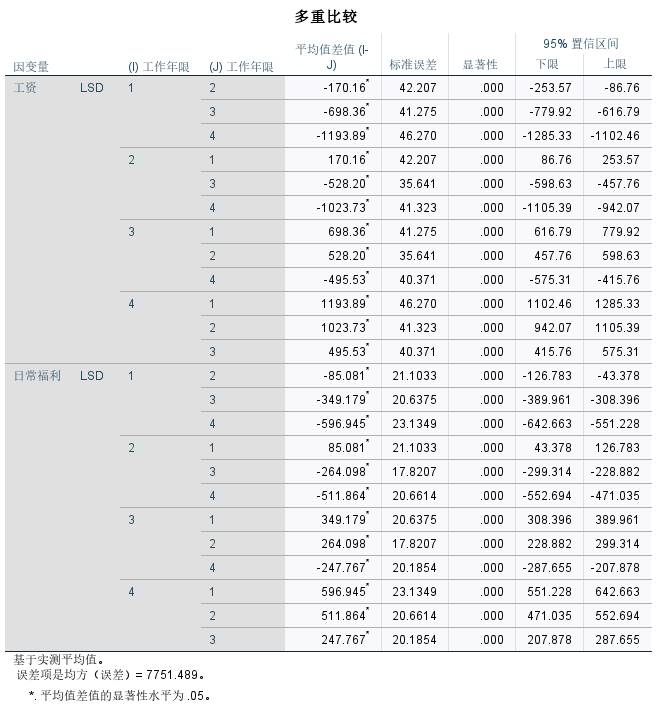
一、概述
在工程实践中,我们得到的数据会存在有缺失值、重复值等,在使用之前需要进行数据预处理。数据预处理没有标准的流程,通常针对不同的任务和数据集属性的不同而不同。数据预处理的常用流程为:去除唯一属性、处理缺失值、属性编码、数据标准化正则化、特征选择、主成分分析。
二、数据预处理方法
1. 去除唯一属性
唯一属性通常是一些id属性,这些属性并不能刻画样本自身的分布规律,所以简单地删除这些属性即可。
2. 处理缺失值
缺失值处理的三种方法:直接使用含有缺失值的特征;删除含有缺失值的特征(该方法在包含缺失值的属性含有大量缺失值而仅仅包含极少量有效值时是有效的);缺失值补全。
常见的缺失值补全方法:均值插补、同类均值插补、建模预测、高维映射、多重插补、极大似然估计、压缩感知和矩阵补全。
(1)均值插补
如果样本属性的距离是可度量的,则使用该属性有效值的平均值来插补缺失的值;如果的距离是不可度量的,则使用该属性有效值的众数来插补缺失的值。
(2)同类均值插补
首先将样本进行分类,然后以该类中样本的均值来插补缺失值。
(3)建模预测
将缺失的属性作为预测目标来预测,将数据集按照是否含有特定属性的缺失值分为两类,利用现有的机器学习算法对待预测数据集的缺失值进行预测。
该方法的根本的缺陷是如果其他属性和缺失属性无关,则预测的结果毫无意义,但是若预测结果相当准确,则说明这个缺失属性是没必要纳入数据集中的,一般的情况是介于两者之间。
(4)高维映射
将属性映射到高维空间,采用独热码编码(one-hot)技术。将包含K个离散取值范围的属性值扩展为K+1个属性值,若该属性值缺失,则扩展后的第K+1个属性值置为1。
这种做法是最精确的做法,保留了所有的信息,也未添加任何额外信息,若预处理时把所有的变量都这样处理,会大大增加数据的维度。这样做的好处是完整保留了原始数据的全部信息、不用考虑缺失值;缺点是计算量大大提升,且只有在样本量非常大的时候效果才好。
(5)多重插补(MultipleImputation,MI)
多重插补认为待插补的值是随机的,实践上通常是估计出待插补的值,再加上不同的噪声,形成多组可选插补值,根据某种选择依据,选取最合适的插补值。
(6)压缩感知和矩阵补全
(7)小结
插补处理只是将未知值补以我们的主观估计值,不一定完全符合客观事实。在许多情况下,根据对所在领域的理解,手动对缺失值进行插补的效果会更好。
3. 特征编码
(1)特征二元化
特征二元化的过程是将数值型的属性转换为布尔值的属性,设定一个阈值作为划分属性值为0和1的分隔点。
(2)独热编码(One-HotEncoding)
独热编码采用N位状态寄存器来对N个可能的取值进行编码,每个状态都由独立的寄存器来表示,并且在任意时刻只有其中一位有效。
独热编码的优点:能够处理非数值属性;在一定程度上扩充了特征;编码后的属性是稀疏的,存在大量的零元分量。
4. 数据标准化、正则化
数据标准化
数据标准化是将样本的属性缩放到某个指定的范围。
数据标准化的原因:
某些算法要求样本具有零均值和单位方差;
需要消除样本不同属性具有不同量级时的影响:①数量级的差异将导致量级较大的属性占据主导地位;②数量级的差异将导致迭代收敛速度减慢;③依赖于样本距离的算法对于数据的数量级非常敏感。
min-max标准化:对于每个属性,设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x',其公式为:新数据=(原数据 - 最小值)/(最大值 - 最小值)
z-score标准化:基于原始数据的均值(mean)和标准差(standarddeviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。新数据=(原数据- 均值)/ 标准差
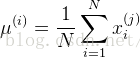
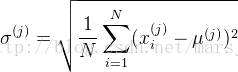
均值和标准差都是在样本集上定义的,而不是在单个样本上定义的。标准化是针对某个属性的,需要用到所有样本在该属性上的值。
数据正则化
数据正则化是将样本的某个范数(如L1范数)缩放到到位1,正则化的过程是针对单个样本的,对于每个样本将样本缩放到单位范数。
设数据集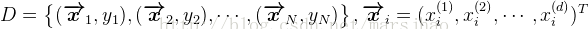
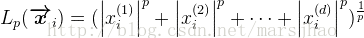
正则化后的结果为:每个属性值除以其Lp范数:
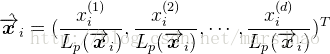
5. 特征选择
从给定的特征集合中选出相关特征子集的过程称为特征选择,进行特征选择的两个主要原因是:减轻维数灾难问题;降低学习任务的难度。
进行特征选择必须确保不丢失重要特征。常见的特征选择方法分为三类:过滤式(filter)、包裹式(wrapper)、嵌入式(embedding)。
过滤式选择:该方法先对数据集进行特征选择,然后再训练学习器。特征选择过程与后续学习器无关。Relief是一种著名的过滤式特征选择方法。
包裹式选择:该方法直接把最终将要使用的学习器的性能作为特征子集的评价原则。其优点是直接针对特定学习器进行优化,因此通常包裹式特征选择比过滤式特征选择更好,缺点是由于特征选择过程需要多次训练学习器,故计算开销要比过滤式特征选择要大得多。
嵌入式选择。
6. 稀疏表示和字典学习
字典学习:学习一个字典,通过该字典将样本转化为合适的稀疏表示形式。
稀疏编码:获取样本的稀疏表达。