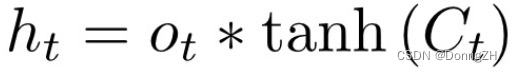(一)、什么是循环神经网络LSTM?
LSTM指的是长短期记忆网络(Long Short Term Memory),它是循环神经网络中最知名和成功的扩展。由于循环神经网络有梯度消失和梯度爆炸的问题,学习能力有限,在实际任务中的效果很难达到预期。为了增强循环神经网络的学习能力,缓解网络的梯度消失等问题,LSTM神经网络便横空出世了。LSTM可以对有价值的信息进行长期记忆,不仅减小循环神经网络的学习难度,并且由于其增加了长时记忆,在一定程度上也缓解了梯度消失的问题。(注:梯度爆炸的问题用一般的梯度裁剪方法就可以解决)。
(二)、LSTM实现长短期记忆的原理是什么?

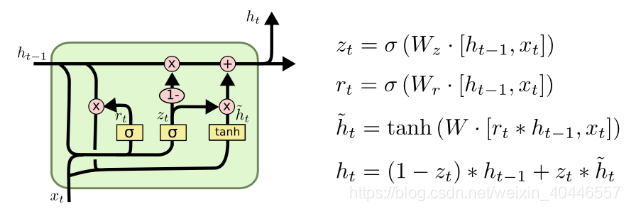
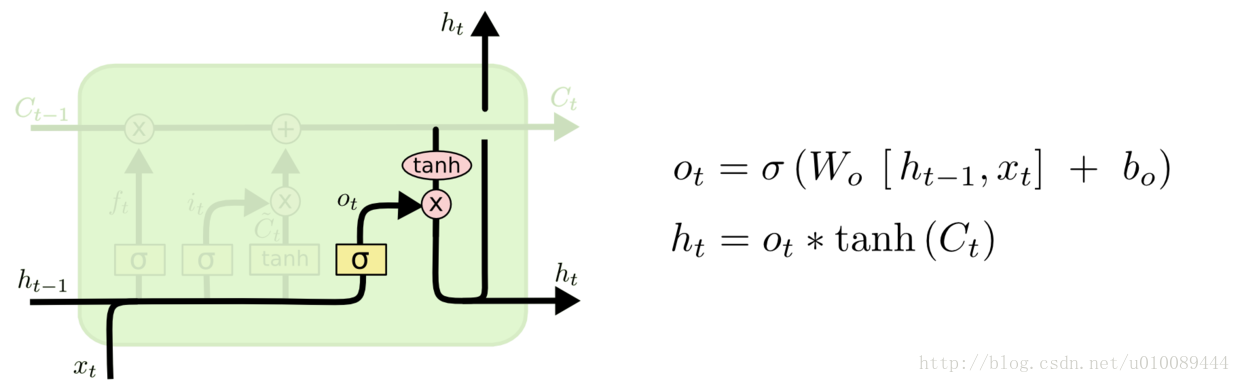
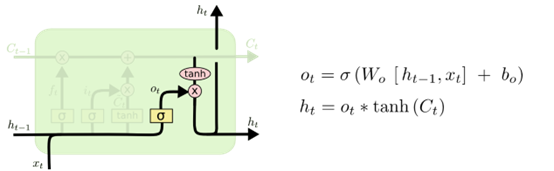
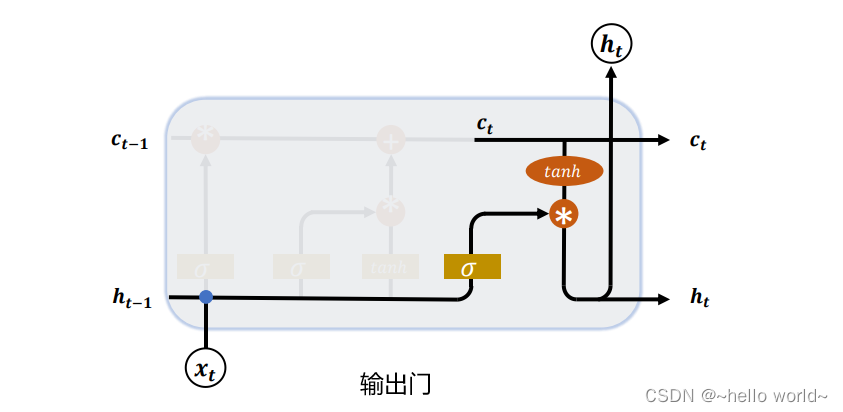
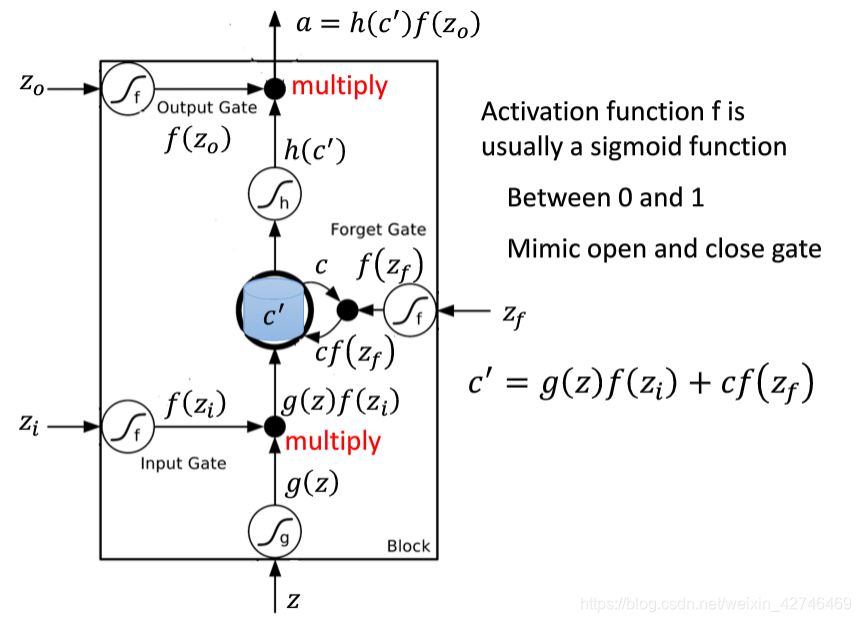
与传统的循环神经网络相比,LSTM在 h t − 1 h_{t-1} ht−1, x t x_t xt的基础上加了一个cell state(即长时记忆状态 c t − 1 c_{t-1} ct−1)来计算 h t h_t ht,并且对网络模型内部进行了更加精心的设计,加入了遗忘门 f t f_t ft、输入门 i t i_t it、输出门 o t o_t ot三个门神经元以及一个内部记忆神经元 c ~ t \tilde{c}_t c~t(上图2.1中的LSTM网络模型内部黄色的 σ \sigma σ从左到右分别指的是 f t f_t ft、 i t i_t it、 o t o_t ot,黄色的 tanh \tanh tanh则指的是 c ~ t \tilde{c}_t c~t)。遗忘门神经元 f t f_t ft控制前一步记忆单元中信息有多大程度上被遗忘掉;输入门神经元 i t i_t it控制当前记忆中的信息以多大程度更新到记忆单元中;输出门神经元 o t o_t ot控制当前的hidden state(即短时记忆单元)的输出有多大程度取决于当前的长时记忆单元。在一个训练好的网络中,当输入的序列没有重要信息时,LSTM遗忘门的值接近于1,输入门的值接近于0,此时过去的信息将会保留,从而实现了长时记忆的功能;当输入的序列中出现了重要信息时,LSTM应当将其存入记忆中,此时其输入门的值会接近于1;当输入的序列中出现了重要信息,且该信息意味着之前的记忆不再重要时,则输入门的值会接近于1,而遗忘门的值会接近于0,这样旧的记忆就会遗忘,新的重要信息被记忆。经过这样的设计,整个网络更容易学习到序列之间的长期依赖。
(三)、LSTM的原理公式是什么?
经典的LSTM中,第t步的更新计算公式如下( ⊙ \odot ⊙表示元素点乘):
{ 输 入 : x i n p u t = c o n c a t [ h t − 1 , x t ] 遗 忘 门 神 经 元 : f t = σ ( x i n p u t W f + b f ) 遗 忘 后 的 长 时 记 忆 : c t − 1 ′ = f t ⊙ c t − 1 记 忆 门 神 经 元 : c ~ t = tanh ( x i n p u t W c + b c ) 输 入 门 神 经 元 : i t = σ ( x i n p u t W i + b i ) 输 入 后 的 记 忆 : c ~ t ′ = i t ⊙ c t ~ t 时 刻 的 长 时 记 忆 : c t = c t − 1 ′ + c ~ t ′ 输 出 门 神 经 元 : o t = σ ( x i n p u t W o + b o ) t 时 刻 的 短 期 记 忆 : h t = o t ⊙ tanh ( c t ) \begin{cases} 输入:x_{input}=concat[h_{t-1},x_t]\\ 遗忘门神经元:f_t=\sigma(x_{input}W_f+b_f) \\ 遗忘后的长时记忆:c'_{t-1}=f_t\odot c_{t-1} \\ 记忆门神经元:\tilde{c}_t=\tanh(x_{input}W_c+b_c)\\ 输入门神经元:i_t=\sigma(x_{input}W_i+b_i)\\ 输入后的记忆:{\tilde{c}'_t}=i_t\odot \tilde{c_t}\\ t时刻的长时记忆:c_t=c'_{t-1}+{\tilde{c}'_t}\\ 输出门神经元:o_t=\sigma(x_{input}W_o+b_o)\\ t时刻的短期记忆:h_t=o_t\odot \tanh{(c_t)}\\ \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧输入:xinput=concat[ht−1,xt]遗忘门神经元:ft=σ(xinputWf+bf)遗忘后的长时记忆:ct−1′=ft⊙ct−1记忆门神经元:c~t=tanh(xinputWc+bc)输入门神经元:it=σ(xinputWi+bi)输入后的记忆:c~t′=it⊙ct~t时刻的长时记忆:ct=ct−1′+c~t′输出门神经元:ot=σ(xinputWo+bo)t时刻的短期记忆:ht=ot⊙tanh(ct)
其中输入 x i n p u t x_{input} xinput是通过对上一时刻 t − 1 t-1 t−1的短期记忆状态 h t − 1 h_{t-1} ht−1以及当前时刻 t t t的字(词)向量输入 x t x_t xt进行特征维度的 c o n c a t concat concat所获得的。 σ \sigma σ指的是 s i g m o i d sigmoid sigmoid函数,遗忘门、输入门以及输出门神经元的输出结果是向量,由于三个门神经元均采用 s i g m o i d sigmoid sigmoid作为激活函数,所以输出向量的每个元素均在0~1之间,用于控制各维度流过阀门的信息量;记忆门神经元的输出结果仍为向量,且与遗忘门、输入门以及输出门神经元的输出向量维度等同,由于记忆门神经元使用的激活函数是 tanh \tanh tanh,所以其输出向量的每个元素均在-1~1之间。 W f W_f Wf, b f b_f bf, W i W_i Wi, b i b_i bi, W c W_c Wc, b c b_c bc, W o W_o Wo, b o b_o bo是各个门神经元的参数,是在训练过程中需要学习得到的。与传统的循环神经网络所不同的是,LSTM循环神经网络新增了长时记忆单元,从上一个长时记忆单元的状态 c t − 1 c_{t-1} ct−1到当前的长时记忆单元 c t c_{t} ct不仅取决于激活函数 tanh \tanh tanh计算得到的状态,而且还由输入门和遗忘门神经元来共同控制。
(四)、LSTM为什么选择 s i g m o i d sigmoid sigmoid作为遗忘门、输入门以及输出门神经元的激活函数,又为什么选择 tanh \tanh tanh作为记忆门神经元的激活函数?
我们可以注意到,无论是 s i g m o i d sigmoid sigmoid还是 tanh \tanh tanh,它们均属于饱和函数,也就是说当输入达到一定值的情况下,输出就不会明显变化了。比如,当输入小于一定值时, s i g m o i d sigmoid sigmoid输出几乎接近于0, tanh \tanh tanh输出几乎接近于-1;当输入大于一定值时, s i g m o i d sigmoid sigmoid, tanh \tanh tanh输出均接近于1。
(1). 如果使用非饱和的激活函数,例如 r e l u relu relu,我们很难实现门控效果。 s o g m o i d sogmoid sogmoid的函数输出在0~1之间,且输入较大或较小时,其输出会非常接近1或0,从而保证该门是开或关。故选择 s i g m o i d sigmoid sigmoid作为遗忘门、输入门以及输出门神经元的激活函数最合适不过。
(2). tanh \tanh tanh函数的输出在-1~1之间,并且中心为0,这与大多数场景下特征分布是0中心吻合,并且, tanh \tanh tanh在输入为0附近的时相比 s i g m o i d sigmoid sigmoid函数有更大的梯度。通常使模型收敛更快。
(五)、常问问题一:LSTM有几个输入几个输出?
三个输入:序列中的字(词)向量输入 x t x_t xt、短时记忆状态输入 h t − 1 h_{t-1} ht−1以及长时记忆状态输入 c t − 1 c_{t-1} ct−1。
两个输出:短时记忆状态输出 h t h_t ht和长时记忆状态输出 c t c_t ct。
(六)、常问问题二:LSTM有几个神经元,分别使用什么激活函数?
四个神经元:遗忘门、输入门、输出门以及记忆门神经元,其中遗忘门、输入门以及输出门神经元使用 s i g m o i d sigmoid sigmoid作为激活函数,实现门控效果;记忆门神经元使用 tanh \tanh tanh作为激活函数,来吻合0中心特征分布,并且 tanh \tanh tanh函数在0中心有较大梯度,提高模型收敛速度。
(七)、如何构建双向LSTM?

(1). 初始化两个新的LSTM,一个LSTM将序列正序输入,另一个LSTM将序列反序输入,然后将对应字(词)向量的LSTM输出的结果进行concat,并将concat的结果作为该字(词)向量的新特征向量。
注:这个concat的输入,既可以说是LSTM网络结果输出,也可以说是LSTM短时记忆状态输出。若考虑长时记忆状态的concat,则应是两个序列的最后一个长时记忆状态进行concat,详细见(3)总结
(2). E x a m p l e Example Example:假如有一个序列为"大梦想家",我们正序输入即将"大",“梦”,“想”,“家"的字向量按照顺序依次输入到第一个LSTM神经网络,与此同时将"家”,“想”,“梦”,"大"的字向量按照顺序依次输入到第二个LSTM神经网络,然后将得到的"大"对应的第一个LSTM向量输出与"大"对应的第二个LSTM向量的输出进行concat。
(3). 总结
1.在上面的 E x a m p l e Example Example中,我们不难看出,对于正序输入的"大"字向量来说,其输出并没有其他字向量的信息,而对于反序输入的"大"字向量来说,其输出包含了"家",“想”,"梦"所有在反序中"大"字向量前面的字向量信息。将这两个"大"所得到的LSTM网络输出进行concat,于是"大"字向量获得了concat后的新特征向量,该特征向量拥有了序列的全局信息,即拥有全局视野。
2.对于双向LSTM来说,若我们考虑将第一个LSTM在正序序列输入的情况下,所输出的最后一个长时记忆状态,即对应的"家"的输出状态与第二个LSTM在反序序列输入的情况下,所输出的最后一个长时记忆状态,即对应的"大"的输出状态进行concat,这样所得到的hidden_state以及cell_state将具有更持久的记忆,即记忆能力更强。
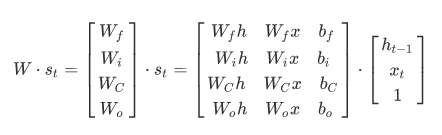

![人人都能用Python写出LSTM-RNN的代码![你的神经网络学习最佳起步]](https://img-blog.csdnimg.cn/img_convert/cfca0b70e6d14e6cd1e0ae5c87f3b8aa.png)