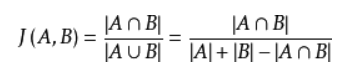一、余弦相似度简介
余弦相似度(又称为余弦相似性):是通过测量两个向量的夹角的余弦值来度量它们之间的相似性。余弦值接近1,夹角趋于0,表明两个向量越相似;余弦值接近于0,夹角趋于90度,表明两个向量越不相似。
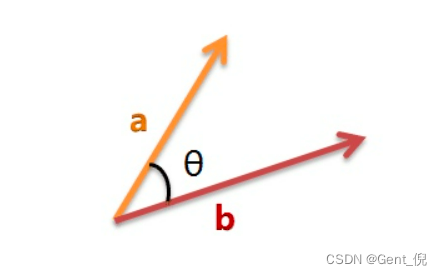
那么如何来计算余弦相似性呢?
余弦定理是三角形中三边长度与一个角的余弦值(cos)的数学式。
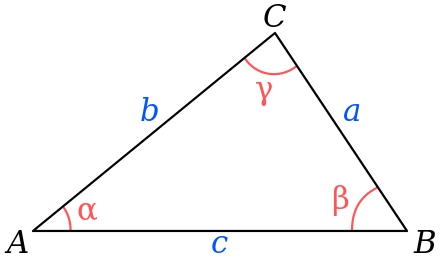
余弦定理的表达式如下:
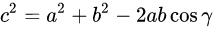
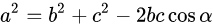
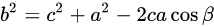
勾股定理则是余弦定理的特殊情况,当角为直角时,即:时,公式简化为
根据余弦定理表达式,余弦的计算公式如下:
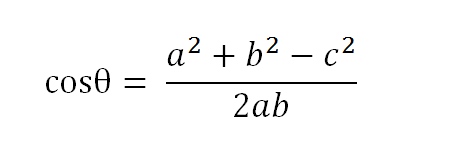
而a,b,c 是三个边的长度。假定a向量是[x1, y1],b向量是[x2, y2],那么根据向量求长度公式(向量的长度又叫向量的模,使用双竖线来包裹向量表示向量的长度)
,即
;同理,
,即
,
而
将此时的a,b,c带入余弦公式,即可推导出
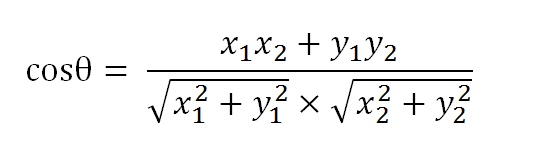
即 ,其中分子为向量a与向量b的点乘,分母为二者各自的L2相乘,即将所有维度值的平方相加后开方。

二、文本相似度计算思路
句子A:我想养一头奶牛,这样就可以每天喝新鲜的牛奶。
句子B:我想每天喝新鲜的牛奶,所以打算养一头奶牛。
1. 分词
A分词结果:[我, 想, 养, 一头, 奶牛, 这样, 就, 可以, 每天, 喝, 新鲜, 的, 牛奶]
B分词结果:[我, 想, 每天, 喝, 新鲜, 的, 牛奶, 所以, 打算, 养, 一头, 奶牛]
2. 取并集(将句子A、B分词后的结果取并集)
[我, 想, 养, 一头, 奶牛, 这样, 就, 可以, 每天, 喝, 新鲜, 的, 牛奶, 所以, 打算]
3. 写出词频向量
根据句子A、B的分词结果去计算词频向量,其中词频向量的长度为第二步中的并集,而每一位代表单词的出现次数。
句子A:(1,1,1,1,1,1,1,1,1,1,1,1,1,0,0)
句子B:(1,1,1,1,1,0,0,0,1,1,1,1,1,1,1)
到这里,问题就变成了如何计算这两个向量的相似程度。
4. 计算余弦相似度
将词频向量代入余弦相似度公式:
计算结果中夹角的余弦值为0.80064,非常接近于1,所以,上面的句子A和句子B是基本相似的。
三、代码实现
使用HanLP需要先导入maven依赖:
<!-- https://mvnrepository.com/artifact/com.hankcs/hanlp --><dependency><groupId>com.hankcs</groupId><artifactId>hanlp</artifactId><version>portable-1.7.2</version></dependency>Java代码如下:
package com.scb.dss.udf;import com.hankcs.hanlp.HanLP;import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;public class CosineSimilarity {/*** 使用余弦相似度算法计算文本相似性** @param sentence1* @param sentence2* @return*/public static double getSimilarity(String sentence1, String sentence2) {System.out.println("Step1. 分词");List<String> sent1Words = getSplitWords(sentence1);System.out.println(sentence1 + "\n分词结果:" + sent1Words);List<String> sent2Words = getSplitWords(sentence2);System.out.println(sentence2 + "\n分词结果:" + sent2Words);System.out.println("Step2. 取并集");List<String> allWords = mergeList(sent1Words, sent2Words);System.out.println(allWords);int[] statistic1 = statistic(allWords, sent1Words);int[] statistic2 = statistic(allWords, sent2Words);// 向量A与向量B的点乘double dividend = 0;// 向量A所有维度值的平方相加double divisor1 = 0;// 向量B所有维度值的平方相加double divisor2 = 0;// 余弦相似度 算法for (int i = 0; i < statistic1.length; i++) {dividend += statistic1[i] * statistic2[i];divisor1 += Math.pow(statistic1[i], 2);divisor2 += Math.pow(statistic2[i], 2);}System.out.println("Step3. 计算词频向量");for(int i : statistic1) {System.out.print(i+",");}System.out.println();for(int i : statistic2) {System.out.print(i+",");}System.out.println();// 向量A与向量B的点乘 / (向量A所有维度值的平方相加后开方 * 向量B所有维度值的平方相加后开方)return dividend / (Math.sqrt(divisor1) * Math.sqrt(divisor2));}// 3. 计算词频private static int[] statistic(List<String> allWords, List<String> sentWords) {int[] result = new int[allWords.size()];for (int i = 0; i < allWords.size(); i++) {// 返回指定集合中指定对象出现的次数result[i] = Collections.frequency(sentWords, allWords.get(i));}return result;}// 2. 取并集private static List<String> mergeList(List<String> list1, List<String> list2) {List<String> result = new ArrayList<>();result.addAll(list1);result.addAll(list2);return result.stream().distinct().collect(Collectors.toList());}// 1. 分词private static List<String> getSplitWords(String sentence) {// 标点符号会被单独分为一个Term,去除之return HanLP.segment(sentence).stream().map(a -> a.word).filter(s -> !"`~!@#$^&*()=|{}':;',\\[\\].<>/?~!@#¥……&*()——|{}【】‘;:”“'。,、? ".contains(s)).collect(Collectors.toList());}
}
测试代码:
package com.scb.dss.udf;import org.junit.Test;public class CosineSimilarityTest {@Testpublic void testGetSimilarity() throws Exception {String text3 = "我想养一头奶牛,这样就可以每天喝新鲜的牛奶。";String text4 = "我想每天喝新鲜的牛奶,所以打算养一头奶牛。";System.out.println("文本相似度为:"+CosineSimilarity.getSimilarity(text3, text4));}
}
四、参考
相似度计算方法(三) 余弦相似度_潘永青的博客-CSDN博客_余弦相似度
余弦相似度Cosine Similarity相关计算公式 - 蝈蝈俊 - 博客园