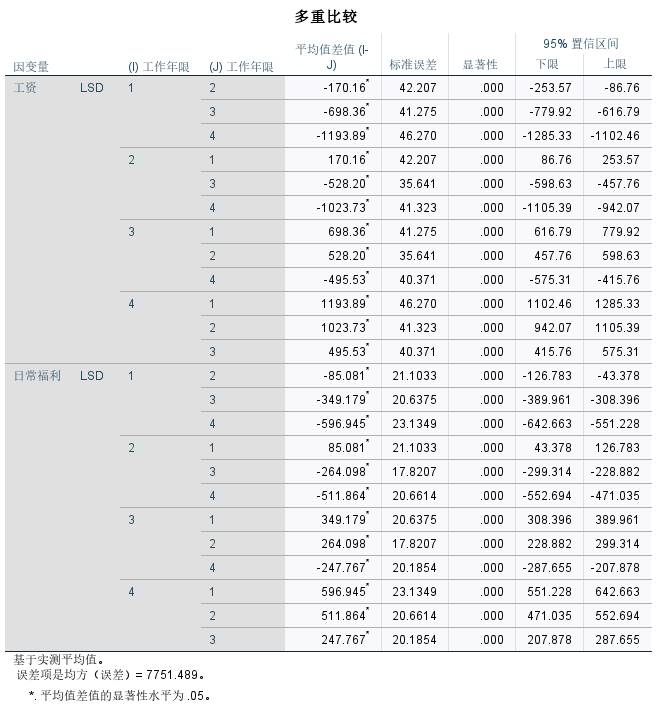
典型相关分析
1.典型相关分析的基本思想是首先在每组变量中找出变量的线性组合,使其具有最大相关性,然后再在每组变量中找出第二对线性组合,使其分别与第一对线性组合不相关,而第二对本身具有最大的相关性,如此继续下去,直到两组变量之间的相关性被提取完毕为止.有了这样线性组合的最大相关,则讨论两组变量之间的相关,就转化为只研究这些线性组合的最大相关,从而减少研究变量的个数.



#典型变量分析得到第一典型变量
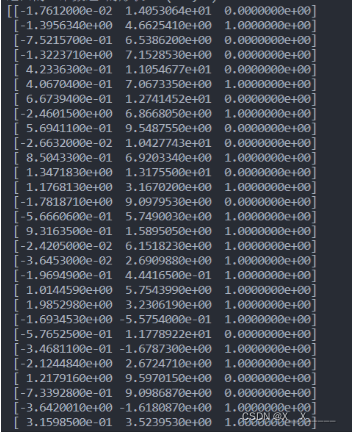
def CAA(X,Y):R= corrcoef(X,Y,rowvar=0)m, n = shape(X)p, q = shape(Y)# print(m,n)# print(p,q)R11=[]R22=[]R12=[]#计算相关系数for i in range(n):temp=R[i]a=temp[0:n]R11.append(a)for j in range(n,n+q):temp=R[j]a=temp[n:n+q]R22.append(a)for s in range(n):temp=R[s]a=temp[n:n+q]R12.append(a)R11=matrix(R11)R22 = matrix(R22)R12 = matrix(R12)R21=R12.T#计算特征值与特征向量M=(R11.I)*(R12)*(R22.I)*(R21)eigVals, eigVects = linalg.eig(mat(M)) # 计算特征值和特征向量eigValInd = sorted(eigVals,reverse=True) # 对特征值eigVals从大到小排序sorted_indices = np.argsort(-eigVals)#根据特征值的顺序排列相应的特征向量topk_evecs = eigVects[:, sorted_indices[:]]eig=sqrt(eigValInd)#计算特征值开平方# print("特征值开方=",eig)#计算第一对典型变量的相应的系数k,l=shape(topk_evecs)cout_t=[]for i in range(l):t=1.0/((topk_evecs[:,i].T)*R11*(topk_evecs[:,i]))cout_t.append(t[0,0])# print("cout_t=", cout_t)tt=[sqrt(i) for i in cout_t]# print("tt=",tt)a1=tt[0]*topk_evecs[:,0]#第一个特征值开方所对应的特征向量p1=(1.0/eig[0])*(R22.I)*R21*a1#第一个特征值开方所对应的特征向量print("特征值开方=", real(eig[0]))# print("a1=",a1)# print("p1=",p1)# print("a1.shape=", shape(a1))# print("p1.shape=",shape(p1))#进行显著性检验U1 = []V1 = []A=1for i in range(len(eigVals)):A*=(1-eigVals[i])Q1=-(m-1-1.0/2*(n+q+1))*log(A)# print("Q1=",Q1)if Q1>7.81:# print("第一主成分为显著性关联")for i in range(m):temp1 = 0for j in range(n):temp1+=a1[j]*X[i,j]# print(temp1)U1.append(temp1[0,0])for i in range(p):temp2 = 0for j in range(q):temp2+= p1[j] * Y[i, j]V1.append(temp2[0,0])# print("U1,VI=",U1,V1)else:print("第一主成分不显著关联")# A2=1# for i in range(1,len(eigVals)):# A2*=(1-eigVals[i])# Q2 = -(m - 2 - 1.0 / 2 * (n + q + 1)+1.0/(sqrt(eig[0]))) * log(A2)# print("Q2=", Q2)# if Q2>37.65:# print("第二主成分为显著性关联")# else :# print("第二主成分不显著关联")## A3=1# for i in range(2,len(eigVals)):# A3*=(1-eigVals[i])# Q3= -(m - 3 - 1.0 / 2 * (n + q + 1)) * log(A3)# print("Q3=", Q3)# if Q3>26.3:# print("第三主成分为显著性关联")# else :# print("第三主成分不显著关联")return U1,V1,eig[0]