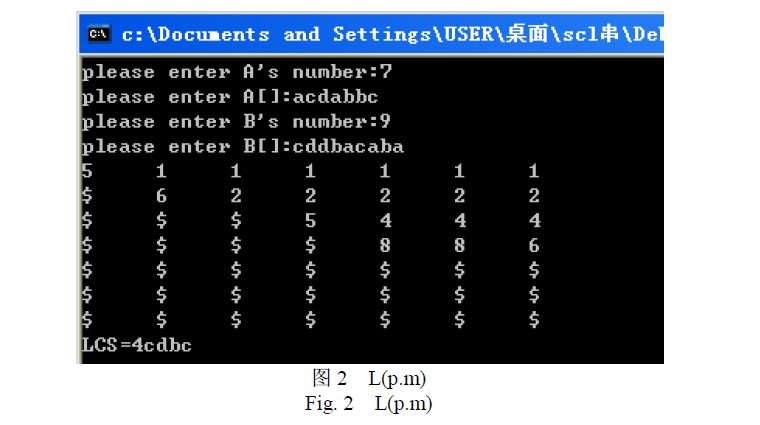
解决Longest Common Subsequence(LCS)问题最常用的算法是Dyanmic programing,细节可以参考Ch15.4 of Introduction of Algorithm(2ED), MIT press, p 350。这个算法最大的问题是他的空间复杂度是O(m*n)。这样,当两个序列达到上万个节点时,内存消耗就成为了大问题。
1975年D. S. Hirschberg提出了另外一种算法,他的时间复杂度略高于Dynamic programing,但是,空间复杂度只有O(m+n),可以很好的解决大序列的LCS问题。参见D. S. Hirschberg. A linear space algorithm for computing maximal common subsequences. Comm. A.C.M. 18(6) p341-343, 1975.
下面给出这个算法的C++和Python实现。
原算法中使用的序列下表从一开始,在此根据编程语言的特点做了优化,改成了从0开始,所以和原始算法看上去有差异。
C++(VS2005下编译通过)
 #include < vector > #include < algorithm > using namespace std;vector < int > findRow0( int m, int n, vector < TCHAR > A, vector < TCHAR > B)
#include < vector > #include < algorithm > using namespace std;vector < int > findRow0( int m, int n, vector < TCHAR > A, vector < TCHAR > B)
 ... {
... { vector<int> K0; vector<int> K1(n+1, 0); //# in PDF, this lien is 1:n, It may be wrong for( int i = 0; i<m; i++)
vector<int> K0; vector<int> K1(n+1, 0); //# in PDF, this lien is 1:n, It may be wrong for( int i = 0; i<m; i++)
 ...{ K0 = K1; for(int j = 0; j < n; j++) ...{ if (A[i] == B[j]) K1[j+1] = K0[j] +1; else K1[j+1] = max ( K1[j], K0[j+1]);
...{ K0 = K1; for(int j = 0; j < n; j++) ...{ if (A[i] == B[j]) K1[j+1] = K0[j] +1; else K1[j+1] = max ( K1[j], K0[j+1]); } } vector<int> LL = K1; return LL;
} } vector<int> LL = K1; return LL; } vector < TCHAR > H_LCS0( int m, int n, vector < TCHAR > A, vector < TCHAR > B) ... { vector<TCHAR> C; if (n == 0) C.clear(); else if (m == 1) ...{ vector<TCHAR>::iterator result = find( B.begin( ), B.end( ), A[0] ); if ( result != B.end( ) ) //if A[0] in B: C = vector<TCHAR>(1, A[0]); else C.clear(); } else ...{ int i = m / 2; //#step3 vector <TCHAR> A1i(A.begin(),A.begin()+i); vector<int> L1 = findRow0(i, n, A1i, B); vector <TCHAR> Anip1(A.rbegin(), A.rend()-i); vector< TCHAR > Bn1(B.rbegin(), B.rend()); vector<int> L2 = findRow0(m-i, n, Anip1, Bn1); //#step4 int M = 0; int k = 0; for ( int j = 0; j<=n; j++) ...{ int tmp = L1[j] + L2[n-j]; if (tmp > M) ...{ M = tmp; k = j; } } //#step 5 vector< TCHAR > A0i(A.begin(), A.begin()+i); vector< TCHAR > B0k(B.begin(), B.begin()+k); vector< TCHAR > C1 = H_LCS0( i, k, A0i, B0k); vector< TCHAR > Aim(A.begin()+i, A.end()); vector< TCHAR > Bkn(B.begin()+k, B.end()); vector< TCHAR > C2 = H_LCS0( m-i, n-k, Aim, Bkn); //#step 6 C = C1; C.insert(C.end(), C2.begin(), C2.end()); } return C;} int _tmain( int argc, _TCHAR * argv[]) ... { if(argc < 3) _tprintf(_T("At least need two string ")); else ...{ int m = _tcslen(argv[1]); vector <TCHAR> A(argv[1], argv[1] + m); int n = _tcslen(argv[2]); vector <TCHAR> B(argv[2], argv[2] + n); vector <TCHAR> C = H_LCS0(m, n, A, B); C.push_back(0); _tprintf(&C[0]); } return 0;}
} vector < TCHAR > H_LCS0( int m, int n, vector < TCHAR > A, vector < TCHAR > B) ... { vector<TCHAR> C; if (n == 0) C.clear(); else if (m == 1) ...{ vector<TCHAR>::iterator result = find( B.begin( ), B.end( ), A[0] ); if ( result != B.end( ) ) //if A[0] in B: C = vector<TCHAR>(1, A[0]); else C.clear(); } else ...{ int i = m / 2; //#step3 vector <TCHAR> A1i(A.begin(),A.begin()+i); vector<int> L1 = findRow0(i, n, A1i, B); vector <TCHAR> Anip1(A.rbegin(), A.rend()-i); vector< TCHAR > Bn1(B.rbegin(), B.rend()); vector<int> L2 = findRow0(m-i, n, Anip1, Bn1); //#step4 int M = 0; int k = 0; for ( int j = 0; j<=n; j++) ...{ int tmp = L1[j] + L2[n-j]; if (tmp > M) ...{ M = tmp; k = j; } } //#step 5 vector< TCHAR > A0i(A.begin(), A.begin()+i); vector< TCHAR > B0k(B.begin(), B.begin()+k); vector< TCHAR > C1 = H_LCS0( i, k, A0i, B0k); vector< TCHAR > Aim(A.begin()+i, A.end()); vector< TCHAR > Bkn(B.begin()+k, B.end()); vector< TCHAR > C2 = H_LCS0( m-i, n-k, Aim, Bkn); //#step 6 C = C1; C.insert(C.end(), C2.begin(), C2.end()); } return C;} int _tmain( int argc, _TCHAR * argv[]) ... { if(argc < 3) _tprintf(_T("At least need two string ")); else ...{ int m = _tcslen(argv[1]); vector <TCHAR> A(argv[1], argv[1] + m); int n = _tcslen(argv[2]); vector <TCHAR> B(argv[2], argv[2] + n); vector <TCHAR> C = H_LCS0(m, n, A, B); C.push_back(0); _tprintf(&C[0]); } return 0;} Python 代码(在python2.5下测试)
def findRow0(m, n, A, B): print " findRow0 " , m , n , '' .join(A), '' .join(B) K0 = [] K1 = [0] * (n + 1 ) # in PDF, this lien is 1:n, It may be wrong for i in range(0,m): K0 = K1[:] for j in range(0,n): # print i, j if A[i] == B[j]: K1[j + 1 ] = K0[j] + 1 else : K1[j + 1 ] = max ( K1[j], K0[j + 1 ]) LL = K1 print ' LL = ' , LL return LL def H_LCS0(m, n, A, B): print " H_LCS0 " , m, n, '' .join(A), '' .join(B) if n == 0: C = [] elif m == 1 : if A[0] in B: C = [A[0]] else : C = [] else : i = m / 2 # step3 L1 = [] A1i = A[0:i] L1 = findRow0(i, n, A1i, B) Anip1 = A[i:] Anip1.reverse() Bn1 = B[:] Bn1.reverse() L2 = findRow0(m - i, n, Anip1, Bn1) # step4 M = 0 k = 0 for j in range(0, n + 1 ): tmp = L1[j] + L2[n - j] if tmp > M: M = tmp k = j # step 5 print ' i= ' , i, ' k= ' , k, ' m= ' , m, ' n= ' , n C1 = H_LCS0( i, k, A[0:i], B[0:k]) C2 = H_LCS0( m - i, n - k, A[i:], B[k:]) # step 6 C = C1 + C2 print " C1= " , '' .join(C1), " C2= " , '' .join(C2), print " C = " , '' .join(C) return CA = " ACGTACGTACGT " B = " AGTACCTACCGT " C = H_LCS0(len(A), len(B), list(A), list(B)) print " final result " , '' .join(C) 代码还有很多可以优化的地方。
另外,发现还有一些类似的算法,特别python的difflib采用的算法,找出的不一定是理论上的最长子序列。特别是在序列中相同元素重复出现次数比较高的时候特别明显。猜测,可能和他采用了对元素进行hash造成的。另外,他的文档中也说明:This does not yield minimal edit sequences, but does tend to yield matches that ``look right'' to people. (4.4 difflib -- Helpers for computing deltas of Python Library Reference for python 2.5)
具体算法可以参见
Pattern Matching: The Gestalt Approach
Discussion of a similar algorithm by John W. Ratcliff and D. E. Metzener. This was published in Dr. Dobb's Journal in July, 1988.
Discussion of a similar algorithm by John W. Ratcliff and D. E. Metzener. This was published in Dr. Dobb's Journal in July, 1988.