抱歉了,前面几篇DDD的文章我删除了,本篇是前面发表的几篇DDD的汇总,内容有修改。
领域驱动设计(DDD)是一种业务领域建模方法论、业务架构设计方法论,战略设计阶段从业务领域视角划分领域边界,抽象业务建立领域模型;战术设计阶段则根据清晰的领域边界、领域模型进行架构设计与开发实现。
DDD解决了核心复杂业务设计问题,简化业务系统的实现,让业务逻辑高度内聚,与基础设施、框架解耦,清晰的领域边界解决微服务的拆分问题。聚合之间通过聚合根ID引用与领域事件松耦合,保持高内聚、松耦合让项目代码随着业务需求的不断迭代保持整洁。
本篇笔者以近期的一个项目实战跟大家分享笔者目前对DDD的理解,以及在实战DDD过程中遇到的问题思考与总结,仅个人经验,偏战术设计。
从实战项目中理解DDD核心概念
领域通常指的就是业务范围,每个公司都有自己明确的业务范围。通常每个公司内部都有很多个系统,如一家电商公司可能会有物流系统、电商系统、直播系统等等,每个系统做的事情则是更细分的领域。
茉莉红交所(红探长)项目是笔者入职茉莉数科集团后做的第一个项目,也是一个新的项目,由于没有历史包袱,笔者从零开始搭建整个项目,因此选择在该项目试行DDD。
该项目业务是OTO(线上到线下)探店,OTO探店就是该项目的领域。
探店其实是一种商家线上付费下单、平台为商家匹配达人、达人线下探店线上内容推广的内容营销模式,可以是品尝美食或是免门票游玩景点等,达人最终通过短视频、直播、图文内容等方式为商家做推广。那么无论是探美食店、探游乐园,探店都是这个领域的核心。
在探店这个领域中,核心的业务名词有:商家、达人、店铺、订单、任务,而核心事件有:店铺入驻、商家发布订单、达人接单等。
附上此项目对应版本的架构设计图:
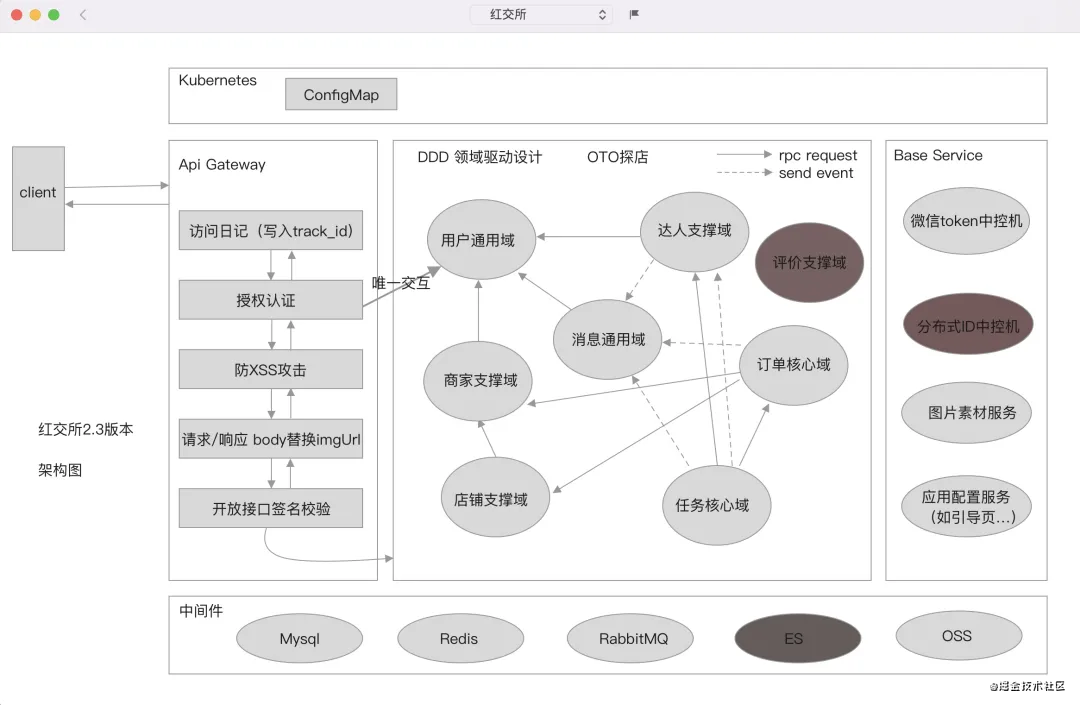 提示:中间部分不是每个限界上下文对应一个微服务,可以是多个限界上下文合并在一个微服务。对于为什么要这样设计可参考我的另一篇文章《这个项目为什么这样架构设计?》。
提示:中间部分不是每个限界上下文对应一个微服务,可以是多个限界上下文合并在一个微服务。对于为什么要这样设计可参考我的另一篇文章《这个项目为什么这样架构设计?》。
限界上下文是业务概念的边界,是业务问题最小粒度的划分。在OTO探店业务领域中会包含多个限界上下文,我们通过找出这些确定的限界上下文对系统进行解耦,要求每一个限界上下文其内部必须是紧密组织的、职责明确的、具有较高的内聚性。
我们划分出的限界上下文如下图所示。
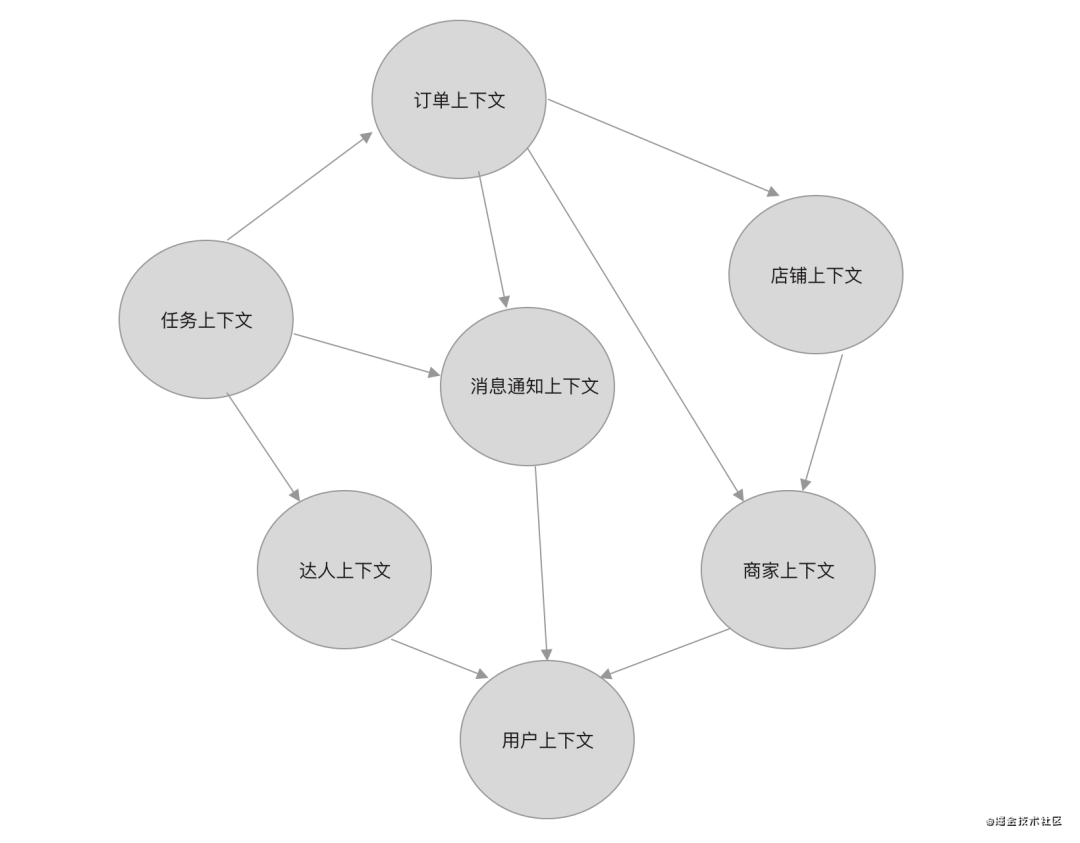
提示:为什么将任务和订单拆分为不同限界上下文(任务不是作为订单聚合根的实体,而是作为一个独立聚合的聚合根)?这是因为商家发布的一个订单允许有不同的多个达人接单,一个达人也可以接不同商家的订单,这并不是简单的一对多关系。这更像是商品与订单的关系,而不是订单与订单item的关系。
在划分出限界上下文后,还需要根据限界上下文识别出问题子域。问题子域是对业务问题的划分,相对限界上下文来说,是对业务问题更大粒度的划分。
核心(子)域:产品的核心竞争力、盈利来源;
通用子域:常见的,不同领域都可共用的,可通过购买就能使用的;
支撑子域:非核心域、又非通用域,具有个性化需求,用于支撑核心域运作;
根据限界上下文,我们划分出的子域如下图所示。
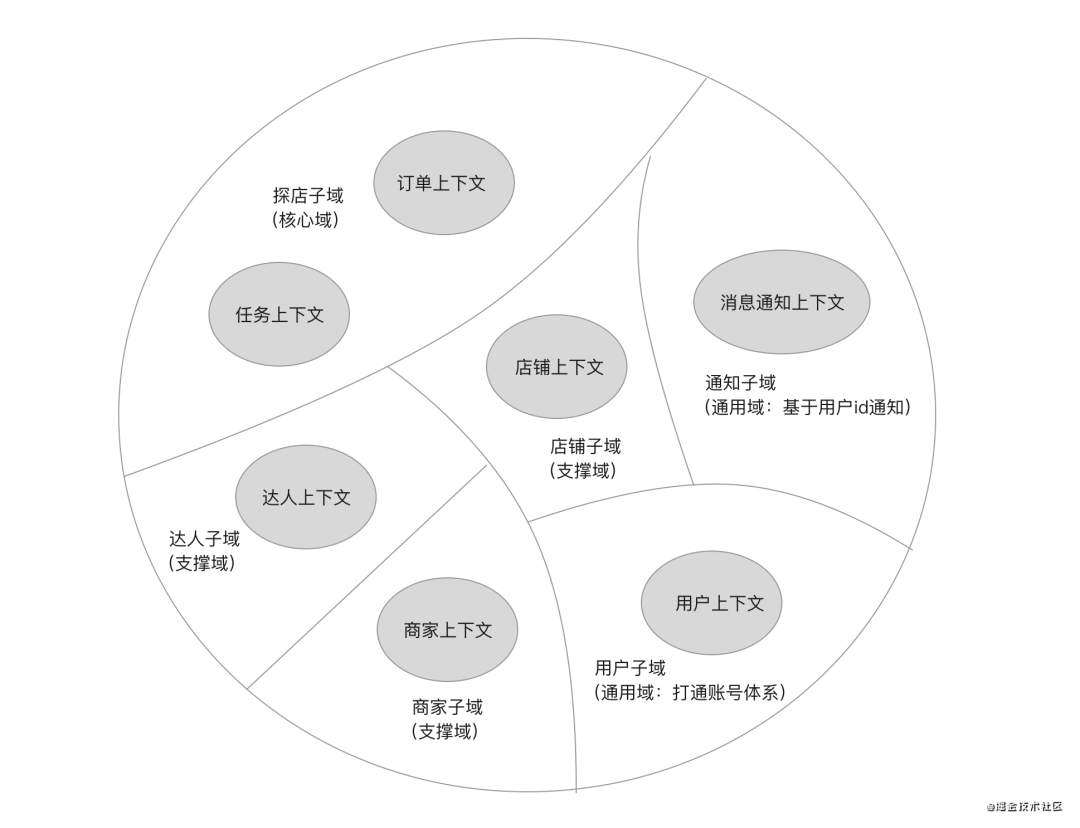
OTO探店核心域:商家下单、平台审核订单、达人接单、平台审核任务、达人回填内容链接等;
店铺支撑子域:商家店铺入驻、平台审核店铺、商家绑定店铺、店铺转移等;
......
在划分出子域后,我们需要为领域建模。
领域建模是通过将业务抽象为聚合、实体、聚合根、值对象模型的方式,封装和承载全部的业务逻辑,保持业务的高内聚和低耦合。
聚合:负责封装业务逻辑,内聚决策命令和领域事件,容纳实体、聚合根、值对象。
聚合根:也是一种实体,是聚合的根节点,如订单;
实体:聚合的主干,具有唯一标识和生命周期,如订单Item;
值对象:实体的附加业务概念,用于描述实体所包含的业务信息,如订单收件地址。
70%的场景下,一个聚合内都只有一个实体,那就是聚合根。
在技术实现上,一个聚合就是一个包,里面存放领域服务、工厂、资源库、聚合根、实体、值对象。
领域层包的划分规则通常为:
----限界上下文
--domain
------聚合A
-------- (聚合根、实体、值对象、领域服务、资源库、领域事件)
------聚合B
-------- (聚合根、实体、值对象、领域服务、资源库、领域事件)
特别的,一个限界上下文可能包含多个聚合,但一个聚合只能存在于一个限界上下文。
以上包的划分只是领域层的划分,要求聚合根、实体、值对象、领域服务、资源库、领域事件等类存放在聚合包下,无论是使用DDD经典四层架构,还是六边形架构。
以店铺上下文为例,我们采样六边形架构实现,整个模块的层次、包划分如下:
com.mmg.hjs.storecontext(限界上下文)
--adapters(适配层)
----api(API接口适配)
------webmvc(前端接口,请求从网关进来)
------dubbo(内部微服务调用,实现应用层gateway包下的接口)
----persistence(持久化适配)
------dao(mybatis的Mapper类与xml文件)
------po(对应数据库表生成的类)
------StoreAssembler.class(领域实体转PO的转换器)
------StoreRepositoryImpl.class(实现领域层的资源库接口)
----cache(缓存适配)
--application(应用层)
----gateway(与其它限界上下文通信并与适配层接耦的抽象接口)
----job(可选,定时任务)
----usecase(应用服务,按用例拆分多个类,避免单个类臃肿)
----assembler(聚合根转DTO转换器)
----dto(DTO类)
----cqe(CQE模式)
------command(请求参数)
------query(查询参数)
------event(可选,事件参数,注意:非领域事件)
--domain(领域层)
----store(店铺聚合)
------model(聚合根、实体、值对象)
------event(领域事件)
------StoreDomainService.class(领域服务)
------StoreRepository.class(资源库抽象接口)
在分层架构模式中,我们需要严格遵循:上层只能依赖下层,下层不能依赖上层。
例如,在一次创建订单的操作中,用于接收前端请求参数的CreateOrderCommand属于应用层的类,虽然我们在Controller(接口层)可直接使用CreateOrderCommand,但这属于上层依赖下层,并且不是领域层,也并未暴露聚合根内部结构,因此是允许的。
如果反过来,直接将CreateOrderCommand对象传递给聚合根,那就构成下层依赖上层了,因此这是不允许的。CreateOrderCommand必须在应用层拆解为创建订单所需要的值对象,或者实体对象,再调用领域服务方法,领域服务方法调用订单工厂创建订单,最后才交给资源库持久化订单聚合根。
在领域层里面,更准确的说是在聚合包内,存储的是聚合下的聚合根、实体、值对象、资源库、领域服务、聚合根工厂类,而由于资源库的实现需要依赖orm框架或其它框架实现持久化聚合根、事件的发布需要依赖MQ实现等,所以资源库定义成接口由上层实现,事件发布也定义为接口由上层实现。
对于资源库与事件发布者,由于领域服务需要依赖资源库获取和保存聚合根,也依赖事件发布者发布事件,这种情况下我们可以使用Spring框架的自动注入,但应该使用构造函数注入,而不是在字段上加注解的方式注入,避免注入资源库、事件发布者为NULL的情况,且不应该添加Spring框架的注解(尽量不耦合)。
应用服务、领域服务、聚合根、资源库的职责
在实现DDD的过程中,我们需要严格遵守代码规范才能保持代码的整洁,否则随着需求的迭代,项目很容易就失去DDD该有的模样,变得即不DDD也不MVC。
在DDD中,Repository(资源库)是聚合根的容器,与DAO扮演相同角色,但它只提供持久化聚合根的操作(新增或更新),以及提供根据ID获取聚合根的查询操作。在所有的领域对象中,只有聚合根才拥有Repository,因为Repository不同于DAO,它所扮演的角色只是向领域模型提供聚合根。
资源库(Repository) 的职责是提供聚合根或者持久化聚合根,除此之外应「尽可能」的没有其它行为,否则聚合根就会严重退化成DAO。
public interface Repository<DO, KEY> {void save(DO obj);DO findById(KEY id);void deleteById(KEY id);
}
聚合根与领域服务(DomainService) 负则封装实现业务逻辑,应用服务(ApplicationService) 不处理业务逻辑,而只是对领域服务/聚合根方法调用的封装。
正常情况下,处理一次业务请求将经过:
应用服务->领域服务->通过资源库获取聚合根->通过资源库持久化聚合根->发布领域事件
但也允许:
应用服务->通过资源库获取聚合根->通过资源库持久化聚合根->发布领域事件
对于不能直接通过聚合根完成的业务操作就需要通过领域服务。
但必须遵守原则:
聚合根不能直接操作其它聚合根,聚合根与聚合根之间只能通过聚合根ID引用;
同限界上下文内的聚合之间的领域服务可直接调用;
两个限界上下文的交互必须通过应用服务层抽离接口->适配层适配。
聚合根工厂负责创建聚合根,但并非必须的,可以将聚合根的创建写到聚合根下并改为静态方法,非常复杂的创建过程才建议写工厂类。
以修改用户信息为例,可在应用服务通过资源库获取用户聚合根,再调用用户聚合根的修改用户信息方法,最后通过资源库持久化用户聚合根。
public class UserModifyInfoUseCase{/*** 更新用户基本信息** @param command* @param token*/@Transactional(rollbackFor = Throwable.class, isolation = Isolation.READ_COMMITTED)public void updateUserInfo(ModifyUserInfoCommand command, Long loginUserId) {// 获取聚合根Account account = findByAccountId(loginUserId);// 调用业务方法account.modifyAccountInfo(AccountInfoValobj.builder().nickname(command.getNickname()).avatarUrl(command.getAvatarUrl()).country(command.getCountry()).province(command.getProvince()).city(command.getCity()).gender(Sex.valueBy(command.getGender())).build());// 通过资源库持久化repository.save(account);// 更新缓存accountCache.cache(loginUserId, getUserById(account.getId()));}}
这里用户聚合根能到看到自己的信息,用户自己修改自己的信息可直接通过聚合根完成,因此这种场景下我们不需要领域服务。
复杂场景如用户绑定手机号码就不能直接在领域服务中完成。
绑定手机号码一般流程为:获取短信验证码、校验短信验证码、校验手机号码是否已经绑定了别的账号。
其中获取短信验证码与校验短信验证码应放在应用服务完成,而校验手机号码是否已经绑定了别的账号就需要由领域服务完成,因为聚合根无法完成这个判断, 聚合根看不到别的账号,聚合根不能拥有资源库,且应用服务不能处理业务逻辑。
聚合根
public class Account extends BaseAggregate<AccountEvent>{// .....private String phone;public void bindMobilePhone(String phoneNumber) {if (!StringUtils.isEmpty(this.phone)) {throw new AccountParamException("已经绑定过手机号码了,如需更新可走更换手机号码流程");}this.phone = phoneNumber;}}
领域服务
@Service
public class AccountDomainService {private AccountRepository repository;public AccountDomainService(AccountRepository repository) {this.repository = repository;}public void bindMobilePhone(Long userId, String phone) {Account account = repository.findById(userId);if (account == null) {throw new AccountNotFoundException(userId);}// 号码被其它账户绑定了boolean exist = repository.findByPhone(phone) != null;if (exist) {throw new AccountBindPhoneException(phone);}account.bindMobilePhone(phone);repository.save(account);}}
应用服务
@Service
public class UserBindPhoneUseCase {/*** 绑定手机号码-发送验证码** @param command* @param token*/public void bindMobilePhoneSendVerifyCode(VerifyCodeSendCommand command, Long loginUserId) {// 生成验证码String verifyCode = ValidCodeUtils.generateNumberValidCode(4);// 缓存验证码verifyCodeCache.save(command.getPhone(),verifyCode,timeout);// 调用消息服务发送验证码messageClientGateway.sendSmsVerifyCode(command.getPhone(), verifyCode);}/*** 绑定手机号码-提交绑定** @param command* @param token*/public void bindMobilePhone(BindPhoneCommand command, Long userId) {// 校验验证码String verifyCode = verifyCodeCache.get(command.getPhone());if (!command.getVerifyCode().equalsIgnoreCase(verifyCode)) {throw new VerifyPhoneCodeApplicationException();}// 通过领域服务绑定手机号码accountDomainService.bindMobilePhone(userId, command.getPhone());// 更新账号缓存accountCache.cache(userId, getUserById(userId));}
}
接口层
@RestController
@RequestMapping("account/bindMobilePhone")
public class UserBindPhoneController {@Resourceprivate UserBindPhoneUseCase useCase;@ApiOperation("绑定手机号-获取验证码")@GetMapping("/verifyCode")public Response<Void> bindMobilePhone(@RequestParam("phone") String phone) {Long userId = WebUtils.getLoginUserId();useCase.bindMobilePhoneSendVerifyCode(phone, userId);return Response.success();}@ApiOperation("绑定手机号-提交绑定")@PostMapping("/submit")public Response<Void> bindMobilePhone(@RequestBody @Validated BindPhoneCommand command) {Long userId = WebUtils.getLoginUserId();useCase.bindMobilePhone(command, userId);return Response.success();}}CQE模式
CQE即Command、Query、Event。接收前端创建订单请求使用Command,接收前端分页查询请求使用Query,消费事件(非领域事件)则使用Event。
除Event外,所有写请求都应该使用Command接收参数,而所有查询都应该使用Query接收参数,只在参数只有一个ID的查询情况下,可省略Query。
在查询分离情况下,Query是可直接传递到DAO的(接口层->应用层->DAO)。因此使用Query封装查询条件能够提高方法的复用,当添加查询条件时,无需给方法加多一个参数。
CQRS模式
CQRS(Command Query Resposibility Segregation),即命令查询职责分离模式。软件模型中存在读模型和写模型之分,以我们写业务代码的经验也知道,一次请求,要么是作为一个“命令”执行一次操作,要么作为一个”查询“向调用方返回数据,两者不可能共存。CQRS是将“命令”和“查询”分别使用不同的对象模型来表示。
CQRS的读操作放在应用层。
共享存储-共享模型-CQRS
共享存储指同一个表结构存储数据,共享模型指使用聚合根从数据库读取数据。
例如查询订单详情,订单的聚合根为Order。
// 订单聚合根
public class Order extends BaseAggregate {
}
在应用层OrderDetailsUseCase通过OrderRepository查询订单聚合根,再调用装配器将聚合根转为读模型。
public class OrderDetailsUseCase {public OrderDto byId(String id) {Order order = orderRepository.byId(id);return orderDaoAssembler.toDto(order);}
}
OrderDaoAssembler方法是将Order转为读模型实体,也就是将DO转为DTO。
注意:读操作和写操作不要写在同一个应用服务中,避免耦合,且应用服务应按用例拆分多个类(不需要很细),避免应用服务越写越臃肿。
共享存储-读写分离模型-CQRS
共享存储-读写分离模型指读写还是操作同一张表,只是写模型与读模型不同,写通过聚合根操作,而读模型绕过聚合根、Repository,直接操作数据库,此时的读模型就是用于装载从数据库查询的数据,并且不需要再作转换就可以响应给调用方,这里的读模型就是DTO。
对于单个聚合根内的查询,使用「共享存储-读写分离模型」模型可以应付复杂的查询场景,并且可以提升性能。
对于需要跨多个聚合根的查询,「共享存储-共享模型」无法实现此需求场景,而分别查询多个聚合根后,再合并查询结果不仅是将原本简单的事情变复杂,还大大影响性能,因此更有必要采用「共享存储-读写分离模型」。
对于查询订单详情希望带上商品信息,如果商品与订单在同一个服务,并且同一个数据库,那么便可以使用join多表查询。
共享存储-读写分离模型-CQRS实战举例:
接口层
@RequestMapping("/order")
@RestController
public class OrderQueryController {@GetMapping("/query")public Response<PageInfo<OrderQueryDto>> queryOrder(OrderQuery query) {return Response.success(orderQueryUseCase.queryOrder(query,WebUtils.getLoginUserId()));}}
应用层
@Service
public class OrderQueryUseCase implements Cqrs {public PageInfo<OrderQueryDto> queryOrder(OrderQuery query, Long loginUserId) {Long merchantId = merchantGateway.getMerchantId(loginUserId);IPage<OrderQueryDto> orderPage = new Page<>(query.getPage(), query.getPageSize());List<OrderQueryDto> orders = orderMapper.selectOrderBy(merchantId,query,orderPage);PageInfo<OrderQueryDto> pageInfo = new PageInfo<>(page, pageSize);pageInfo.setTotalCount((int) orderPage.getTotal());pageInfo.setList(orders);return pageInfo;}
}
读写分离存储-读写分离模型
即读与写操作不同数据库。例如,对于查询订单详情希望带上商品信息,如果商品是一个微服务、订单是一个微服务,并且两个微服务使用不同的数据库,如果要提升性能,就需要通过额外的数据同步服务,将订单与商品查询结果合并后存入一个新的表(分离存储)或者是存储到NoSQL数据库。数据同步可通过底层数据库Binlog+Kafka消费实现,还有一种是通过消费领域事件实现,但影响应用性能。
提示:对于复杂的报表统计,建议通过Binlog+Kafka同步到一张大表,为不与业务耦合,应独立为一个数据服务。
领域事件的发布
在DDD中有一个原则,一个业务用例对应一个事务,一个事务对应一个聚合根,即在一次事务中只能对一个聚合根操作。
但在实际应用中,一个业务用例往往需要修改多个聚合根,而不同的聚合根可能在不同的限界上下文中,引入领域事件即不破坏DDD的一个事务只修改一个聚合根的原则,也能实现限界上下文之间的解耦。
在DDD中,领域层是业务逻辑的具体实现,所有以解决问题子域的业务代码都高度内聚在限界上下文中、高度内聚在聚合中,即聚合根、实体以及领域服务内。
对于领域事件发布,我们的实现是在聚合根中临时保存,最后在领域服务/应用服务发布,领域层抽象事件发布接口,由适配器层实现,并注入到领域服务/应用服务。
一个原因是领域层不应该依赖其它框架的Api,另一个原因则与领域事件是由聚合根/领域服务创建有关。
那为什么领域事件由聚合根/领域服务创建,而不是在应用层创建?
发布领域事件当然是在领域层发出,可以是聚合根发出,也可以在领域服务发出,业务在聚合下高度内聚,什么时候该发出什么事件也只有聚合内最清楚,应用服务不过是封装业务实现的步骤。
由于业务逻辑最核心的实现是聚合根内,而聚合根是一个实体,不能说每次构造聚合根都传入一个事件发布者,那从资源库获取聚合根时又由谁传入事件发布者?
所以推荐的做法是在聚合根下临时存储聚合根发出的事件,在领域服务中、在调用资源库持久化聚合根之后再发布领域事件。当然,在不使用领域服务的情况下,则由应用层在调用资源库持久化聚合根之后再发布领域事件。
应用服务一个业务用例只是对应领域服务方法的一层很薄的封装,即不会在一个应用服务方法中调用两个领域服务方法。这实际上也是我们要注意,如果出现这种情况,说明领域服务方法封装的不够好。所以领域事件由领域服务发布是允许的,但事件发布者必须抽象为接口,与资源库一样在领域服务的构建方法传入。
关于我们为什么先通过Spring框架发布事件再在订阅者中实现将事件发布到MQ。
一个事件可能当前限界上下文内也需要消费,即可能有多个限界上下文需要消费,一个事件对应多个消费者。
如订单限界上下文内订单聚合产生的创建订单事件,订单限界上下文内需要消费订单创建事件,用于构造消息通知,然后给消息通知队列写入消息;同时,其它限界上下文也需要消费订单创建事件。因此,一个领域事件我们可能需要发布到多个消息队列中。
先通过Spring框架发布事件再在订阅者中实现将事件发布到MQ其实是借助Spring框架实现责任链模式。这当然不是必须的,也算不上是规范。
但不管如何,不要直接在领域服务/应用服务中调用MQ的API直接发布事件,发布事件到MQ应在适配层实现。并且封装事件发布者的好处在于,当需要确保消息至少投递一次时,这些逻辑不需要写在应用服务中。
最令人头疼的代码
在实战DDD的过程中,我们编写最多的代码无疑就是DO(聚合根)转DTO(读模型)以及DO转PO(映射到数据库表)和PO转DO的转换器代码。百分之八十的BUG都来自这些整齐划一的属性拷贝代码,容易漏字段。
那为什么需要这么多层转换呢,直接将聚合根响应给请求、直接持久化聚合根不行吗?
首先,在DDD中我们必须先获取到聚合根再通过聚合根完成业务逻辑,最终通过资源库持久化聚合根。
为什么需要将DO转PO,这是必须要做的事情吗?
如果我们选择关系型数据库持久化聚合根,那么就可能需要将聚合根拆分存储到多个表,并且对于枚举类型我们也需要转成数值类型再存储。基于这些场景就需要将聚合根转为PO再调用对应表的DAO存储到数据库中。
为什么需要将DO转DTO?
除了我们必须要遵守不暴露聚合根内部结构给外部之外,前端需要的数据也是不一样的,比如我们需要将枚举类型字段拆成值和名称两个字段,以及需要屏蔽一些字段。
为了不暴露聚合根内部结构,聚合根应只暴露GET方法,用于外部获取字段值,同时使用Builder模式提供builder方法给资源库(使用装配器)将PO转为聚合根。对于实体也可以这样做,而值对象只提供所有参数的构造方法和GET方法。当然了,使用哪种做法都没有错。
对于通用的转换操作我们为每个聚合根提供一个实现将DO(聚合根)转为DTO的装配器(转换器)、以及一个实现PO和DO相互转换的装配器(转换器)。
基于这种实现,笔者也寻找过能够解决这些繁琐操作提升工作效率的方法,我们试过用mapstruct框架,但mapstruct也只适用于简单的聚合根,对于复杂内部结构的聚合根映射也需要写一堆注解,工作量没有减少反而增加了问题排查的难度。使用Spring提供的属性拷贝工作类也是一样的,无法解决问题。
优化聚合根的持久化性能
对于使用关系型数据库持久化聚合根的场景,在“只能通过Repository的save方法持久化聚合根”这个约束下,save方法在性能上是有非常大的损耗的,因为更新一个聚合根需要同时更新聚合根下的实体。为了降低性能影响,可在更新之前对比一下内存中的快照,只对有更新的实体执行更新操作,笔者单独写了一篇文章介绍如何实现:《DDD资源库Repository的性能优化》。
如今分布式数据库已经成熟,不建议在新项目中引入分库分表ORM框架以及分布式事务框架,更不建议使用分库分表,这些应该交由底层数据库完成,或增加一层代理完成。
总结
因为DDD缺少权威性的实践指导和代码约束,我们只能是通过实践慢慢积累经验。个人的理解也并非完全正确的,对于限界上下文的划分,我们只是凭经验划分,但又缺少经验,新业务也处于不断摸索状态,现在的限界上下文划分、建模不代表将来不会推倒重来。
参考文献:
领域驱动实战思考(三):DDD的分段式协作设计
领域驱动设计(DDD)在美团点评业务系统的实践
领域驱动设计在爱奇艺打赏业务的实践
《领域驱动设计(Thoughtworks洞见)》

[Java艺术] 微信号:javaskill
深耕后端架构、探索底层实现原理,关注Java艺术,我们在架构师道路上一起成长!
![设计模式 | 四、代理模式(静态代理、JDK动态代理、Cglib动态代理、手写动态代理核心部分)[ProxyPattern]](https://img-blog.csdnimg.cn/20190901180203403.png)