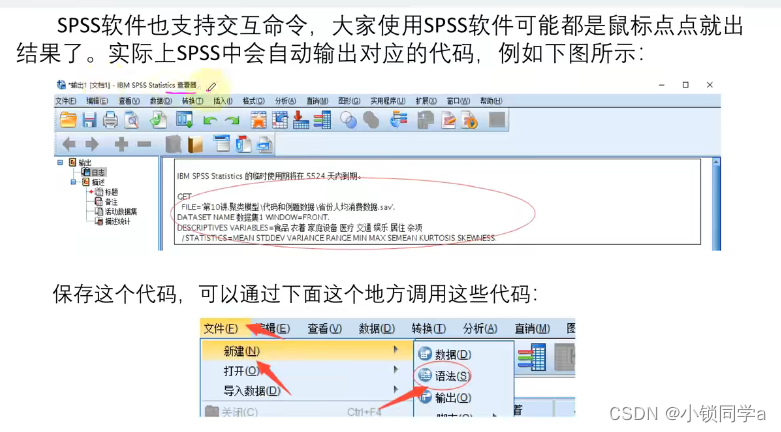
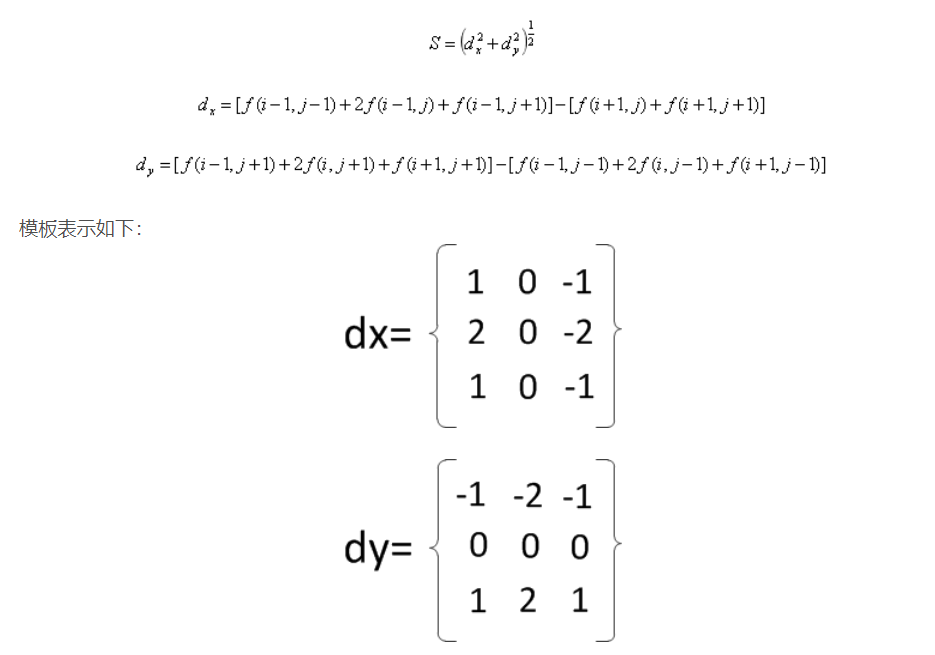
马尔可夫决策过程 (Markov Decision Process,MDP)是序贯决策(sequential decision)的数学模型,一般用于具备马尔可夫性的环境中。最早的研究可以追溯到最优控制 (optimal control)问题上,1957年,美国学者Richard Bellman通过离散随机最优控制模型首次提出了离散时间马尔可夫决策过程。最优化控制的离散随机版本:马尔可夫决策过程。1960年和1962年,美国学者Ronald A. Howard和David Blackwell提出并完善了求解MDP模型的动态规划方法。之后被广泛用于自动控制、推荐系统、强化学习等领域。
- 参考文献1:Howard, R.A..Dynamic Programming and Markov Processes.Cambridge, Massachusetts:Technology Press-Wiley,1960
- 参考文献2:Bellman, R.E., 1957. A Markov decision process. Journal of Mathematical Mechanics, 6, pp.679-684.
- 参考文献3:Blackwell D., 1962. Discrete dynamic programming. Ann Math Stat 33: 719-726.
在机器学习中是一种用于解决强化学习问题的数学框架。在强化学习中,马尔可夫决策过程是对完全可观测的环境所描述的,即智能体的观测内容完整地包含了决策所需要的所有特征。几乎所有的强化学习控制对象都是需要先建模成马尔可夫决策过程,之后套优化算法做优化。最常见的优化算法就是动态规划 (Dynamic programming) 算法,是一种解决复杂问题非常行之有效的方法。近些年结合深度学习求解的方法大红大紫。
马尔可夫性
在说马尔可夫决策过程之前,我们需要先了解一下马尔可夫性。那什么样的状态具备马尔可夫性(Markov Property)呢?
当某一当前状态可知,所有的历史信息都不再需要,即当前时刻的状态仅与前一时刻的状态和动作有关,与其他时刻的状态和动作条件独立,则认为该状态具有马尔可夫性。用状态转移的概率公式描述马尔可夫性表示如下:
P [ S t + 1 ∣ S t ] = P [ S t + 1 ∣ S 1 , … , S t ] \mathbb{P}\left[S_{t+1} | S_{t}\right]=\mathbb{P}\left[S_{t+1} | S_{1}, \ldots, S_{t}\right] P[St+1∣St]=P[St+1∣S1,…,St]
马尔可夫过程
马尔可夫过程(Markov Process)又叫马尔可夫链,是一个无记忆的随机过程,可以用一个二元组来表示 ⟨ S , P ⟩ \langle\mathcal{S}, \mathcal{P}\rangle ⟨S,P⟩,其中:
- S \mathcal{S} S表示一个有限状态集合;
- P \mathcal{P} P表示状态转移概率矩阵,有: P s s ′ = P [ S t + 1 = s ′ ∣ S t = s ] \mathcal{P}_{\mathcal{s}\mathcal{s}^{\prime}}=\mathbb{P}[\mathcal{S}_{t+1}=\mathcal{s}^{\prime}|\mathcal{S}_{t}=\mathcal{s}] Pss′=P[St+1=s′∣St=s]。
我们举个例子来说明理解一下:
下图中是一个学生学习的示例,圆圈是学生所在的状态,方格表示终止状态,或者描述成自循环的状态。箭头表示状态之间的转移,箭头上的概率表示状态转移的概率。

如学生在第一节课的时候,他有 50 % 50\% 50%的概率参加第二节课,同时也有 50 % 50\% 50%的概率去刷Facebook,在刷Facebook的时候有 90 % 90\% 90%的概率继续浏览,有 10 % 10\% 10%的概率回到第一节课上来。依此类推可以知道整个的状态转移情况。其状态转移矩阵 P \mathcal{P} P如下所示:

马尔可夫奖励过程
马尔可夫奖励过程(Markov Reward Process),它在马尔可夫过程的基础之上增加了奖励 R \mathcal{R} R和衰减系数 γ \mathcal{\gamma} γ,可以用一个四元组来表示 ⟨ S , P , R , γ ⟩ \langle\mathcal{S}, \mathcal{P}, \mathcal{R}, \mathcal{\gamma}\rangle ⟨S,P,R,γ⟩,其中:
- S \mathcal{S} S表示一个有限状态集合;
- P \mathcal{P} P表示状态转移概率矩阵;
- R \mathcal{R} R是奖励函数,定义为: R s = E [ R t + 1 ∣ S t = s ] \mathcal{R}_{s}=\mathbb{E}[R_{t+1}|\mathcal{S}_{t}=\mathcal{s}] Rs=E[Rt+1∣St=s],表示在当前时刻 t t t的状态 S t \mathcal{S}_{t} St下,下一个时刻 t + 1 t+1 t+1所能获得的期望奖励;
- γ \mathcal{\gamma} γ是折扣因子(discount factor), γ ∈ [ 0 , 1 ] \mathcal{\gamma} \in [0,1] γ∈[0,1]。
马尔可夫决策过程
马尔可夫决策过程也被称为受控马尔可夫链(controlled Markov chain)、随机控制问题 (stochastic controlled problem) 、马尔可夫决策规划(Markov decision programming)等。在一个state选择一个action会产生一个reward,并且通过状态转移概率函数决定下一个时刻的state。
environment对于agent的意义在于提供状态转移函数和奖励函数。当状态转移函数和奖励函数给定时,环境可以建模成Markov Decision Process。在Markov Decision Process中state会随着time-step发生转移,意思是说状态之间可以相互迁移,迁移的概率由状态转移函数而定。
如果我们知道的环境的model,或者说这个model是一个白盒model,即各个状态之间的转移概率都已知 (在Markov Decision Process中状态之间的转移有一个动作action ),在强化学习中称已知model的情形叫做model-based的强化学习,反之model未知,叫做model-free的强化学习。
从马尔可夫奖励过程过渡过来,马尔可夫决策过程(Markov Decision Process),是带有决策的马尔可夫奖励过程,环境所提供的所有状态都具备马尔可夫性。它在马尔可夫奖励过程中添加了决策集合 A \mathcal{A} A,因此MDP可以用一个五元组来表示 ⟨ S , A , P , R , γ ⟩ \langle\mathcal{S}, \mathcal{A},\mathcal{P}, \mathcal{R}, \mathcal{\gamma}\rangle ⟨S,A,P,R,γ⟩,其中
- S \mathcal{S} S表示一个有限状态集合;
- A \mathcal{A} A表示一个有限的动作集合;
- P \mathcal{P} P表示状态转移概率矩阵, P s s ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] \mathcal{P}_{\mathcal{ss^{\prime}}}^{\mathbb{a}}=\mathbb{P}[\mathcal{S_{t+1}=\mathcal{s^{\prime}}}|\mathcal{S_{t}=s},\mathcal{A}_{t}=a] Pss′a=P[St+1=s′∣St=s,At=a];
- R \mathcal{R} R是奖励函数,定义为: R s a = E [ R t + 1 ∣ S t = s , A t = a ] \mathcal{R}_{s}^{a}=\mathbb{E}[R_{t+1}|\mathcal{S}_{t}=\mathcal{s},\mathcal{A}_{t}=a] Rsa=E[Rt+1∣St=s,At=a],表示在当前时刻 t t t的状态 S t \mathcal{S}_{t} St下,采取动作 A t = a \mathcal{A}_{t}=a At=a之后,下一个时刻 t + 1 t+1 t+1所能获得的期望奖励;
- γ \mathcal{\gamma} γ是折扣因子(discount factor), γ ∈ [ 0 , 1 ] \mathcal{\gamma} \in [0,1] γ∈[0,1]。
比如在玩游戏的时候,当前所观测的图片的像素,你可以认为它是一个 S \mathcal{S} S集中的一个state(观测实际上是代表部分state);比如下围棋的时候,落子位置可以被看作action space A \mathcal{A} A中的某个action;discount factor γ \mathcal{\gamma} γ描述的是未来奖励的一种折扣关系,越远的奖励给当前的影响越小,因此需要一个折扣因子;基于当前state和action一起决定这个reward应该是多少,一般是一个标量,如果是一个向量的话就变成了一个multi-goal的强化学习。其实在很多场景下面reword只是跟state本身有关,比如围棋游戏中的state,但reward和state、action这样一个pair有关的场景也是存在的。
我们以下面的例子来再次说一下什么是马尔可夫决策过程:

上图中的红色字表示的是所采取的动作,它与及时奖励相对应。同一个状态下采取不同的action所得到的及时奖励是不一样的,这里面是没有给出状态名称的,因为怕容易混淆了,实际上你选择了Facebook这个动作之后,你的状态就进入了刷Facebook中了。注意看最下面那个小黑点,表示的是那是一个临时状态,在那个状态智能体会按照一定的概率随机转移到另外的一个状态。
MDP-策略
我们接下来看一下马尔可夫决策过程中的策略 π \mathcal{\pi} π,它是一个概率集合(离散动作空间)或者一个分布(连续动作空间),对某个状态 s \mathcal{s} s采取某个动作 a a a的概率我们可以用公式表示为如下形式:
π ( a ∣ s ) = P [ A t = a ∣ S t = s ] \mathcal{\pi}(a|s)=\mathbb{P}[\mathcal{A_{t}=a|\mathcal{S_{t}}=s}] π(a∣s)=P[At=a∣St=s]
一个策略完整定义了智能体的行为方式,也就是说定义了个体在各个状态下的各种可能的行为方式及其概率的大小。
MDP中,策略仅与当前状态有关,与历史状态无关;同时某一策略是静态的,与时间无关,但个体可以随着时间更新来更新策略。
A t ∼ π ( ⋅ ∣ S t ) , ∀ t > 0 \mathcal{A_{t}} \sim \mathcal{\pi(\cdot | \mathcal{S_{t}})},\forall_{t} >0 At∼π(⋅∣St),∀t>0
MDP-值函数
在介绍值函数之前,我们需要先了解一下回报(return)或者叫做累计奖励 (cumulative reward):在马尔可夫奖励链上,从时间步 t t t时刻开始,往后所能获得的所有折扣奖励(reward)和我们称之为回报,其中折扣因子 γ \mathcal{\gamma} γ 体现了未来的奖励在当前时刻的价值比例,其数学表达如下所示:
G t = R t + 1 + γ R t + 2 + … = ∑ k = 0 ∞ γ k R t + k + 1 G_{t}=R_{t+1}+\gamma R_{t+2}+\ldots=\sum_{k=0}^{\infty} \gamma^{k} R_{t+k+1} Gt=Rt+1+γRt+2+…=k=0∑∞γkRt+k+1
状态价值函数
状态价值函数(state-value function):表示的是在MDP中,从当前状态 s \mathcal{s} s开始,遵循策略 π \pi π所能获得的期望回报。数学表达如下所示:
v π ( s ) = E π [ G t ∣ S t = s ] \mathcal{v_{\pi}(s)}=\mathbb{E_{\pi}}[G_{t}|\mathcal{S_{t}=s}] vπ(s)=Eπ[Gt∣St=s]
这里的策略是静态的,不随状态的改变而改变,而随着智能体的更新而改变。是在某一状态,依据所采取的策略,可能产生具体的行为,而这具体的行为又具有一定概率,策略就是用来描述各个不同状态下描述采取各个不同动作的概率。
动作价值函数
动作价值函数(action-value function):表示依据策略 π \pi π时,在给定状态 s \mathcal{s} s下,采取某一具体的行为 a a a,所能获得的期望回报。
q π ( s , a ) = E π [ G t ∣ S t = s ∣ A t = a ] \mathcal{q_{\pi}(s,a)}=\mathbb{E_{\pi}}[G_{t}|\mathcal{S_{t}=s}|\mathcal{A_{t}=a}] qπ(s,a)=Eπ[Gt∣St=s∣At=a]
MDP-贝尔曼期望方程
上面只是求出了状态价值函数和动作价值函数,我们怎么来求出最优的值函数呢?
贝尔曼期望方程(Bellman Expectation Equation)是马尔可夫决策过程中一个非常重要的知识点。
我们可以用下一时刻的状态值函数和及时奖励来描述当前时刻的状态值函数,其推导过程如下所示:
v ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + … ∣ S t = s ] = E [ R t + 1 + γ ( R t + 2 + γ R t + 3 + … ) ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 + γ v ( S t + 1 ) ∣ S t = s ] \begin{aligned} v(s) &=\mathbb{E}\left[G_{t} | S_{t}=s\right] \\ &=\mathbb{E}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\ldots | S_{t}=s\right] \\ &=\mathbb{E}\left[R_{t+1}+\gamma\left(R_{t+2}+\gamma R_{t+3}+\ldots\right) | S_{t}=s\right] \\ &=\mathbb{E}\left[R_{t+1}+\gamma G_{t+1} | S_{t}=s\right] \\ &=\mathbb{E}\left[R_{t+1}+\gamma v\left(S_{t+1}\right) | S_{t}=s\right] \end{aligned} v(s)=E[Gt∣St=s]=E[Rt+1+γRt+2+γ2Rt+3+…∣St=s]=E[Rt+1+γ(Rt+2+γRt+3+…)∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1+γv(St+1)∣St=s]
可得到状态值函数的贝尔曼期望方程的最终结果:
v π ( s ) = E π [ R t + 1 + γ v π ( S t + 1 ) ∣ S t = s ] v_{\pi}(s)=\mathbb{E_{\pi}}[R_{t+1}+\gamma v_{\pi}(\mathcal{S_{t+1}})|\mathcal{S_{t}=s}] vπ(s)=Eπ[Rt+1+γvπ(St+1)∣St=s]
同理我们可以得到动作值函数的贝尔曼期望方程:
q π ( s , a ) = E π [ R t + 1 + γ q π ( S t + 1 , A t + 1 ) ∣ S t = s , A t = a ] q_{\pi}(s,a)=\mathbb{E}_{\pi}[R_{t+1}+\gamma q_{\pi}(\mathcal{S_{t+1},\mathcal{A}_{t+1}})|\mathcal{S_{t}=s,\mathcal{A}_{t}=a}] qπ(s,a)=Eπ[Rt+1+γqπ(St+1,At+1)∣St=s,At=a]
这里可能会对这个期望函数有点难理解,我们把它拆开来理解一下。
MDP-贝尔曼期望方程求V、Q
s \mathcal{s} s- a a a求 v v v
状态价值函数和动作价值函数的关系如下图所示:

图中空心圆圈表示状态,黑色的实心圆圈表示动作本身,连接状态的线条把该状态下能够采取的动作关联起来。数学公式描述如下:
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) v_{\pi}(s)=\sum_{a \in \mathcal{A}}\pi(a|s)q_{\pi}(s,a) vπ(s)=a∈A∑π(a∣s)qπ(s,a)
可以看出,在遵循策略时,状态的价值体系为:在该状态下,遵循某一策略,而采取所有可能动作的价值(动作值函数 q π ( s , a ) q_{\pi}(s,a) qπ(s,a)),按动作发生概率 π ( a ∣ s ) \pi(a|s) π(a∣s)的乘积求和。
a a a- s ′ \mathcal{s^{\prime}} s′求 q q q
类似的,一个动作价值函数也可以表示成状态价值函数的形式:

它表示:某一个状态下采取某一个动作的价值可以分为两部分:离开这个状态的及时奖励 r r r,和进入新的状态 s ′ s^{\prime} s′的概率与新的状态价值 v π ( s ′ ) v_{\pi}(s^{\prime}) vπ(s′)的乘积。数学形式如下所示:
q π ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a v π ( s ′ ) q_{\pi}(s,a)=\mathcal{R}_{s}^{a}+\gamma \sum_{s^{\prime}\in \mathcal{S}}\mathcal{P}_{ss^{\prime}}^{a}v_{\pi}(s^{\prime}) qπ(s,a)=Rsa+γs′∈S∑Pss′avπ(s′)
s \mathcal{s} s- a a a- s ′ \mathcal{s}^{\prime} s′求取 v v v
所谓的状态值函数求状态值函数的方法就是:通过下一个时刻的状态值函数 v ( s ′ ) v(s^{\prime}) v(s′),求取当前状态的状态值函数 v ( s ) v(s) v(s)。

可以看到,上图是动作值函数求状态值函数(上半部分),和状态值函数求动作值函数(下半部分)组合而得到的。其数学表达如下所示:
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a v π ( s ′ ) ) v_{\pi}(s)=\sum_{a \in \mathcal{A}} \pi(a | s)\left(\mathcal{R}_{s}^{a}+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^{a} v_{\pi}\left(s^{\prime}\right)\right) vπ(s)=a∈A∑π(a∣s)(Rsa+γs′∈S∑Pss′avπ(s′))
a a a- s ′ s^{\prime} s′- a ′ a^{\prime} a′求取 q q q
所谓的动作值函数求动作值函数的方法就是:通过下一个时刻的状态下采取的动作值函数 q π ( s ′ , a ′ ) q_{\pi}\left(s^{\prime}, a^{\prime}\right) qπ(s′,a′),求取当前状态下的动作值函数 q π ( s , a ) q_{\pi}(s, a) qπ(s,a)。

类似的可以得到如下数学表达式:
q π ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a ∑ a ′ ∈ A π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) q_{\pi}(s, a)=\mathcal{R}_{s}^{a}+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^{a} \sum_{a^{\prime} \in \mathcal{A}} \pi\left(a^{\prime} | s^{\prime}\right) q_{\pi}\left(s^{\prime}, a^{\prime}\right) qπ(s,a)=Rsa+γs′∈S∑Pss′aa′∈A∑π(a′∣s′)qπ(s′,a′)
MDP-最优值函数
最优状态价值函数
最优状态价值函数指的是在从所有策略中产生的状态价值函数中,寻找到一个能使得状态 s s s获得最大价值的策略所对应的那个值函数,数学表达形式如下所示:
v ∗ ( s ) = max π v π ( s ) v_{*}(s)=\max_{\pi} v_{\pi}(s) v∗(s)=πmaxvπ(s)
最优动作值函数
类似的,最优动作值函数,指从所有策略中选择一个能使得行为值函数最大的那一个策略所对应的动作值函数,数学表达形式如下所示:
q ∗ ( s , a ) = max π q π ( s , a ) q_{*}(s,a)=\max_{\pi}q_{\pi}(s,a) q∗(s,a)=πmaxqπ(s,a)
最优值函数描述了MDP过程中最优的表现,当我们知道了最优值函数,MDP问题也就被求解出来了。
MDP-最优策略
在强化学习过程中最优策略,就是强化学习问题的解。一般很难找到最优策略,但是我们通过比较各个策略的好坏,可以得到一个较好的策略(局部最优解)。
- 什么是最优策略?
当对于任何状态 s s s,遵循策略 π \pi π的价值不小于遵循策略 π ′ \pi^{\prime} π′下的价值,则策略 π \pi π优于策略 π ′ \pi^{\prime} π′。
定理
这里对所有的MDP问题有一个定理:
- 存在一个最优策略 π ∗ \pi_{*} π∗,它比其他策略都好,或者相等,数学表示为: π ∗ ≥ π , ∀ π \pi_{*} \geq \pi, \forall \pi π∗≥π,∀π。
- 所有的最优策略有相同的最优值函数。 v π ∗ ( s ) = v ∗ ( s ) v_{\pi_{*}}(s)=v_{*}(s) vπ∗(s)=v∗(s)。
- 所有最优策略具有相同的动作价值函数。 q π ∗ ( s , a ) = q ∗ ( s , a ) q_{\pi_{*}}(s,a)=q_{*}(s,a) qπ∗(s,a)=q∗(s,a)。
- 如何寻找最优策略?
大体思路是:通过最大化最优动作值函数来找到最优策略。
通过选取最大化动作值函数找到最优策略。数学表达如下所示:
π ∗ ( a ∣ s ) = { 1 if a = argmax a ∈ A q ∗ ( s , a ) 0 otherwise \pi_{*}(a | s)=\left\{\begin{array}{ll} {1} & {\text { if } a=\underset{a \in \mathcal{A}}{\operatorname{argmax}}\ \ q_{*}(s, a)} \\ {0} & {\text { otherwise }} \end{array}\right. π∗(a∣s)={10 if a=a∈Aargmax q∗(s,a) otherwise
所以对于MDP来说这里肯定是存在一个最优策略的。如果我们知道了最优动作值函数 q ∗ ( s , a ) q_{*}(s,a) q∗(s,a),我们就相当于知道了最优策略。
MDP-贝尔曼最优方程求 V ∗ V_{*} V∗, Q ∗ Q^{*} Q∗
s \mathcal{s} s- a a a求 v ∗ v_{*} v∗

其数学表达式如下所示:
v ∗ ( s ) = max a q ∗ ( s , a ) v_{*}(s)=\max _{a} q_{*}(s, a) v∗(s)=amaxq∗(s,a)
a a a- s ′ \mathcal{s^{\prime}} s′求 q ∗ q_{*} q∗

其数学表达式如下所示:
q ∗ ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a v ∗ ( s ′ ) q_{*}(s, a)=\mathcal{R}_{s}^{a}+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^{a} v_{*}\left(s^{\prime}\right) q∗(s,a)=Rsa+γs′∈S∑Pss′av∗(s′)
s \mathcal{s} s- a a a- s ′ \mathcal{s}^{\prime} s′求取 v ∗ v_{*} v∗

其数学表达式如下所示:
v ∗ ( s ) = max a R s a + γ ∑ s ′ ∈ S P s s ′ a v ∗ ( s ′ ) v_{*}(s)=\max _{a} \mathcal{R}_{s}^{a}+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^{a} v_{*}\left(s^{\prime}\right) v∗(s)=amaxRsa+γs′∈S∑Pss′av∗(s′)
a a a- s ′ s^{\prime} s′- a ′ a^{\prime} a′求取 q ∗ q_{*} q∗

其数学表达式如下所示:
q ∗ ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a max a ′ q ∗ ( s ′ , a ′ ) q_{*}(s, a)=\mathcal{R}_{s}^{a}+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^{a} \max _{a^{\prime}} q_{*}\left(s^{\prime}, a^{\prime}\right) q∗(s,a)=Rsa+γs′∈S∑Pss′aa′maxq∗(s′,a′)
贝尔曼方程的求解一般通过迭代算法进行,比如策略迭代、值迭代、Q-Learning等。
我的微信公众号名称:深度学习与先进智能决策
微信公众号ID:MultiAgent1024
公众号介绍:主要研究分享深度学习、机器博弈、强化学习等相关内容!期待您的关注,欢迎一起学习交流进步!