经常被访问,设置PG_active标志,并移动到active链表,并清除PG_referenced标志。如果PG_referenced标志未被设置,一段时间之后,如果该页面还是没有被访问,那么PG_active标志也会被清除,该操作在shrink_inactive_list上执行。
/** inactive,unreferenced -> inactive,referenced* inactive,referenced -> active,unreferenced* active,unreferenced -> active,referenced*/
void mark_page_accessed(struct page *page)
{page = compound_head(page);//如果页面是inactive且不是不可回收且页面有被进程引用if (!PageActive(page) && !PageUnevictable(page) && PageReferenced(page)) {//如果页面在LRU链表中,设置PG_active标志,并移动到active LRU链表if (PageLRU(page))activate_page(page);else//不在LRU中,那就是在LRU缓存pagevec中,标识为active//之后会被移动到active链表__lru_cache_activate_page(page);//清除PG_referenced标志位ClearPageReferenced(page);if (page_is_file_cache(page))workingset_activation(page);} else if (!PageReferenced(page)) {//如果该页面没有被引用,设置PG_referenced标志位SetPageReferenced(page);}//清除空闲页面的pg_idle标志if (page_is_idle(page))clear_page_idle(page);
}
active和inactive之间的转换可以通过下面这张图呈现,

4、LRU缓存
4.1 LRU缓存结构
由上面可知,页面会在active和inactice链表中来回移动,如果每次移动都进行操作,那就意味着要获取node节点的自旋锁,竞争非常大,因此引入一层缓存——LRU缓存。这个缓存的思想很简单,就是积累一定数量的页面后再操作。这个缓存使用pagevec结构来描述,
/* 15 pointers + header align the pagevec structure to a power of two */
#define PAGEVEC_SIZE 15struct pagevec {unsigned char nr; //页面数量bool percpu_pvec_drained;struct page *pages[PAGEVEC_SIZE]; //页面指针
};
可见,LRU缓存默认批处理页面数为15。
4.2 LRU缓存类型
我们先梳理下共有几种页面移动的情况,
- 新页面加入LRU链表
- inactive LRU链表 -> inactive LRU链表末尾
- active LRU链表 -> inactive LRU链表
- inactive LRU链表 -> active LRU链表
因此,内核中为这几种情况分别定义了对应的缓存对象,
static DEFINE_PER_CPU(struct pagevec, lru_add_pvec);
static DEFINE_PER_CPU(struct pagevec, lru_rotate_pvecs);
static DEFINE_PER_CPU(struct pagevec, lru_deactivate_file_pvecs);
static DEFINE_PER_CPU(struct pagevec, lru_lazyfree_pvecs);
static DEFINE_PER_CPU(struct pagevec, activate_page_pvecs);
有一点要注意的是,这里定义的是每CPU变量,因此每个CPU上都有这对应的5个LRU缓存实例。而且,对于active -> inactive的情况,又分为文件页和匿名页,对应的缓存是lru_deactivate_file_pvecs和lru_lazyfree_pvecs。
4.3 代码实现
4.3.1 新页面加入LRU链表
新页面加入LRU链表主要通过lru_cache_add函数,
void lru_cache_add(struct page *page)
{VM_BUG_ON_PAGE(PageActive(page) && PageUnevictable(page), page);VM_BUG_ON_PAGE(PageLRU(page), page);__lru_cache_add(page);
}static void __lru_cache_add(struct page *page)
{// 获取此CPU的lru缓存struct pagevec *pvec = &get_cpu_var(lru_add_pvec);get_page(page);// 添加页面到lru缓存中,并判断添加后时候还有空闲空间if (!pagevec_add(pvec, page) || PageCompound(page))// lru缓存空间满了,需要将该缓存的页面move到对应的lru链表__pagevec_lru_add(pvec);put_cpu_var(lru_add_pvec);
}// Add a page to a pagevec. Returns the number of slots still available.
static inline unsigned pagevec_add(struct pagevec *pvec, struct page *page)
{// 添加页面到lru缓存pvec->pages[pvec->nr++] = page;return pagevec_space(pvec);
}static inline unsigned pagevec_space(struct pagevec *pvec)
{ return PAGEVEC_SIZE - pvec->nr; //判断缓存是否还有空间
}
所以,当lru缓存满了之后,就通过__pagevec_lru_add去实际将页面放入对应lru链表,
void __pagevec_lru_add(struct pagevec *pvec)
{pagevec_lru_move_fn(pvec, __pagevec_lru_add_fn, NULL);
}static void pagevec_lru_move_fn(struct pagevec *pvec,void (*move_fn)(struct page *page, struct lruvec *lruvec, void *arg),void *arg)
{int i;struct pglist_data *pgdat = NULL;struct lruvec *lruvec;unsigned long flags = 0;//遍历该lru缓存数组for (i = 0; i < pagevec_count(pvec); i++) {struct page *page = pvec->pages[i]; //获取页面struct pglist_data *pagepgdat = page_pgdat(page); //获取结点结构//判断和上个页面是否属于同个node,看是否需要获取node的锁if (pagepgdat != pgdat) {if (pgdat)spin_unlock_irqrestore(&pgdat->lru_lock, flags);pgdat = pagepgdat;spin_lock_irqsave(&pgdat->lru_lock, flags);}//获取lru链表lruvec = mem_cgroup_page_lruvec(page, pgdat);//调用对应函数,移动页面到对应的LRU链表(*move_fn)(page, lruvec, arg);}if (pgdat)spin_unlock_irqrestore(&pgdat->lru_lock, flags);//减少lru缓存上页面的引用计数,如果计数为0,释放该页面release_pages(pvec->pages, pvec->nr);pagevec_reinit(pvec);
}
这里最重要的就是move_fn函数指针,不同情况的页面转移主要就是这个函数的不同,对于新页面加入LRU链表,这个指针就指向__pagevec_lru_add_fn,其他情况我们后面会分析。
static void __pagevec_lru_add_fn(struct page *page, struct lruvec *lruvec,void *arg)
{enum lru_list lru;int was_unevictable = TestClearPageUnevictable(page); //判断页面是否可回收VM_BUG_ON_PAGE(PageLRU(page), page);SetPageLRU(page); //设置页面flags标志,表示页面已在LRU链表中smp_mb();//页面可回收if (page_evictable(page)) {//根据页面标志判断该页面应该加入哪个LRU链表//PG_active判断是否是active链表//PG_swapbacked判断是否是匿名页//PG_unevictable判断是否可回收lru = page_lru(page); update_page_reclaim_stat(lruvec, page_is_file_cache(page),PageActive(page));if (was_unevictable)count_vm_event(UNEVICTABLE_PGRESCUED);} else {//页面不可回收lru = LRU_UNEVICTABLE;ClearPageActive(page);SetPageUnevictable(page);if (!was_unevictable)count_vm_event(UNEVICTABLE_PGCULLED);}//加入LRU链表add_page_to_lru_list(page, lruvec, lru);trace_mm_lru_insertion(page, lru);
}
4.3.2 inactive LRU链表 -> inactive LRU链表末尾
这种情况主要发生在当脏页进行回收时,系统将页面异步回写到磁盘,然后将页面移动到非活动lru链表尾部,以便下次优先回收。该操作主要通过rotate_reclaimable_page函数,
void rotate_reclaimable_page(struct page *page)
{//页面未被锁定且非脏页且非不可回收同时页面已经在LRU链表里if (!PageLocked(page) && !PageDirty(page) &&!PageUnevictable(page) && PageLRU(page)) {struct pagevec *pvec;unsigned long flags;get_page(page);local_irq_save(flags);//获取当前CPU的lru缓存pvec = this_cpu_ptr(&lru_rotate_pvecs);//加入lru缓存if (!pagevec_add(pvec, page) || PageCompound(page))//满了则移动到链表里pagevec_move_tail(pvec);local_irq_restore(flags);}
}static void pagevec_move_tail(struct pagevec *pvec)
{int pgmoved = 0;//又是这个函数,此时回调函数指向的是pagevec_move_tail_fnpagevec_lru_move_fn(pvec, pagevec_move_tail_fn, &pgmoved);__count_vm_events(PGROTATED, pgmoved);
}
和上种情况类似,都是调用pagevec_lru_move_fn,只是此时move_fn函数指针指向的是pagevec_move_tail_fn
static void pagevec_move_tail_fn(struct page *page, struct lruvec *lruvec,void *arg)
{int *pgmoved = arg;if (PageLRU(page) && !PageUnevictable(page)) {//先将页面从lru链表中摘除del_page_from_lru_list(page, lruvec, page_lru(page));ClearPageActive(page); //清除active标志//再放入inactive lru链表末尾add_page_to_lru_list_tail(page, lruvec, page_lru(page));(*pgmoved)++;}
}
4.3.3 active LRU链表 -> inactive LRU链表(文件页)
这种情况主要发生在通过drop_caches接口手动释放缓存以及文件系统释放缓存,主要通过deactivate_file_page函数将文件页面deactive。
void deactivate_file_page(struct page *page)
{//不可回收的页面移动没有意义if (PageUnevictable(page))return;//并且只针对引用计数不为0的页面处理,为0就要被回收了,没必要处理if (likely(get_page_unless_zero(page))) {//获取当前CPU的lru缓存struct pagevec *pvec = &get_cpu_var(lru_deactivate_file_pvecs);//添加到LRU缓存,如果满了就移动到对应LRU链表if (!pagevec_add(pvec, page) || PageCompound(page))pagevec_lru_move_fn(pvec, lru_deactivate_file_fn, NULL);put_cpu_var(lru_deactivate_file_pvecs);}
}
主要还是这个回调函数lru_deactivate_file_fn,
static void lru_deactivate_file_fn(struct page *page, struct lruvec *lruvec,void *arg)
{int lru, file;bool active;//不处理非LRU页面if (!PageLRU(page))return;//不可回收页面也不处理if (PageUnevictable(page))return;//被进程映射了说明有在使用,也不处理if (page_mapped(page))return;//获取页面活动标志,PG_activeactive = PageActive(page);file = page_is_file_cache(page); //判断是否是文件页lru = page_lru_base_type(page); //获取该加入的LRU链表索引//先将该页面从active LRU链表摘除del_page_from_lru_list(page, lruvec, lru + active);ClearPageActive(page); //清除PG_active标志ClearPageReferenced(page); //清除PG_referenced标志add_page_to_lru_list(page, lruvec, lru); //加入inactive链表头//如果页面正在回写或者是脏页if (PageWriteback(page) || PageDirty(page)) {//设置PG_Reclaim标志,表示需要回写SetPageReclaim(page);} else {//如果是干净页面,直接把页面移动到inactive链表末尾,便于尽早回收list_move_tail(&page->lru, &lruvec->lists[lru]);__count_vm_event(PGROTATED);}if (active)__count_vm_event(PGDEACTIVATE);update_page_reclaim_stat(lruvec, file, 0);
}
4.3.4 active LRU链表 -> inactive LRU链表(匿名页)
针对匿名页的deactive操作,由mark_page_lazyfree处理,
void mark_page_lazyfree(struct page *page)
{ //只处理LRU页面且为匿名页且能交换到swap分区且非swap缓存且非不可回收if (PageLRU(page) && PageAnon(page) && PageSwapBacked(page) &&!PageSwapCache(page) && !PageUnevictable(page)) {//获取当前CPU的lru缓存struct pagevec *pvec = &get_cpu_var(lru_lazyfree_pvecs);get_page(page);//添加到LRU缓存,如果满了就移动到对应LRU链表if (!pagevec_add(pvec, page) || PageCompound(page))pagevec_lru_move_fn(pvec, lru_lazyfree_fn, NULL);put_cpu_var(lru_lazyfree_pvecs);}
}
static void lru_lazyfree_fn(struct page *page, struct lruvec *lruvec,void *arg)
{//只处理LRU页面且为匿名页且能交换到swap分区且非swap缓存且非不可回收if (PageLRU(page) && PageAnon(page) && PageSwapBacked(page) &&!PageSwapCache(page) && !PageUnevictable(page)) {bool active = PageActive(page); //判断页面是否active//从匿名active LRU链表中摘除页面del_page_from_lru_list(page, lruvec,LRU_INACTIVE_ANON + active);ClearPageActive(page); //清除PG_Active标志ClearPageReferenced(page); //清除PG_referenced标志/** lazyfree pages are clean anonymous pages. They have* SwapBacked flag cleared to distinguish normal anonymous* pages*/ClearPageSwapBacked(page); //清除PG_SwapBacked标志//添加到匿名inactive LRU链表add_page_to_lru_list(page, lruvec, LRU_INACTIVE_FILE); __count_vm_events(PGLAZYFREE, hpage_nr_pages(page));count_memcg_page_event(page, PGLAZYFREE);update_page_reclaim_stat(lruvec, 1, 0);}
}
4.3.5 inactive LRU链表 -> active LRU链表
这种情况主要发生在有被引用的inactive页面被访问时,需要将该页面移动到active链表,通过activate_page操作,
void activate_page(struct page *page)
{page = compound_head(page);//LRU页面且非active且非不可回收if (PageLRU(page) && !PageActive(page) && !PageUnevictable(page)) {//获取当前CPU上的目标LRU缓存struct pagevec *pvec = &get_cpu_var(activate_page_pvecs);get_page(page);//添加到LRU缓存中,如果满了就移动到对应LRU链表if (!pagevec_add(pvec, page) || PageCompound(page))pagevec_lru_move_fn(pvec, __activate_page, NULL);put_cpu_var(activate_page_pvecs);}
}
同样,重点依旧是回调函数__activate_page,
static void __activate_page(struct page *page, struct lruvec *lruvec,void *arg)
{ //只处理LRU页面且非active且非不可回收if (PageLRU(page) && !PageActive(page) && !PageUnevictable(page)) {int file = page_is_file_cache(page); //判断是否是文件页int lru = page_lru_base_type(page); //获取当前页面LRU链表索引//从inactive LRU链表中摘除del_page_from_lru_list(page, lruvec, lru);SetPageActive(page); //设置PG_Active标志lru += LRU_ACTIVE; //设置目标LRU链表索引add_page_to_lru_list(page, lruvec, lru); //添加到active LRU链表trace_mm_lru_activate(page);__count_vm_event(PGACTIVATE);update_page_reclaim_stat(lruvec, file, 1);}
}