背景
“人以类聚,物以群分”,在大千世界中总有那么一些人,性格爱好、行为习惯比较相近,我们就会把他们归为一类人,这就是我们人脑自动进行的一个聚类(归类)。
在数据分析中,我们也经常拿数据来进行K-Means聚类,用来进行一些分析,K-Means聚类可能大家都会,但是如何科学的决策聚类簇数,这一直是聚类的一大难题。今天就来分享一下,自己工作中在确定聚类簇数时要到的方法。
方法
可以确定聚类簇数的方法
- Adjusted Rand index 调整兰德系数
- Mutual Information based scores 互信息
- Homogeneity, completeness and V-measure 同质性、完整性、两者的调和平均
- Silhouette Coefficient 轮廓系数
- Calinski-Harabaz Index
- SSE 簇里误差平方和
自己使用的方法,手肘法则SSE 和 轮廓系数 相结合
- SSE 簇里误差平方和
SSE利用计算误方差和,来实现对不同K值的选取后,每个K值对应簇内的点到中心点的距离误差平方和,理论上SSE的值越小,代表聚类效果越好,通过数据测试,SSE的值会逐渐趋向一个最小值。
- Silhouette Coefficient 轮廓系数
好的聚类:内密外疏,同一个聚类内部的样本要足够密集,不同聚类之间样本要足够疏远。
轮廓系数计算规则:
针对样本空间中的一个特定样本,计算它与所在簇中其它样本的平均距离a,以及该样本与距离最近的另一个聚类中所有样本的平均距离b,该样本的轮廓系数为
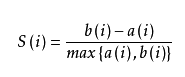
单个样本点的轮廓系数
对于其中的一个点 i 来说:
计算 a(i) = average(i向量到所有它属于的簇中其它点的距离)
计算 b(i) = min (i向量到各个非本身所在簇的所有点的平均距离)
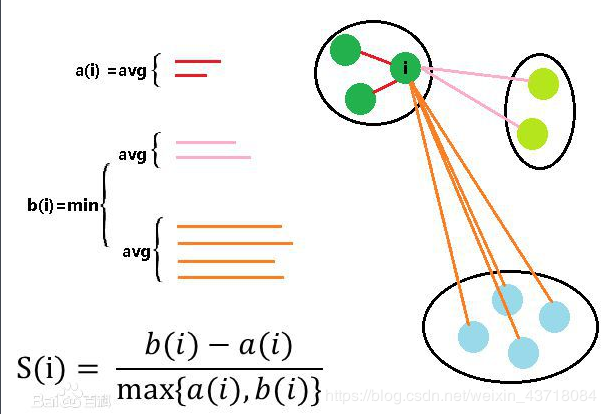
分解步骤
然后将整个样本空间中所有样本的轮廓系数取算数平均值,作为聚类划分的性能指标轮廓系数
轮廓系数的区间为:[-1, 1]。 -1代表分类效果差,1代表分类效果好。0代表聚类重叠,没有很好的划分聚类
应用、代码
以鸢尾花数据集为案例
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import sklearn.metrics as sm
import pandas as pd%matplotlib inline
import matplotlib.pyplot as plt#中文乱码的处理 显示负号
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False# 载入鸢尾花数据集
iris = datasets.load_iris()data=pd.DataFrame(iris['data'],columns=iris['feature_names'])std = StandardScaler()
data_std=std.fit_transform(data)SSE = []
k_SSE = []
#簇的数量
for n_clusters in range(1,11):cls = KMeans(n_clusters).fit(data_std)score = cls.inertia_SSE.append(score)k_SSE.append(n_clusters)silhouette_score = []
k_sil = []
#簇的数量
for n_clusters in range(2,11):cls = KMeans(n_clusters).fit(data_std)pred_y=cls.labels_#轮廓系数score =sm.silhouette_score(data_std, pred_y)silhouette_score.append(score)k_sil.append(n_clusters)fig, ax1 = plt.subplots(figsize=(10, 6))ax1.scatter(k_SSE, SSE)
ax1.plot(k_SSE, SSE)
ax1.set_xlabel("k",fontdict={'fontsize':15})
ax1.set_ylabel("SSE",fontdict={'fontsize':15})
ax1.set_xticks(range(11))
for x,y in zip(k_SSE,SSE):plt.text(x, y,x)ax2 = ax1.twinx()
ax2.scatter(k, silhouette_score,marker='^',c='red')
ax2.plot(k, silhouette_score,c='red')
ax2.set_ylabel("silhouette_score",fontdict={'fontsize':15},)
for x,y in zip(k_sil,silhouette_score):plt.text(x, y,x)plt.show()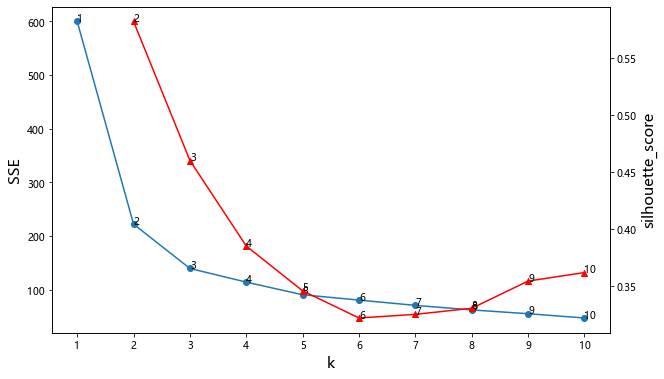
iris 聚类
结合SSE与轮廓系数,当k=3时比较适合,可以确定聚类的簇数为3
而鸢尾花数据集里面真实的分类就是3类
iris['target_names']
#array(['setosa', 'versicolor', 'virginica'], dtype='<U10')历史相关文章
- 利用熵值法确定指标权重---原理及Python实现
- 罗兰贝格图--Python等高线图(平滑处理)
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号,不定期分享干货

相关文章

【机器学习】聚类代码练习
本课程是中国大学慕课《机器学习》的“聚类”章节的课后代码。 课程地址: https://www.icourse163.org/course/WZU-1464096179 课程完整代码: https://github.com/fengdu78/WZU-machine-learning-course 代码修改并注释:黄海广,ha…

【聚类算法】10种Python聚类算法完整操作示例(建议收藏
点击上方,选择星标,每天给你送干货! 来源:海豚数据科学实验室 著作权归作者所有,本文仅作学术分享,若侵权,请联系后台删文处理 聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术&…

理论+实战,一文详解最常使用的10个聚类算法(附代码)
聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现数据中的有趣模式,例如基于其行为的客户群。有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。
相反,最好探索一系列聚类算法以及每…
基于微信小程序的家校通系统-JAVA【数据库设计、源码、开题报告】
第一章 绪 论
1.1选题背景
随着网络时代的到来,互联网的优势和普及时刻影响并改变着人们的生活方式。在信息技术迅速发展的今天,计算机技术已经遍及全球,使社会发生了巨大的变革。
为了不受时间和地点的限制,智能手机用户可以通…

python新闻文本聚类_TextCluster:短文本聚类预处理模块 Short text cluster
推荐Github上一个NLP相关的项目: RandyPen/TextCluster
项目地址,阅读原文可以直达,欢迎参与和Star:
https://github.com/RandyPen/TextCluster
这个项目的作者是AINLP交流群里的昭鸣同学,该项目 开源了一个短文本聚…

【组队学习】十一月微信图文索引
十一月微信图文索引
一、组队学习相关
周报:
Datawhale组队学习周报(第037周)Datawhale组队学习周报(第038周)Datawhale组队学习周报(第039周)Datawhale组队学习周报(第040周&…

k-means聚类算法从入门到精通
点击上方“小白学视觉”,选择加"星标"或“置顶” 重磅干货,第一时间送达 k-means算法是非监督聚类最常用的一种方法,因其算法简单和很好的适用于大样本数据,广泛应用于不同领域,本文详细总结了k-means聚类算…

LaneAF | 利用Affinity Field聚类进行车道线实例分割
点击上方“计算机视觉工坊”,选择“星标” 干货第一时间送达 论文:https://arxiv.org/abs/2103.12040 开源代码:https://github.com/sel118/LaneAF 0 动机 车道线检测对于辅助驾驶、自动驾驶至关重要。全球范围内多种多样的车道线以及复杂的道…

机器学习 --- 聚类性能评估指标
第1关:外部指标
任务描述 本关任务:填写 python 代码,完成 calc_JC 函数、calc_FM 函数和 calc_Rand 函数分别实现计算 JC系数、FM 指数 和 Rand 指数 。
相关知识 为了完成本关任务,你需要掌握:
JC 系数; FM 指数&…
如何用 DBSCAN 聚类算法做数据分析?
DBSCAN属于无监督学习算法,无监督算法的内涵是观察无标签数据集自动发现隐藏结构和层次,在无标签数据中寻找隐藏规律。
聚类模型在数据分析当中的应用:既可以作为一个单独过程,用于寻找数据内在规律,也可以作为分类等…


K-means聚类算法
实训目标 本实训项目介绍无监督学习中,使用最广泛的 K-means 聚类算法。 先修知识 本实训项目假设,你已经掌握了初步的 Python 程序设计的基础知识。学习者若有一些 numpy 的使用经验,则可更快速地通过实训。 实训知识点 欧几里得距离 估算簇…

一文详解激光点云的物体聚类
点击上方“3D视觉工坊”,选择“星标” 干货第一时间送达 文章导读 本文针对自动驾驶中三维点云的道路目标聚类进行讲解,从聚类算法的原理出发,介绍几种常用的点云障碍物聚类算法,并对比分析算法的优劣和适用场景,从工程…
![[计算机毕业设计]模糊聚类算法](https://img-blog.csdnimg.cn/632f16aceeee4be6a8443d20fb0be8d8.png)
[计算机毕业设计]模糊聚类算法
前言 📅大四是整个大学期间最忙碌的时光,一边要忙着准备考研,考公,考教资或者实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过…
51nod-1548:欧姆诺姆和糖果
1548 欧姆诺姆和糖果 题目来源: CodeForces 基准时间限制:1 秒 空间限制:131072 KB 分值: 20 难度:3级算法题 收藏 关注 一天,欧姆诺诺姆来到了朋友家里,他发现了许多糖果。有蓝色和红色两种。他知道每颗…
android自动导入包快捷键,Android studio 自动导入(全部)包 import
http://blog.csdn.net/buaaroid/article/details/44979629 1 Android studio 只有import单个包的快捷键:Alt+Enter。没有Eclipse下的快速导入包的快捷键Ctrl+Shift+O。 2 但Android studio设置里有一项Auto Import自动导入功能。设置过程如下: Android studio --> File--&…

舍友打一把游戏的时间,我实现了一个selenium自动化测试并把数据保存到MySQL
文章目录 前言最终效果开发环境selenium元素定位方法页面分析思路分析实现步骤运行结果以下是全部代码 前言
很久没有玩selenium自动化测试了,近日在学习中都是在忙于学习新的知识点,所以呢今天就来写个selenium自动化测试的案例吧。有没有人疑惑&#…

51nod P1381 硬币游戏【数学】
题目 思路
比较简单.
参考代码
#include<iostream>
#include<cstdio>
using namespace std;
int T,n;
int main()
{scanf("%d",&T);while(T--){scanf("%d",&n);printf("%d\n",2*n);}return 0;
}

51nod3061 车
题目 题目链接
解题思路
提一种不需要生成树的解法。 我们将询问挂到点上,使用启发式合并的并查集。当询问的两边合并到一起时,我们就得到了答案。 整体复杂度 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)。
代码
#include <cstdio>
#include &…

51nod 1279 扔盘子
题目链接:https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1279 题目: 有一口井,井的高度为N,每隔1个单位它的宽度有变化。现在从井口往下面扔圆盘,如果圆盘的宽度大于井在某个高度的宽度,则圆盘被卡住(恰好等于的话会下去)。 盘子有几种命运:1、掉到…