| 图源
皮尔逊相关是计算两个变量之间线性相关关系,或者两个向量共线程度的常用指标,应返回衡量相关程度的r值,和相关显著程度的p值。我们熟知的工具包,如pandas,numpy和scipy等,只能计算单个变量x与变量y之间的相关值,或者多个变量两两相关的相关矩阵。当我们想要分别计算多个变量X与y之间的相关关系时,就需要自己手撕代码。如果觉得手撕代码太费头发,或者对代码不怎么精通,那么就往下看吧。笔者废了好大一把头发,基于numpy和scipy撕三个函数方法,帮你快速实现多个变量与y之间的相关关系,并同时返回r和p值。
copyright© 意疏:https://blog.csdn.net/sinat_35907936/article/details/123805702
单个变量与y的皮尔逊相关
简单描述一下我们常用的求皮尔逊相关方法的使用。如果目标是求两个变量之间相关关系,并且需要返回p值,用scipy。如果是求多个变量两两相关的相关矩阵,用numpy和pandas,具体用什么,取决于输入是DataFrame还是numpy数组。
假设我们有以下数据,变量x和变量y都具有100个观测值。
import numpy as npnp.random.seed(3)
x= 2 + np.random.random(100)
y = 1 + np.random.random(100)
输入x,y,都是一维向量,其返回向量x与向量y的r和p值。对上述模拟数据求相关,如下。
import numpy as np
from scipy.stats import pearsonrnp.random.seed(3)
x= 2 + np.random.randn(100)
y = 1 + np.random.randn(100)
r, p = pearsonr(x, y)print(r, p)
#-0.25690193664486277 0.009874914626309943
输入就是DataFrame本身,函数计算表格中任意两列两两之间的相关值(注意一个变量的所有观测值放一列),最后返回一个相关矩阵,不包含p值。注意到该函数不包含y,要求x与y的相关关系,需要把x和y拼接在一起,再调用该方法。对上述模拟数据求相关,如下。
import numpy as np
import pandas as pdnp.random.seed(3)
x= 2 + np.random.randn(100)
y = 1 + np.random.randn(100)# 拼接
xy = np.vstack((x, y)).T
pd_xy = pd.DataFrame(xy)r_mat = pd_xy.corr()
print(r_mat)
# 0 1
# 0 1.000000 -0.256902
# 1 -0.256902 1.000000r = np.array(r_mat.iloc[0,1].squeeze())
print(r)
# -0.25690193664486294
该方法自由度比较高,输入X可以是向量或矩阵,输入y也可以是向量或者矩阵且不是必要参数,返回一个相关矩阵,不包含p值。当输入只有x时,效果与上述pandas相同(注意一个变量的所有观测值默认放一行,设置rowvar=False,一个变量的所有观测值将放一列),当x与y都存在时,函数会自动拼接x和y,形成xy,再求相关矩阵,相当于省去了pandas里拼接的步骤。对上述模拟数据求相关,如下。
import numpy as npnp.random.seed(3)
x= 2 + np.random.randn(100)
y = 1 + np.random.randn(100)# 自动拼接
r_mat = np.corrcoef(x,y, rowvar=False)
print(r_mat)
# [[ 1. -0.25690194]
# [-0.25690194 1. ]]r = r_mat[0,1].squeeze()
print(r)#-0.2569019366448628
copyright© 意疏:https://blog.csdn.net/sinat_35907936/article/details/123805702
多个变量与y的皮尔逊相关
假设我们有以下数据,X包含10个变量,每个变量1000个观测值,变量y包含1000个观测值。现在需要求X中每一个变量与y的皮尔逊相关,然后分别返回r和p。
import numpy as npnp.random.seed(3)X = 2 + np.random.randn(1000,10)
y = 1 + np.random.randn(1000)
循环遍历所有的变量,这是最容易想到,最简单,却非常低效的方法。在变量很多的时候,这种方法的效率将远远低于后面两种方法。
# -*- coding: utf-8 -*-
"""
@author: CSDN 意疏
"""
import time
import numpy as np
from scipy.stats import pearsonrdef batch_pearsonr(X, y):X = np.array(X)y = np.array(y)cols = X.shape[1]p_list = []r_list = []for col in range(cols):r, p = pearsonr(X[:, col], y)p_list.append(p)r_list.append(r)return np.array(r_list), np.array(p_list)if '__name == __main__':np.random.seed(3)X = 2 + np.random.randn(1000,100)y = 1 + np.random.randn(1000)st = time.time()r, p = batch_pearsonr(X, y)print(time.time()-st)print(r)print(p)
0.007961273193359375
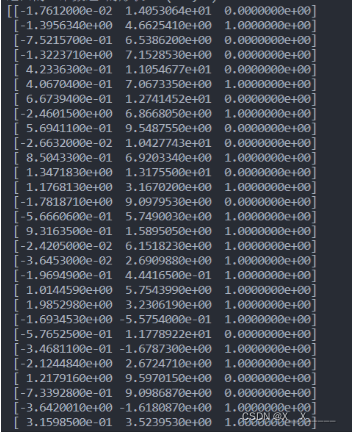
[-0.0227441 0.00720729 0.01410081 ... -0.028843 0.05403485 0.00350507]
[0.47249521 0.81993201 0.65605162 ... 0.36221919 0.08766555 0.91185276]
由皮尔逊相关的公式,推出多个变量与y相关的公式,然后实现。都是矩阵乘法,加上numpy高效率,这种方法效率会远高于上述循环单变量法。
r = 1 N ∑ i = 1 N ( x i − x ‾ ) ( y i − y ‾ ) σ x σ y (1) \tag 1 r = \cfrac {\cfrac 1 N \sum^N_{i=1}(x_i - \overline x)(y_i- \overline y)} {\sigma_{\bold x} \sigma_{\bold y}} r=σxσyN1∑i=1N(xi−x)(yi−y)(1)
= ( x − x ‾ ) T ( y − y ‾ ) N ∗ σ x σ y (2) \tag 2 = \cfrac {(\bold x- \overline x)^T( y - \overline y)} {N*\sigma_{\bold x} \sigma_{\bold y} } =N∗σxσy(x−x)T(y−y)(2)
r = ( X − X ‾ ) T ( y − y ‾ ) N ∗ σ X σ y (3) \tag 3 \bold r= \cfrac {(\bold X- \overline X)^T(\bold y - \overline y)} {N*\sigma_{\bold X} \sigma_{\bold y} } r=N∗σXσy(X−X)T(y−y)(3)
求p值参考了scipy源码,通过btdtr函数来实现。
# -*- coding: utf-8 -*-
"""
@author: CSDN 意疏
"""import time
import numpy as np
from scipy.special import btdtrdef batch_pearsonr(X, y):X = np.array(X)y = np.array(y)N = X.shape[0]X_center = X - X.mean(axis=0)X_std = X.std(axis=0)y_center = y - y.mean()y_std = y.std()r = np.dot(y_center.T, X_center)/(N*X_std*y_std)r[r>1]=1r[r<-1]=-1ab = N/2 - 1p = 2*btdtr(ab, ab, 0.5*(1 - abs(np.float64(r))))return r, pif '__name == __main__':np.random.seed(3)X = 2 + np.random.randn(1000,100)y = 1 + np.random.randn(1000)st = time.time()r, p = batch_pearsonr(X, y)print(time.time()-st)print(r)print(p)
在只有100个变量的情况下,公式法比循环单变量法效率也要高近一个数量级。
0.000997304916381836
[-0.0227441 0.00720729 0.01410081 ... -0.028843 0.05403485 0.00350507]
[0.47249521 0.81993201 0.65605162 ... 0.36221919 0.08766555 0.91185276]
一个变量与其他所有变量的相关值,是包含在变量间两两相关得到的相关矩阵中的,就像上述基于numpy和pandas的单变量相关。那么只要把X和y拼接起来,形成Xy,就可以通过算相关矩阵的方式,得到y与X中每一个变量的相关值。由于y拼在X后面,所以相关矩阵最后一行就是y与Xy中每个变量的相关值,去掉最后一个自相关值,就可以得到y与X中每一个变量的相关值了。为了代码简洁性,此处用numpy而非pandas。
numpy本身不返回p值,所以求p值参考了scipy源码,通过btdtr函数来实现。
# -*- coding: utf-8 -*-
"""
@author: CSDN 意疏
"""
import time
import numpy as np
from scipy.special import btdtrdef batch_pearsonr(X, y):N = X.shape[0]r_mat = np.corrcoef(X,y, rowvar=False)r = r_mat[-1,:-1].squeeze()ab = N/2 - 1p = 2*btdtr(ab, ab, 0.5*(1 - abs(np.float64(r))))return r, pif '__name == __main__':np.random.seed(3)X = 2 + np.random.randn(1000,100)y = 1 + np.random.randn(1000)st = time.time()r, p = batch_pearsonr(X, y)print(time.time()-st)print(r)print(p)
从模拟数据结果上看,虽然相关矩阵大量值都是白算的,但是它的效率却比循环单变量法高很多,与公式法相当,但赢在代码量少。不过当变量数目非常多的时候,这种方法效率可能比循环单变量法还低,因为涉及大量的不必要计算。
0.0010364055633544922
[-0.0227441 0.00720729 0.01410081 ... -0.028843 0.05403485 0.00350507]
[0.47249521 0.81993201 0.65605162 ... 0.36221919 0.08766555 0.91185276]
copyright© 意疏:https://blog.csdn.net/sinat_35907936/article/details/123805702
参考
https://blog.csdn.net/sinat_35907936/article/details/115253078?spm=1001.2014.3001.5501
https://github.com/scipy/scipy/blob/v1.8.0/scipy/stats/_stats_py.py#L3900-L4117