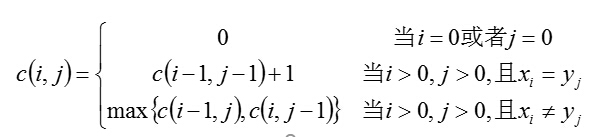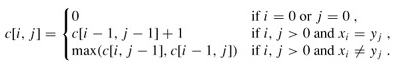有哪些算法用于比较两个字符串的相似程度
终于知道怎么判断字符串相似度了
一直不理解,为什么要计算两个字符串的相似度呢rfid。什么叫做两个字符串的相似度。经常看别人的博客,碰到比较牛的人,然后就翻了翻,终于找到了比较全面的答案和为什么要计算字符串相似度的解释。
因为搜索引擎要把通过爬虫抓取的页面给记录下来,那么除了通过记录url是否被访问过之外,还可以这样,比较两个页面的相似度,因为不同的url中可能记录着相同的内容,这样,就不必再次记录到搜索引擎的存储空间中去了。
还有,大家毕业的时候都写过论文吧,我们论文的查重系统相信也会采用计算两个字符串相似度这个概念。以下叙述摘自编程之美一书:许多程序会大量使用字符串。对于不同的字符串,我们希望能够有办法判断其相似程序。
我们定义一套操作方法来把两个不相同的字符串变得相同,具体的操作方法为:1.修改一个字符(如把“a”替换为“b”);2.增加一个字符(如把“abdd”变为“aebdd”);3.删除一个字符(如把“travelling”变为“traveling”);比如,对于“abcdefg”和“abcdef”两个字符串来说,我们认为可以通过增加/减少一个“g”的方式来达到目的。
上面的两种方案,都仅需要一次。把这个操作所需要的次数定义为两个字符串的距离,而相似度等于“距离+1”的倒数。也就是说,“abcdefg”和“abcdef”的距离为1,相似度为1/2=0.5。
给定任意两个字符串,你是否能写出一个算法来计算它们的相似度呢?原文的分析与解法不难看出,两个字符串的距离肯定不超过它们的长度之和(我们可以通过删除操作把两个串都转化为空串)。
虽然这个结论对结果没有帮助,但至少可以知道,任意两个字符串的距离都是有限的。我们还是就住集中考虑如何才能把这个问题转化成规模较小的同样的子问题。
如果有两个串A=xabcdae和B=xfdfa,它们的第一个字符是相同的,只要计算A[2,...,7]=abcdae和B[2,...,5]=fdfa的距离就可以了。
但是如果两个串的第一个字符不相同,那么可以进行如下的操作(lenA和lenB分别是A串和B串的长度)。1.删除A串的第一个字符,然后计算A[2,...,lenA]和B[1,...,lenB]的距离。
2.删除B串的第一个字符,然后计算A[1,...,lenA]和B[2,...,lenB]的距离。
3.修改A串的第一个字符为B串的第一个字符,然后计算A[2,...,lenA]和B[2,...,lenB]的距离。
4.修改B串的第一个字符为A串的第一个字符,然后计算A[2,...,lenA]和B[2,...,lenB]的距离。
5.增加B串的第一个字符到A串的第一个字符之前,然后计算A[1,...,lenA]和B[2,...,lenB]的距离。
6.增加A串的第一个字符到B串的第一个字符之前,然后计算A[2,...,lenA]和B[1,...,lenB]的距离。在这个题目中,我们并不在乎两个字符串变得相等之后的字符串是怎样的。
所以,可以将上面的6个操作合并为:1.一步操作之后,再将A[2,...,lenA]和B[1,...,lenB]变成相字符串。
2.一步操作之后,再将A[2,...,lenA]和B[2,...,lenB]变成相字符串。3.一步操作之后,再将A[1,...,lenA]和B[2,...,lenB]变成相字符串。
通过以上1和6,2和5,3和4的结合操作,最后两个字符串每个对应的字符会相同,但是这三种操作产生的最终的两个字符串是不一样的。我们不知道通过上述的三种结合那种使用的操作次数是最少的。
所以我们要比较操作次数来求得最小值。
比较两句话的意思很相似,用什么算法?
。
答案是正确的.先说你写的句子有两个问题,首先你把这句话一口气读下来会发现不是一句完整的话,所有内容都是when引导的时间状语从句的从句部分,没有主句.第二take……seriously是一个固定表达,你把它变成beseriously,be后面加一个副词不合语法,意思也讲不通.所以改的时候一定要完整的保留take……seriously成分,主动变成被动就可以了.答案中know通常的意思是‘知道’,但还有‘得知’‘获知’的意思,这里可以翻译成‘发现’:“当女孩说他曾见到一只袋鼠时,她发现她没被当回事”,意思和原句相同.如果把knew换成found就容易理解了.。
相似度分析包含哪些算法
SIM=StructuralSIMilarity(结构相似性),这是一种用来评测图像质量的一种方法。
由于人类视觉很容易从图像中抽取出结构信息,因此计算两幅图像结构信息的相似性就可以用来作为一种检测图像质量的好坏.首先结构信息不应该受到照明的影响,。
如何计算网站网页相似度
。
据统计,网页上的大部分相同的页面占29%,而主体内容完全相同的占22%,这些重复网页有的是没有一点改动的拷贝,有的在内容上稍作修改,比如同一文章的不同版本,一个新一点,一个老一点,有的则仅仅是网页的格式不同(如HTML,Postscript),文献[ModelsandAlgorithmsforDuplicateDocumentDetection1999年]将内容重复归结为以下四个类型:1.如果2篇文档内容和格式上毫无差别,则这种重复叫做full-layoutduplicate。
2.如果2篇文档内容相同,但是格式不同,则叫做full-contentduplicates3.如果2篇文档有部分重要的内容相同,并且格式相同,则称为partial-layoutduplicates4.如果2篇文档有部分重要的内容相同,但是格式不同,则称为partial-contentduplicates网页去重的任务就是去掉网页中主题内容重复的部分。
它和网页净化(noisereduction),反作弊(antispam)是搜索引擎的3大门神去重在我看来起码有四好处:减少存储;增强检索效率;增强用户的体验;死链的另一种解决方案。
目前从百度的搜索结果来看,去重工作做的不是很完善,一方面可能是技术难度(precision和recall都超过90%还是很难的);另一方面可能是重复的界定,比如转载算不算重复?
所以另一项附属的工作是对个人可写的页面(PWP)进行特殊的处理,那么随之而来的工作就是识别PWP页面。^_^这里就不扯远呢。问题如何解决?
网页的deduplication,我们的算法应该是从最简单的开始,最朴素的算法当然是对文档进行两两比较,如果A和B比较,如果相似就去掉其中一个然而这个朴素的算法,存在几个没有解决的问题: 0.要解决问题是什么?
full-layout?full-content?partial-layout还是partial-content?
1.怎么度量A和B的相似程度 2.去掉A还是去掉B,如果A~B(~表相似,!~表示不相似),B~C但是A!~C,去掉B的话,C就去不掉。
另一个更深入的问题是,算法的复杂度是多少?假设文档数为n,文档平均长度为m,如果相似度计算复杂度为m的某一个复杂度函数:T=T(m),文档两两比较的复杂度是O(n^2),合起来是O(n^2*T(m)).这个复杂度是相当高的,想搜索引擎这样处理海量数据的系统,这样的复杂度是完全不能接受的,所有,另外三个问题是: 3.如何降低相似度计算的复杂化度 4.如何减少文档比较的复杂度 5.超大数据集该如何处理 第0个问题是,我们要解决的关键,不同的问题有不同的解决方法,从网页的角度来看,结构的重复并不能代表是重复,比如产品展示页面,不同的产品展示页面就有相同的文档结构。
内容来看,复制网站会拷贝其他网站的主要内容,然后加些广告或做些修改。所以,解决的问题是,partial-contentdeduplication,那么首先要抽取网页的主体内容。
算法变成: 抽取文档主体内容,两两比较内容的相似性,如果A和B相似,去掉其中一个 其次,问题2依赖于问题1的相似度度量,如果度量函数具有传递性,那么问题2就不存在了,如果没有传递性,我们的方法是什么呢?
哦,那就找一个关系,把相似关系传递开嘛,简单,聚类嘛,我们的框架可以改成: 抽取文档主体内容,两两比较内容的相似性,如果A和B相似,把他们聚类在一起,最后一个类里保留一个page最后,归纳为几个步骤第一步:识别页面的主题内容,网页净化的一部分,以后讨论第二步:计算相似度第三步:聚类算法,计算出文档那些文档是相似的,归类。
核心的问题是,“如何计算相似度?
”这里很容易想到的是 1.计算内容的编辑距离editdistance(方法很有名,但是复杂度太高) 2.把内容分成一个个的token,然后用集合的jaccard度量(好主意,但是页面内容太多,能不能减少啊?
) 好吧,但是,当然可以减少集合的个数呢,采样,抽取满足性质的token就可以啦,如满足modm=0的token,比如有实词?比如stopwords。
真是绝妙的注意.在把所有的idea放一起前,突然灵光一现,啊哈, 3.计算内容的信息指纹,参考google研究员吴军的数学之美系列。
把他们放在一起:第一步:识别页面的主题内容,网页净化的一部分,以后讨论第二步:提取页面的特征。
将文章切分为重合和或不重合的几个结合,hashout第三步:用相似度度量来计算集合的相似性,包括用信息指纹,Jaccard集合相似度量,randomprojection等。
第四步:聚类算法,计算出文档那些文档是相似的,归类。
方法分类:按照利用的信息,现有方法可以分为以下三类1.只是利用内容计算相似2.结合内容和链接关系计算相似3.结合内容,链接关系以及url文字进行相似计算一般为内容重复的去重,实际上有些网页是按照特征提取的粒度现有方法可以分为以下三类1.按照单词这个级别的粒度进行特征提取.2.按照SHINGLE这个级别的粒度进行特征提取.SHNGLE是若干个连续出现的单词,级别处于文档和单词之间,比文档粒度小,比单词粒度大.3.按照整个文档这个级别的粒度进行特征提取算法-具体见真知1.I-Match2.Shingling3.LocalitySensitiveHashing.(SimHash)4.SpotSigs5.Combined。
怎么计算两组数据的相似程度?
楼上比较方差(∑σ^2)做法不见得全面。所谓“数据相似”,应是“两组数据在某个有序排列之下具有同等变化规律”的含义。
比如,两组数据是两天的温度变化曲线、试验参数序列...所以,按照以上假设,那么需要采用“统计回归处理”方法,看二者回归后函数参量的相似性。
其他数据处理手段还有:拟合(具体有很多种,应用于不同领域)、(等距序列)谱分析法...建议搜索,关键词:回归处理拟合算法傅立叶分析。
有没有这样一个字符串相似性比较算法
可以这么定义,但是个人看不出意义所在。主要有以下问题:1.比较的通用性不够。两个字符串长度不等的时候怎么比较?
2.单一标准不符合自然语言的多义性实际生活中,“ABC”和“JFH”更相似,还是和“XYZ”更相似?
根据语境的不同,结果是不一样的,但是按照你的算法,相似度有了唯一的量化标准3.比较的方式过于简单,不能支持复杂的比较你判断两个字符串相似的标准是“对应差”中的每一个数字都小于伐值,那么假设有三个字符串,甲,乙,丙,其中甲和乙的对应差只有一个数大于伐值,为20;但是甲和丙的对应差有两个数大于伐值,分别为11和12。
那么,乙和丙比较,哪个更接近甲?
4.不符合语言使用习惯“abc”和“ABC”一般来说,在语义上是比较“接近”的,但是“abc”和“mps”这样的语义上相距较远的字符串反而有更近的“距离”在一定条件下,确实有用数字替代字符来计算相似度的情况,但是实际的方式比你这样的复杂很多,并且一般不是使用单一数字,而是向量,例如这样的方式,使用TFIDF在特定语言范围内(例如一本小说),量化不同词语之间的联系。
然而,实际中效果好的方式更为复杂。
如何使用opencv中的NCC算法实现两幅图像的相似性判断
感知哈希算法(perceptualhashalgorithm),它的作用是对每张图像生成一个“指纹”(fingerprint)字符串,然后比较不同图像的指纹。结果越接近,就说明图像越相似。
实现步骤:1.缩小尺寸:将图像缩小到8*8的尺寸,总共64个像素。
这一步的作用是去除图像的细节,只保留结构/明暗等基本信息,摒弃不同尺寸/比例带来的图像差异;2.简化色彩:将缩小后的图像,转为64级灰度,即所有像素点总共只有64种颜色;3.计算平均值:计算所有64个像素的灰度平均值;4.比较像素的灰度:将每个像素的灰度,与平均值进行比较,大于或等于平均值记为1,小于平均值记为0;5.计算哈希值:将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图像的指纹。
组合的次序并不重要,只要保证所有图像都采用同样次序就行了;6.得到指纹以后,就可以对比不同的图像,看看64位中有多少位是不一样的。
在理论上,这等同于”汉明距离”(Hammingdistance,在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数)。
如果不相同的数据位数不超过5,就说明两张图像很相似;如果大于10,就说明这是两张不同的图像。
以上内容摘自:下面是用OpenCV实现的测试代码:[cpp]viewplaincopyprint?stringstrSrcImageName="";cv::MatmatSrc,matSrc1,matSrc2;matSrc=cv::imread(strSrcImageName,CV_LOAD_IMAGE_COLOR);CV_Assert(matSrc.channels()==3);cv::resize(matSrc,matSrc1,cv::Size(357,419),0,0,cv::INTER_NEAREST);//cv::flip(matSrc1,matSrc1,1);cv::resize(matSrc,matSrc2,cv::Size(2177,3233),0,0,cv::INTER_LANCZOS4);cv::MatmatDst1,matDst2;cv::resize(matSrc1,matDst1,cv::Size(8,8),0,0,cv::INTER_CUBIC);cv::resize(matSrc2,matDst2,cv::Size(8,8),0,0,cv::INTER_CUBIC);cv::cvtColor(matDst1,matDst1,CV_BGR2GRAY);cv::cvtColor(matDst2,matDst2,CV_BGR2GRAY);intiAvg1=0,iAvg2=0;intarr1[64],arr2[64];for(inti=0;i<8;i++){uchar*data1=(i);uchar*data2=(i);inttmp=i*8;for(intj=0;j<8;j++){inttmp1=tmp+j;arr1[tmp1]=data1[j]/4*4;arr2[tmp1]=data2[j]/4*4;iAvg1+=arr1[tmp1];iAvg2+=arr2[tmp1];}}iAvg1/=64;iAvg2/=64;for(inti=0;i<64;i++){arr1[i]=(arr1[i]>=iAvg1)?1:0;arr2[i]=(arr2[i]>=iAvg2)?1:0;}intiDiffNum=0;for(inti=0;i<64;i++)if(arr1[i]!=arr2[i])++iDiffNum;cout。