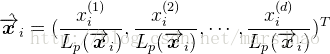大数据蕴含巨大价值,引起了社会各界的高度关注。大数据的来源多种多样,从现实世界中采集的数据大体上都是不完整、不一致的脏数据,无法直接进行数据挖掘和分析,或分析挖掘的结果差强人意。为了提高数据分析挖掘的质量,需要对数据进行预处理。
数据预处理方法主要包括数据清洗、数据集成、数据转换和数据消减。
1 .数据清洗
现实世界的数据常常是不完全的、含噪声的、不一致的。数据清洗过程包括缺失数据处理、噪声数据处理,以及不一致数据处理。
对于缺失的数据,可以采用忽略该条记录、手动补充缺失值、利用默认值填补缺失值、利用均值填补缺失值、利用最可能的值填补缺失值等方法处理。
对于噪声数据,可采用Bin方法、聚类分析方法、人机结合检测方法、回归方法来处理。
对于不一致的数据,可以利用它们与外部的关联,手动解决这类问题。
2 .数据集成
大数据处理常常涉及数据集成操作,即将来自多个数据源的数据,如数据库、数据立方、普通文件等,结合在一起并形成一个统一的数据集合,以便为数据处理工作的顺利完成提供完整的数据基础。
在数据集成过程中,需要考虑解决以下几个问题。
(1)模式集成问题。
模式集成问题指如何使来自多个数据源的现实世界的实体相互匹配,这其中涉及实体识别问题。
例如,如何确定一个数据库中的“custom_id”与另一个数据库中的“custome_number”是否表示同一实体。
(2)冗余问题。
冗余问题是数据集成中经常发生的另一个问题。若一个属性可以从其他属性中推演出来,则这个属性就是冗余属性。
例如,一个顾客数据表中的平均月收入属性就是冗余属性,显然它可以根据月收入属性计算出来。此外,属性命名的不一致也会导致集成后的数据集出现数据冗余问题。
(3)数据值冲突检测与消除问题
数据值冲突检测与消除是数据集成中的另一个问题。在现实世界实体中,来自不同数据源的属性值或许不同。产生这种问题的原因可能是表示、比例尺度,或编码的差异等。
例如,重量属性在一个系统中采用公制,而在另一个系统中却采用英制;价格属性在不同地点采用不同的货币单位。这些语义的差异为数据集成带来许多问题。
3 .数据转换
数据转换就是将数据进行转换或归并,从而构成一个适合数据处理的描述形式。常用的转换策略如下。
(1)规格化处理。
规格化处理就是将一个属性取值范围投射到一个特定范围之内,以消除数值型属性因大小不一而造成挖掘结果的偏差,常常用于神经网络、基于距离计算的最近邻分类和聚类挖掘的数据预处理。对于神经网络,采用规格化后的数据不仅有助于确保学习结果的正确性,而且也会帮助提高学习的效率。对于基于距离计算的挖掘,规格化方法可以帮助消除因属性取值范围不同而影响挖掘结果的公正性。
(2)属性构造处理。
属性构造处理就是根据已有属性集构造新的属性,以帮助数据处理过程。属性构造方法可以利用已有属性集构造出新的属性,并将其加入现有属性集合中以挖掘更深层次的模式知识,提高挖掘结果准确性。
(3)数据离散化处理。
数据离散化处理是将数值属性的原始值用区间标签或概念标签替换的过程,它可以将连续属性值离散化。连续属性离散化的实质是将连续属性值转换成少数有限的区间,从而有效地提高数据挖掘工作的计算效率。
(4)数据泛化处理。
数据泛化处理就是用更抽象(更高层次)的概念来取代低层次或数据层的数据对象,它广泛应用于标称数据的转换。例如,街道属性可以泛化到更高层次的概念,如城市、国家;数值型属性(如年龄属性),可以映射到更高层次的概念,如青年、中年和老年。
4. 数据消减
对大规模数据进行复杂的数据分析通常需要耗费大量的时间,这时就需要使用数据消减技术了。数据消减技术的主要目的是从原有巨大数据集中获得一个精简的数据集,并使这一精简数据集保持原有数据集的完整性。这样在精简数据集上进行数据挖掘就会提高效率,并且能够保证挖掘出来的结果与使用原有数据集所获得的结果基本相同。
数据消减的主要策略有以下几种[6]。
(1)数据聚合(Data Aggregation),如构造数据立方(数据仓库操作)。
(2)维数消减(Dimension Reduction),主要用于检测和消除无关、弱相关或冗余的属性或维(数据仓库中属性),如通过相关分析消除多余属性。
(3)数据压缩(Data Compression), 利用编码技术压缩数据集的大小。
(4)数据块消减(Numerosity Reduction),利用更简单的数据表达形式,如参数模型、非参数模型(聚类、采样、直方图等),来取代原有的数据。此外,利用基于概念树的泛化(Generalization)也可以实现对数据规模的消减。
以上内容摘自《大数据采集与处理》一书。