常见的可视化试图列举
可视化视图可以分成4大类:比较、联系、构成和分布。他们的特点如下:
- 1、比较:比较数据之间的各类别的关系,或者是他们随着时间的变化趋势,比如折线图;
- 2、联系:查看两个或者两个以上的变量之间的关系,比如散点图;
- 3、构成:每个部分占整体的百分比,或者是随着时间的百分比变化,比如饼状图;
- 4、分布:关注单个变量,或者多个变量的分布情况,比如直方图。
同样,按照变量的个数,可以把可视化视图划分成为单变量分析和多变量分析:
- 1、单变量分析指的是一次只关注一个变量。比如只关注“身高”这个变量,来看身高的取值分布,而暂时忽略其他的变量。
- 2、多变量分析可以让我们在一张图上查看两个以上的变量的关系。比如身高和年龄。可以理解为是同一个人的两个参数,这样在同一张图中可以看到每个人的身高和年龄的取值,从而可以分析出这两个变量之间是否存在某种联系。
可视化的试图分门别类,主要有下面的10种比较常用:1、散点图、2、折线图、3、直方图、4、条形图、5、箱型图、6、饼图、7、热力图、8蜘蛛图、9、二元变量分布、10、二元变量分布以及成对关系。
1、散点图:
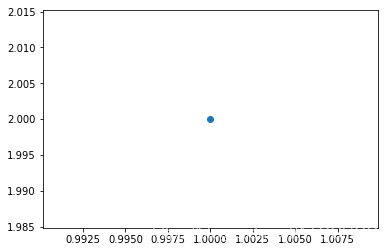
举个最简单例子,一个点的可视化就是:
import matplotlib.pyplot as pltplt.scatter(1, 2, marker="o") # mark的值可以设置为"x",">","o"plt.show()
上面使用的是Matplotlib库,下面也可以使用基于Matplotlib的seaborn这个更高级的库,实现代码:
import seaborn as sns# data就是我们需要传入的数据,数据是DataFrame类型,scatter 代表散点的意思,kind可以取其他的值,代表不同的绘制方式sns.jointplot(x,y,data=None,kind='scatter')
假设我们有很多数据,需要将这些数据画成散点图真么做?可以使用随机数来进行模拟:
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns# 数据准备N = 1000x = np.random.randn(N)y = np.random.randn(N)# 使用 Matplotlib 画散点图plt.scatter(x,y,marker='x')plt.show()# 使用seaborn 画散点图df = pd.DataFrame({'x':x,'y':y})sns.jointplot(x='x',y='y',data=df,kind='scatter',marker='v');plt.show()
效果图如下所示,先显示Matplotlib画出的图,然后显示使用Seaborn画出的图:
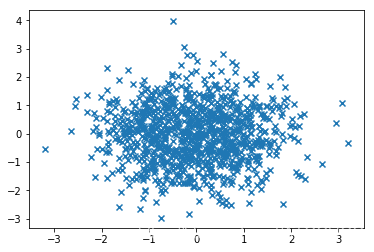
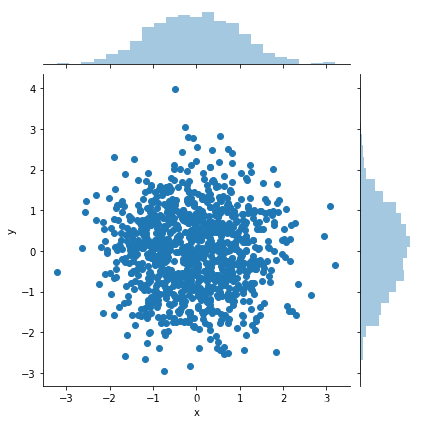
可以看到seaborn工具还帮我们做了密度统计,比纯粹的Matplotlib统计的数据更加丰富。
2、折线图
在Matplotlib中,我们可以直接使用plt.plot()函数,当然可以需要提前把数据按照x轴的大小进行排序,否则画出来的折线图就无法按照x轴递增的顺序展示
在Seaborn中,可以使用sns.lineplot(x,y,data=None)函数。其中x,y是data中的下标。data就是我们要传入的数据,一般是DataFrame的类型。
这里我们设置了x,y的数组。x数组代表时间(年),y数组可以随便设置几个取值,者几个值是可以没有顺序的,毕竟是折线图:
import pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns# 数据准备x = [2010,2011,2012,2013,2014,2015,2016,2017,2018,2019]y = [5,3,6,20,17,16,19,30,32,35]# 使用Matplotlib画出折线图plt.plot(x,y)plt.show()# 使用Seaborn画出折线图df = pd.DataFrame({'x':x,'y':y})sns.lineplot(x='x',y='y',data=df)plt.show()
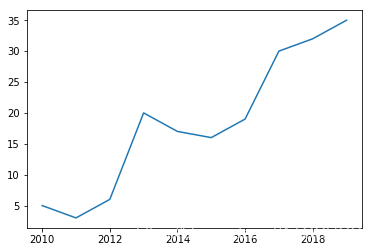
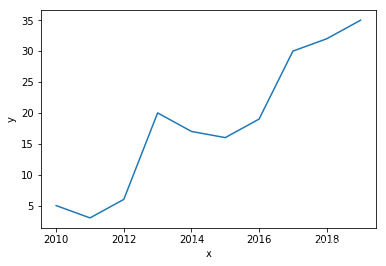
从上面的两个图像的形状可以知道,两个图是完全一样的,没有其他过多的内容,只是在seaborn中标记了x和y。
3、直方图
直方图是比较常见的试图,它是把横坐标等分成一定数量的小区间,这个小区间也在加“箱子”,然后在每一个“箱子”内部使用矩形条(bars)展示该箱子的箱子数(也就是y值),这样就完成了对数据集的直方图分布的可视化。
在Matplotlib中,我们使用plt.hist(x,bin=10)函数,其中参数x是一维数组,bins代表直方图中箱子的数量,默认是10。
在Seaborn中,我们使用sns.distplot(x,
bins=10,kde=True)函数。其中参数x是一维数组,bins代表的是直方图中的箱子数量,默认是10.
在Seaborn中,我们使用sns.distplot(x,bins=10,kde=True)函数。其中参数x是一堆数组,bins代表直方图中的箱子数量,kde代表显示核密度估计,默认是true,我们也可以把kde设置为False,不进行显示。核密度估计是通过该函数帮助我们来估计概率密度的方法。
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns# 数据准备a = np.random.randn(100)s = pd.Series(a)# 使用Matplotlib画直方图plt.hist(s,bins=15) # 默认的bins是10plt.show()# 使用Seaborn 画直方图sns.distplot(s, kde=False)plt.show()# 进行核密度估计sns.distplot(s,kde=True)plt.show()
运行结果如下:
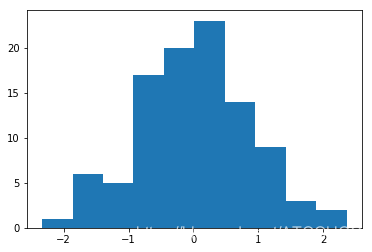
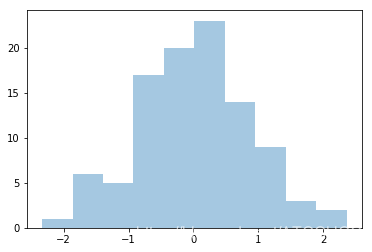
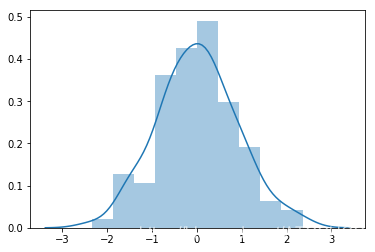
第三个图中,当设置kde为True之后,显示出核密度曲线图。
4、条形图
如果说通过直方图可以看到变量的数值分布,那么条形图可以帮助我们查看类别的特征。在条形图中,长条形的长度表示类别的频度,宽度表示类别
在Matplotlib中,使用plt.bar(x,height)函数,其中参数x代表x轴的位置的序列,height是y轴的数值序列,也就是柱子的高度。
在Seaborn中,我们使用sns.barplot(x=None,y=None,data=None)函数。其中参数data为DataFrame类型,x,y是data中的变量。
import matplotlib.pyplot as pltimport seaborn as sns# 数据准备x = ['Cat1','Cat2','Cat3','Cat4','Cat5']y = [5,4,8,12,7]# 使用Matplotlib画条形图plt.bar(x,y)plt.show()# 使用Seaborn画条形图sns.barplot(x,y)plt.show()
运行的效果图如下所示:
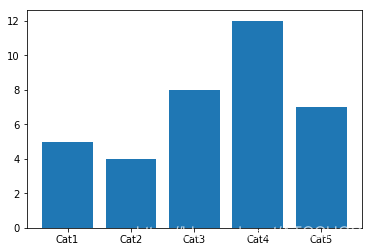
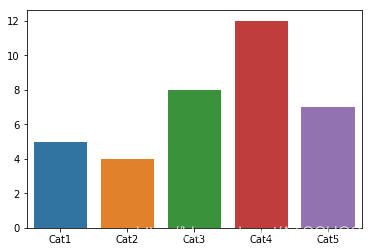
区别其实不算大,就是有没有颜色的区别。
5、箱线图
箱线图,又称为盒式图,由五个数值组成:最大值(max)、最小值(min)、中位数(median)和上下四分位数(Q3,Q1)。它可以帮我们分析出数据的差异性、离散程度和异常值等。
在Matplotlib中。使用plt.boxplot(x,lablels=None)函数,其中参数x代表绘制箱线图的数据,labels是缺失值,可以为箱线图添加标签。
在Seaborn中。使用sns.boxplot(x=None,y=None,data=None)函数。其中参数data为DataFrame类型,x,y是data中的变量。
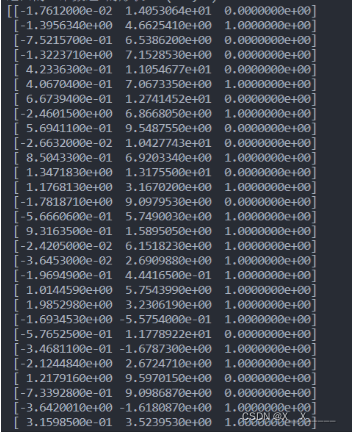
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt #不导入.pyplot也没事import seaborn as sns# 数据准备# 生成 0-1 之间的 10 * 4 维度的数据data = np.random.normal(size=(10,4)) # 3列对应3个标签print(data)labels = ['A','B','C','D']# 使用Matplotlib画出箱线图plt.boxplot(data, labels = labels) #数据按照列显示plt.show()# 使用Seaborn 画出箱线图df = pd.DataFrame(data, columns = labels)sns.boxplot(data=df)plt.show()
运行的结果如下:
[[ 0.3254286 1.07300549 0.01592661 0.11135052][ 0.00691687 0.91592263 -0.9133012 -0.16704924][-0.14681058 -1.33135914 -0.48755575 -0.99630723][ 0.00643802 -0.64605021 -0.1261428 -0.27082019][ 0.35080959 1.87987406 1.57485532 0.75964526][-1.1094676 0.10937961 0.72612711 -0.23571834][-1.25257039 0.29394106 0.19746625 -0.32605526][ 1.56447536 0.10158119 0.57406157 -0.89720202][ 1.60596428 -0.91531169 0.89972146 -0.97846049][-2.09628817 1.44807861 0.33475465 1.13538435]]
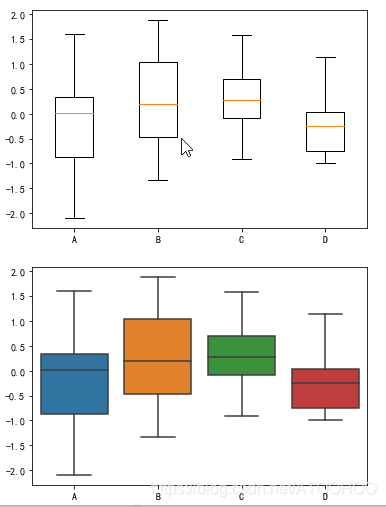
在上面的代码中,生成-2 到 2之间的10*4维度的数据,,然后分别使用Matplotlib和Seaborn进行箱线图的绘制。
6、饼图
饼图是常用的统计学模块,可以显示每个部分大小与总和之间的比例。在Python的数据可视化中,其实用的并不算多,主要是使用Matplotlib的pie函数来实现它。
在Matplotlib中,使用plt.pie(x,labels-None)函数,其中参数x代表要绘制饼图的数据,labels是缺省值,可以为饼图添加标签。
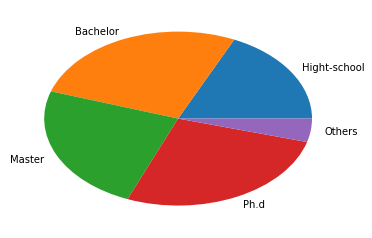
这里设置了数组labels,分别代表高中、本科、硕士、博士和其他的几种学历的分类标签。nums代表这些学历对应的人数。
import matplotlib.pyplot as plt%matplotlib inline# 数据准备nums = [25,37,33,37,6]labels = ['Hight-school','Bachelor','Master','Ph.d','Others']# 使用Matplotlib画出饼图plt.pie(x=nums,labels=labels)plt.show()
运行的结果如下所示,呈现扁状的原因是在Python2中的版本的问题在Python3中就不会有这样的情况:
7、热力图
热力图,英文名称为heat
map,是一种矩阵的表示方法,其中矩阵中的元素值用颜色来代表,不同的颜色代表不同大小的值。通过颜色就能直观的知道某个位置上的值的大小。另外你也可以将这个位置上的颜色与数据集中的其他位置的颜色进行比较
热力图是一种非常直观的多元变量分析方法。
一般使用Seaborn的sns.heatmap(data)函数,其中data代表需要绘制的热力图数据
这里使用Seaborn中自带的数据集flights,该数据记录了1949年到1960年间,每个月的航班乘客的数量。
import matplotlib.pyplot as pltimport seaborn as snsimport pandas as pdfrom pandas import Series, DataFrame%matplotlib inline# 数据准备# flights = sns.load_dataset("flights") flights = DataFrame(pd.read_csv("./seaborn_dataset/flights.csv"))data=flights.pivot('year','month','passengers')# 用 Seaborn 画热力图sns.heatmap(data)plt.show()
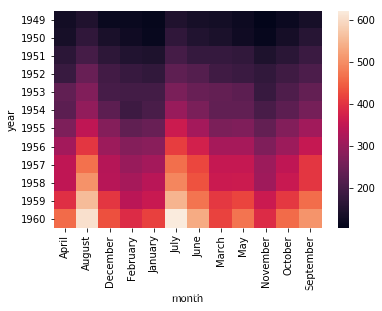
通过上面的图seaborn的heatmap函数,可以看到不同的年份,不同的月份的乘客数量的变化情况,其中颜色浅越浅的代表乘客的数量越多。
8、蜘蛛图
蜘蛛图显示的是一种一对多关系的方法。在蜘蛛图中,一个变量相对于另一个变量的显著性是清晰可见的。
假设我们需要给王者荣耀的玩家做一个战力图,指标一共包括推进、KDA、生存、团战、发育和输出的方法应该如何。
我们需要使用Matplotlib来进行画图,首先设置两个数组:labels和stats。他们分别保存这些属性的名称和属性值。
因为蜘蛛图是一个圆形,需要计算每个坐标的角度,然后对这些数值进行设置,所以要设定stats数组。并且需要在原有的angles和stats数组上增加一位,也就是添加数组的第一个元素。
import numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom matplotlib.font_manager import FontProperties# 数据准备labels = np.array([u"推进","KDA",u"生存",u"团战",u"发育",u"输出"])stats = [83,61,95,67,76,88]# 画图数据准备,角度、状态值angles = np.linspace(0, 2*np.pi, len(labels), endpoint=False) # 2代表的是平面显示stats = np.concatenate((stats,[stats[0]]))angles = np.concatenate((angles,[angles[0]]))# 用 matplotlib 画出蜘蛛图# 创建一个空白的对象fig = plt.figure()# 把画板分成一行一列ax = fig.add_subplot(111, polar=True)# 给图像上色ax.plot(angles, stats, 'o-', linewidth=1)ax.fill(angles, stats, alpha=0.25)# 设置中文字体,因为在Matplotlib对中文的支持不是很好,也可以修复这个bugfont = FontProperties(fname=r"/usr/share/fonts/truetype/arphic/uming.ttc",size=14)ax.set_thetagrids(angles * 180/np.pi, labels, FontProperties=font)plt.show()
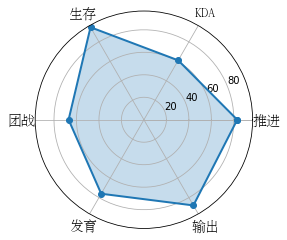
代码中flt.figure是创建一个空白的figure对象,这样做的目的是相当于在画画前先准备一个空白的画板。然后add_subplot(111)可以把画板划分成为1行1列。再使用ax.plot和ax.fill进行连线以及给图形上色。最后我们在相应的位置上显示出属性名。这里需要用到中文,Mapplotlib对中文的显示不是很友好,所以需要设置中文字体font,这个需要在调用前进行定义。使用fc-
list :lang=zh命令可以将系统的中文字体列举出来。
9、二元变量分布
如果想要查看两个变量之间的关系,就需要用到二元变量分布。当然二元变量分布有多种呈现的方式,例如开头的散点图就是二元分布的一种。
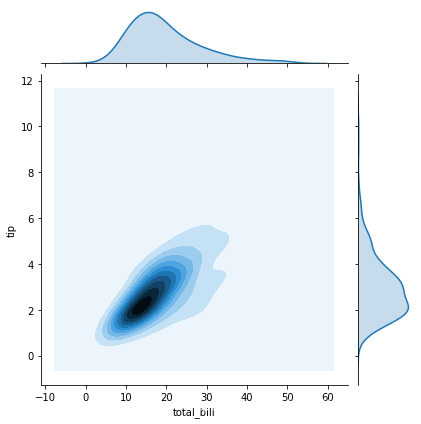
在Seaborn里面使用二元分布是非常方便的,直接使用sns.jointplot(x,y,data=None,kind)函数即可。其中kind表示不同的视图类型:“kind=scatter”代表散点图,"kind
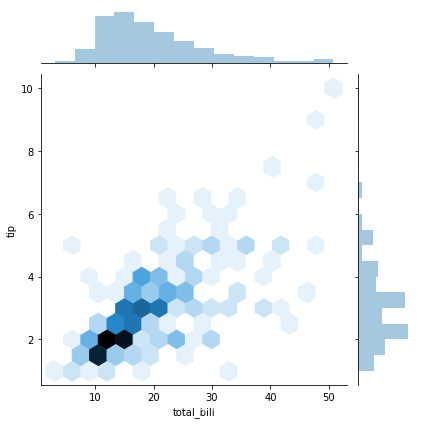
= ‘kde’"代表核密度图,"kind = ‘hex’"代表的是Hexbin图,它代表的是直方图的二维模拟。
这里我们使用Seaborn的自带tips,这个数据集记录了不同的顾客在餐厅的消费账单以及小费的情况。代码中的total_bill保存了客户的账单金额,tip是该客户给出的小费金额。可以使用Seaborn中的jointplot来探索这两个变量之间的关系。
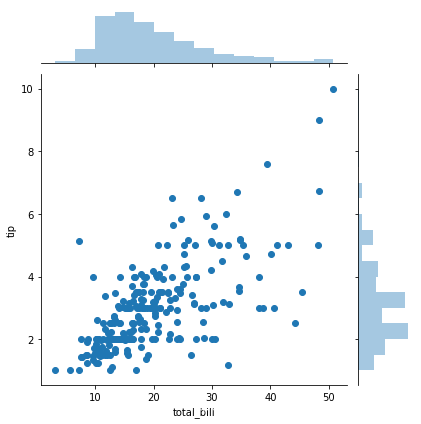
import matplotlib.pyplot as pltimport seaborn as snsimport pandas as pdfrom pandas import DataFrame# 数据准备# tips = sns.load_dataset("tips")tips = DataFrame(pd.read_csv("./seaborn_dataset/tips.csv"))print(tips.head(10))# 使用Seaborn 画出二元变量的分布图(散点图,核密度图,Hexbin图)# 研究的是顾客总的花费和付小费之间的关系sns.jointplot(x="total_bill", y="tip", data=tips, kind='scatter')sns.jointplot(x="total_bill", y="tip", data=tips, kind='kde')# 蜂窝图sns.jointplot(x="total_bill", y="tip", data=tips, kind='hex')plt.show()
运行的结果数据和图像如下所示:
total_bill tip sex smoker day time size0 16.99 1.01 Female No Sun Dinner 21 10.34 1.66 Male No Sun Dinner 32 21.01 3.50 Male No Sun Dinner 33 23.68 3.31 Male No Sun Dinner 24 24.59 3.61 Female No Sun Dinner 45 25.29 4.71 Male No Sun Dinner 46 8.77 2.00 Male No Sun Dinner 27 26.88 3.12 Male No Sun Dinner 48 15.04 1.96 Male No Sun Dinner 29 14.78 3.23 Male No Sun Dinner 2
10、成对关系图
如果要探索数据集中的多个成对双变量的分布,可以直接采用sns.pairplot()函数。它会同时展示出DataFrame中的每对变量的关系,另外在对角线上,你能看到每个变量自身作为单变量的分布情况。它可以说是探索性分析中的常用函数,可以很快帮助我们理解变量之间的关系。
pairplot函数的使用,就像是在DataFrame中使用的describe()函数一样方便,是数据探索中的常用函数。
这里使用Seaborn的自带的鸢尾花iris数据集,这个数据集将鸢尾花分成Setosa、Versicolour和Virginica三个品种,在这个数据集中,针对每一个品种,都有50条数据,每个数据包括4个属性,分别是花萼长度,花萼宽度、花瓣长度和花瓣宽度。这样通过这些数据,就可以来预测鸢尾花卉属于哪一个品种。
import matplotlib.pyplot as pltimport seaborn as snsimport pandas as pdfrom pandas import DataFrame# 数据准备# iris = sns.load_dataset("iris")iris = DataFrame(pd.read_csv("./seaborn_dataset/iris.csv"))# 使用Seaborn来画出成对关系sns.pairplot(iris)plt.show()
运行结果显示如下:
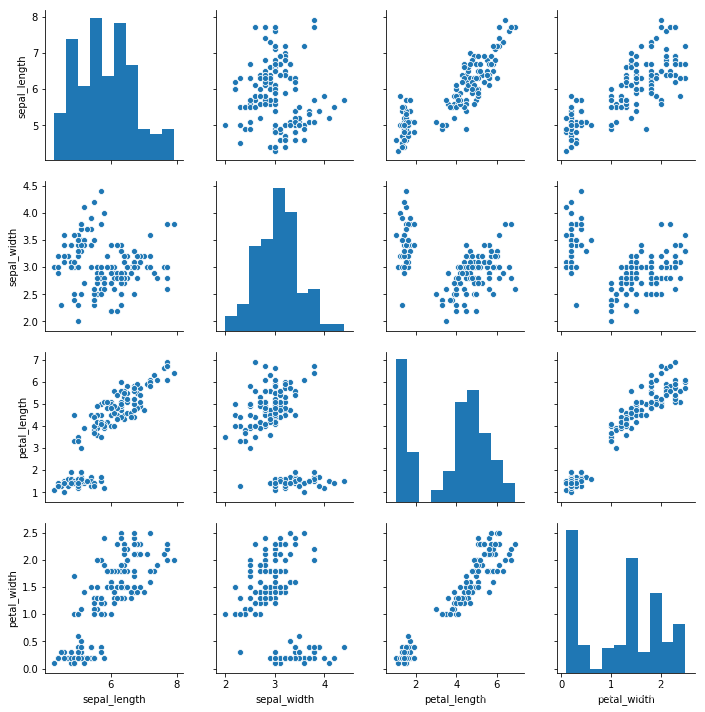
这里使用的Seaborn中的pairplot函数来对数据集中的多个双变量的关系进行探索,从上图可知,一共有sepal_length、sepal_width、petal_length和petal_width这4个变量,他们分别表示花萼长度、花萼宽度、花瓣长度和花瓣宽度。上图相当于4个变量两两之间的关系。比如矩阵中的第一张图代表的是花萼长度自身的分布图,它的右侧的这一张图代表的是花萼长度和花萼宽度的这两个变量之间的关系。