文章目录
- 前言
- 最终效果
- 开发环境
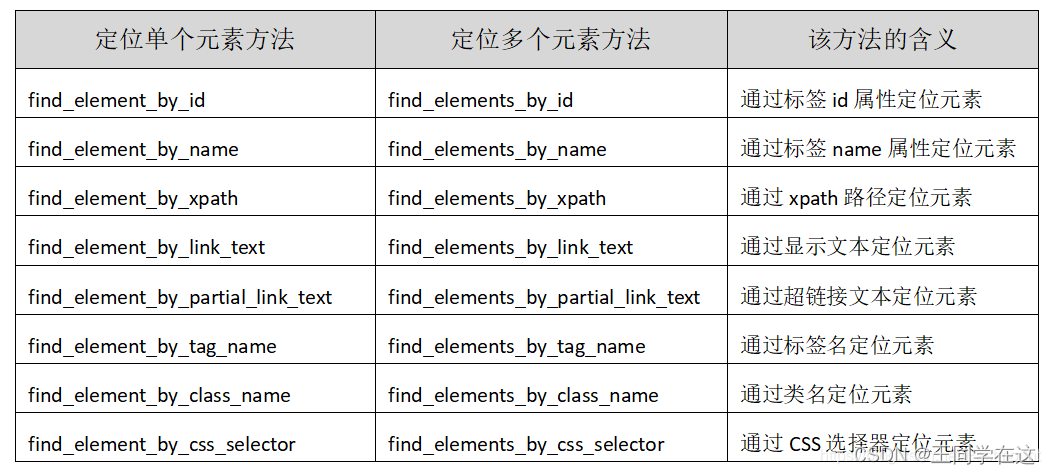
- selenium元素定位方法
- 页面分析
- 思路分析
- 实现步骤
- 运行结果
- 以下是全部代码
前言
很久没有玩selenium自动化测试了,近日在学习中都是在忙于学习新的知识点,所以呢今天就来写个selenium自动化测试的案例吧。有没有人疑惑?What is selenium,那我来告诉你吧!起码能让你了解到它是干什么的,Selenium 是一种开源工具,用于在 Web 浏览器上执行自动化测试(使用任何 Web 浏览器进行 Web 应用程序测试)。
反正就是我们躺着,让它自己动,躺好,让 selenium 满足你的要求。

那么接下来进入正题吧!
最终效果
先一览最终效果吧,数据都保存到Exel,及MySQL数据库中。
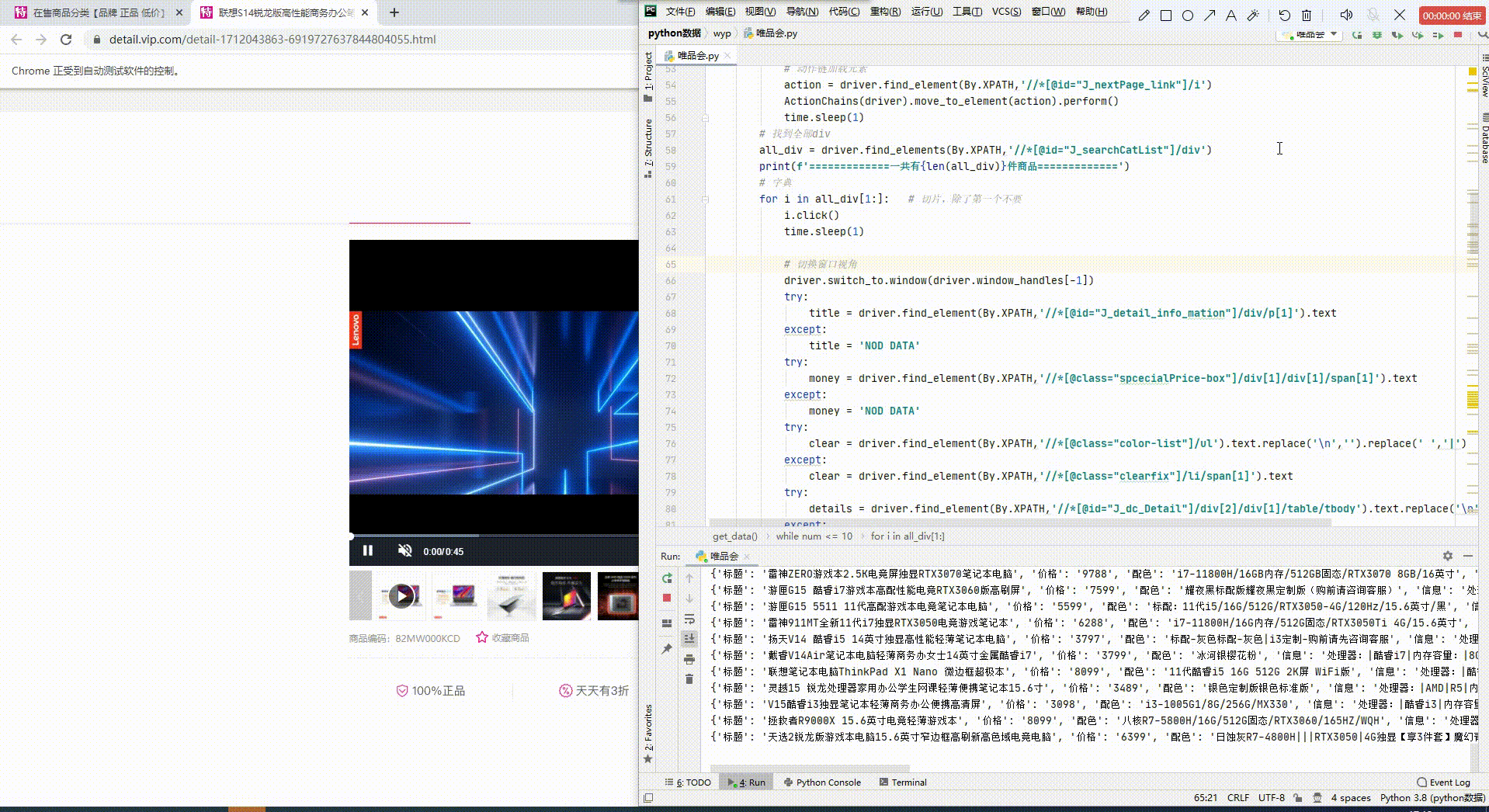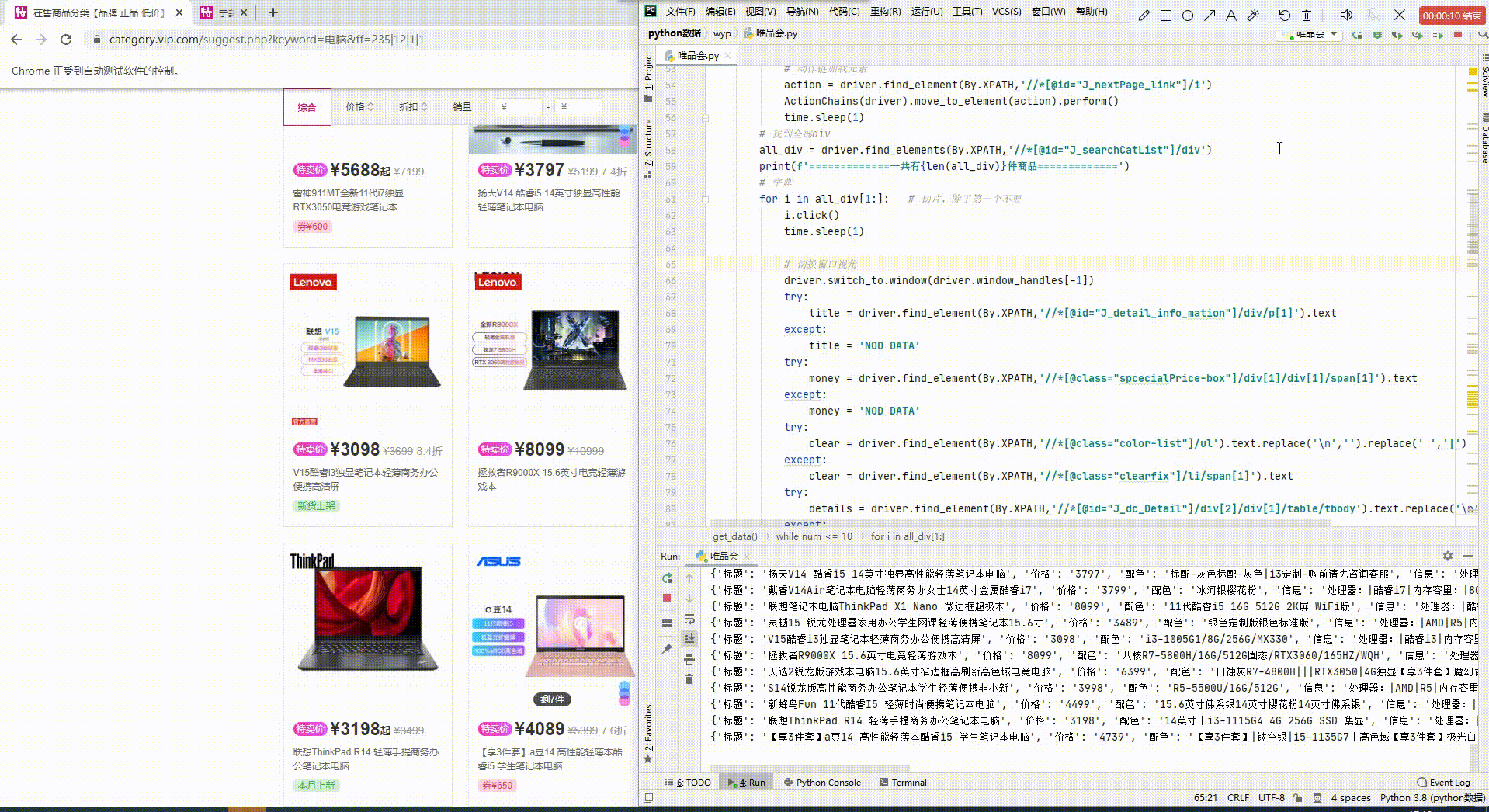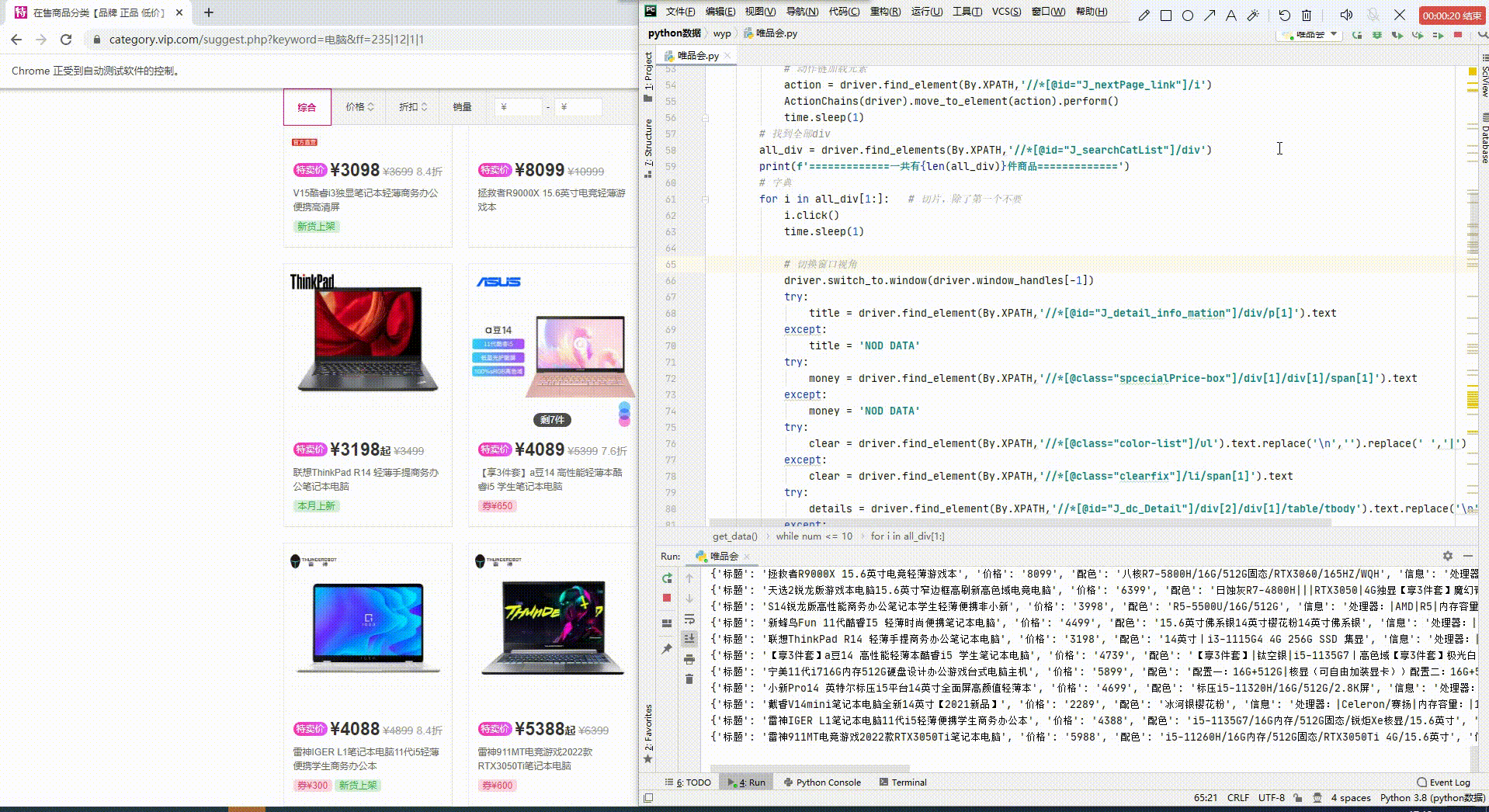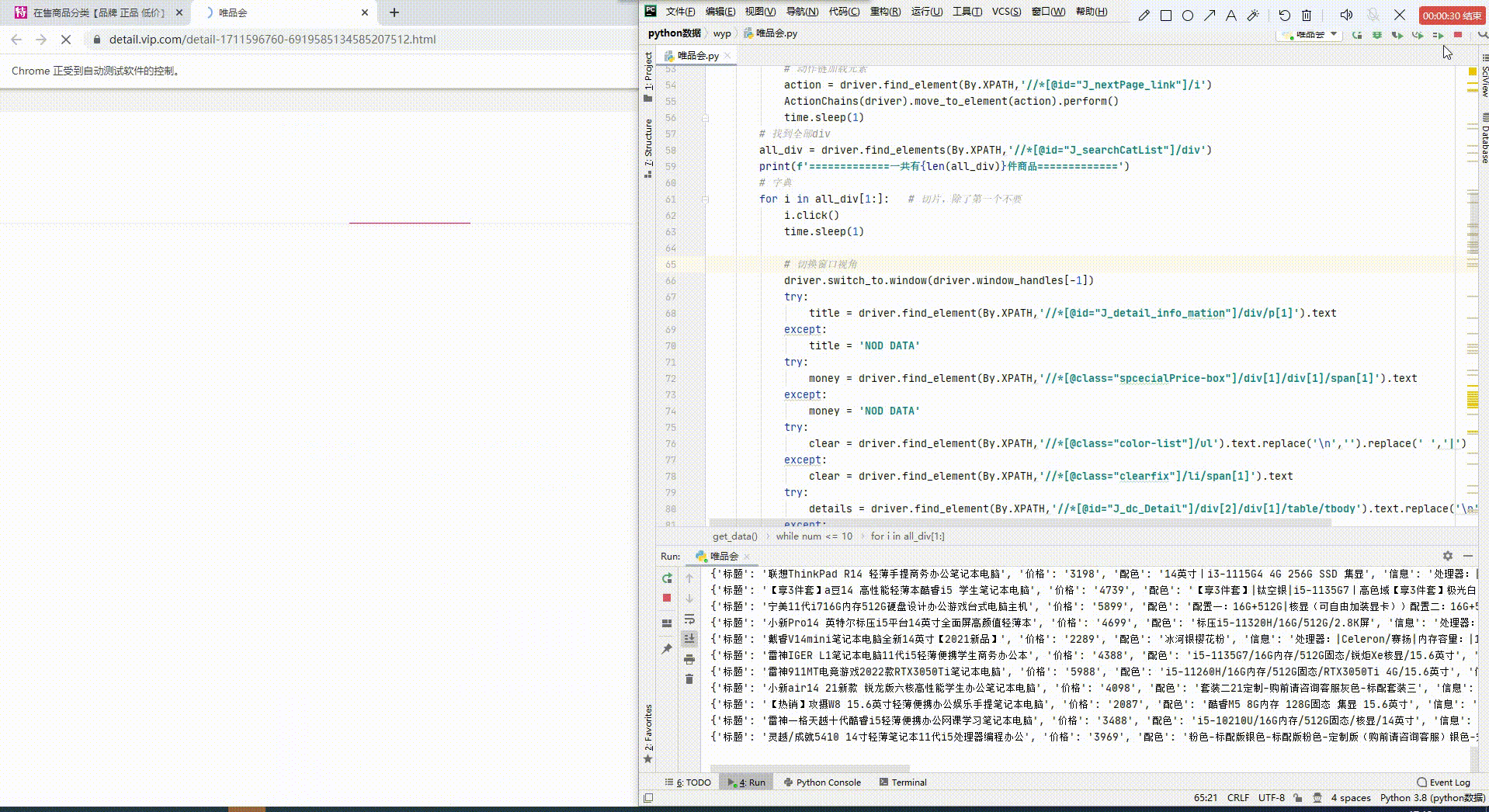


开发环境
需要配置好selenium运行环境,及安装好相关的库,这些都可在博客上查找相关教程。
python3.8
selenium模块
pymysql
selenium元素定位方法
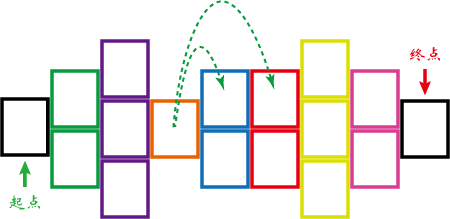
下图就是selenium提供的利用元素定位可以找到加载页面中的任何对象,类似于我们查看加载的页面,并找到我们的目标信息,以便执行其它相关操作。

知道多种元素定位能更好的帮我们找到所需要的信息。

页面分析
先是打开页面右键点击检查,或者按下F12点Elements查看网页源代码,
观察页面源码查看我们的输入框是在页面源代码里面的什么位置,(从源码中可以看出输入框的标签在body中,而前后都没有iframe),
因为如果不看的话有些网址有个子页面iframe,而页面的有些元素标签就存在子页面iframe中,
这样我们直接查找标签是找不到标签的,也就进行不了操作,需要切换到子页面iframe中才能获取到标签。这样能确保我们操作的时候不用再查找bug。

想一下如果要实现自动化的话是不是要浏览器自己打开网页然后我们通过selenium提供的元素定位方法找到输入框输入我们想要查找的商品,并点击搜索去搜索这个商品,然后搜索到了就把网页显示出来的商品信息通过selenium定位,进行其他相关操作。
那么接下来看一下思路吧!

思路分析
操作浏览器打开浏览器对象,找到输入框和点击按妞,并输入信息后点击,商品展视出来后,设置个selenium动作链运动页面到网页底部,这样是为了加载商品出来,然后用selenium标签定位的方法找到全部商品的div,设置循环每个商品div点击进入商品的详情页selenium定位我们需要的信息并提取出来。
实现步骤
1.MySQL创建数据库(后面储存数据时候需要)
create database shop charset=utf8;

2.导入相对应的库对网页发起请求,找到输入框(这里我输入框输入的商品是电脑)和点击按键,
# 输入框insert = driver.find_element(By.XPATH,'//*[@id="J-search"]/div[1]/input')insert.send_keys('电脑')time.sleep(1)
3.搜索商品出来后,设置动作链加载商品,selenium找到全部div循环点击进入商品详情页获取信息。
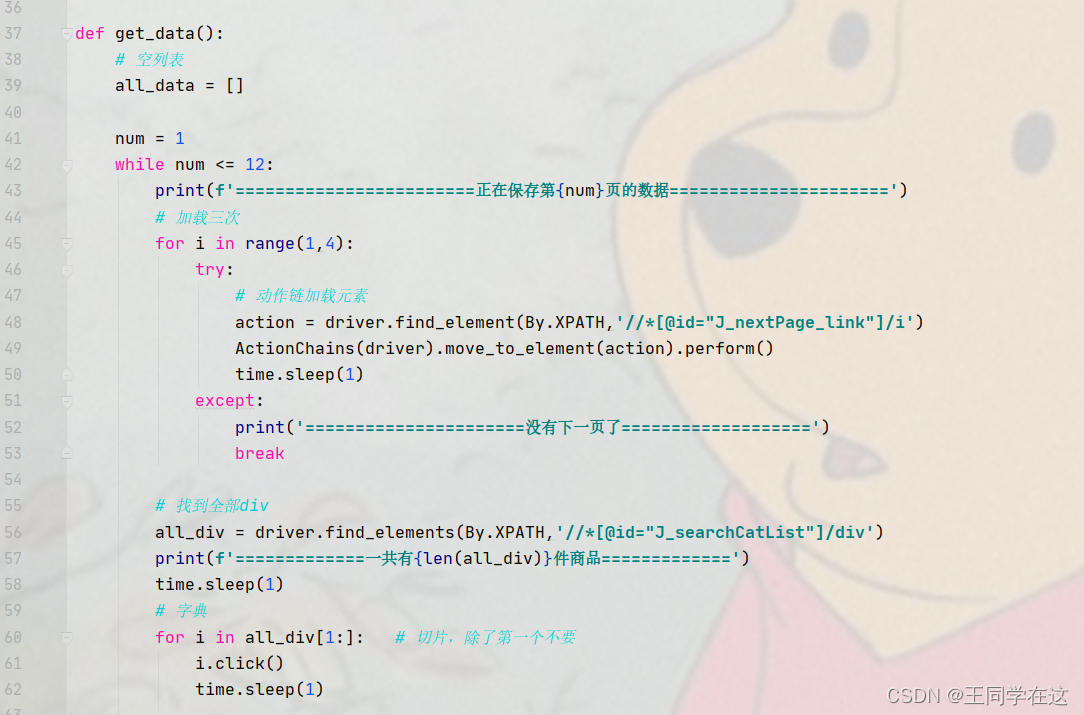
页面商品的全部div在标签section下面,但要注意的是第一个div不是商品的di,我框起来的那些才是。

因此要做个切片除了第一个div我不要,后面的全部都要。

全部商品的div有了接下来就是进入到详情页拿信息了,这些信息都存储在页面源码中。

selenium提供的定位方法提取需要信息。

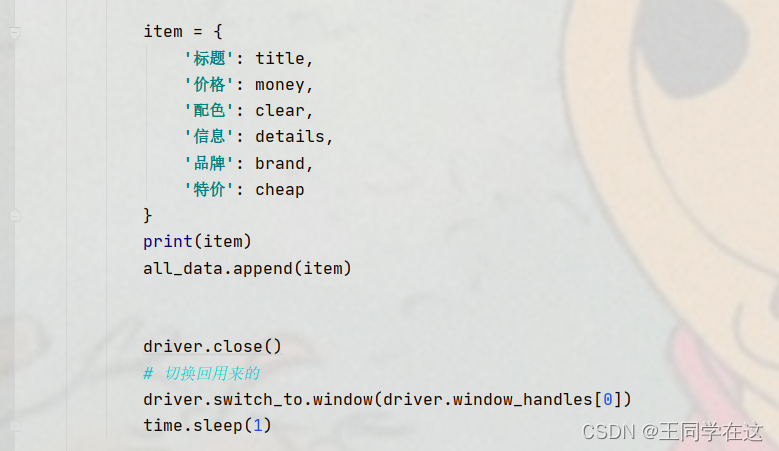
信息有了之后就构造一个字典把数据存入,再把字典添加到列表中。
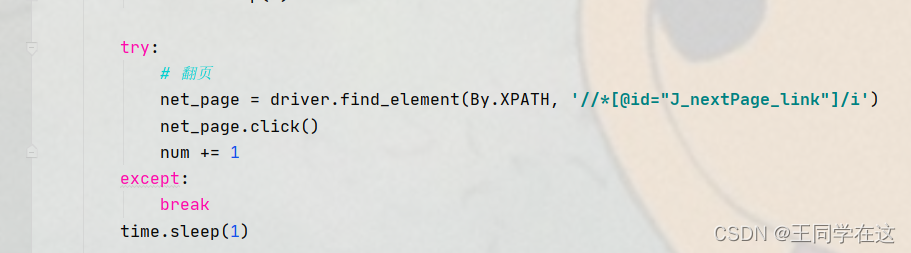
4.翻页的实现。
滑到页面底部查看下一页的标签。

selenium定位到元素标签,并点击下一页
最后return返回的是存储字典的列表。
基本的步骤都完成了接下来就是对数据的保存了
下图函数是实现对数据的保存到Exel

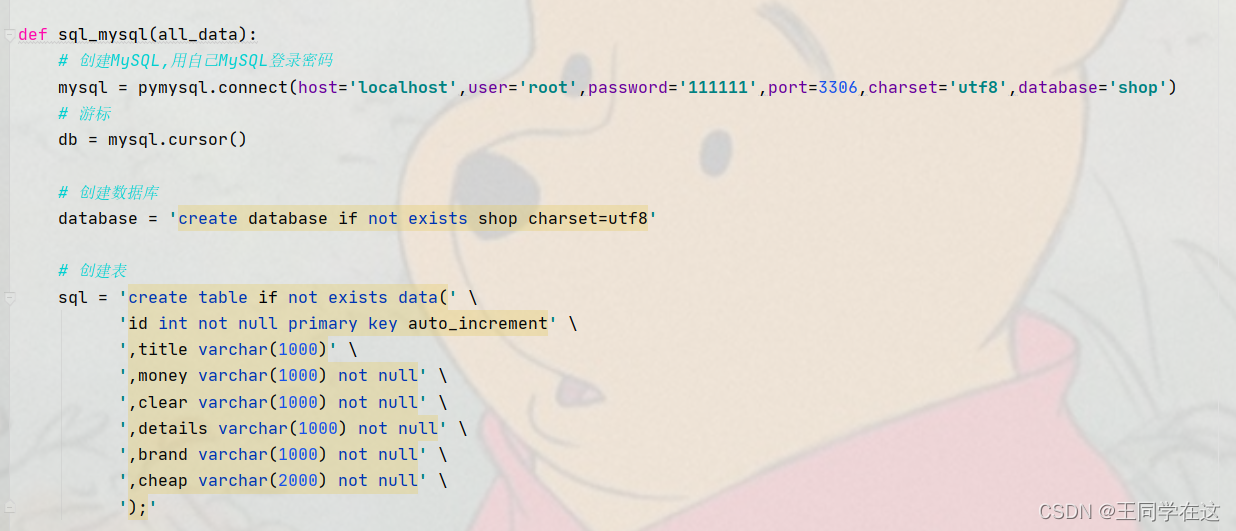
下图是连接数据库和创建游标对象,并编写好建表的sql语句后面交给游标执行,注意要把自己MySQL登录的密码改成自己的,数据库一开始我就在开头创建好了,这里直接用database选择我们创建好的数据库就OK,
因为我们的数据在列表中,因此对列表遍历得到字典,再用键的方式取字典里面的值。
编写插入数据库的sql语句,交给游标去执行。
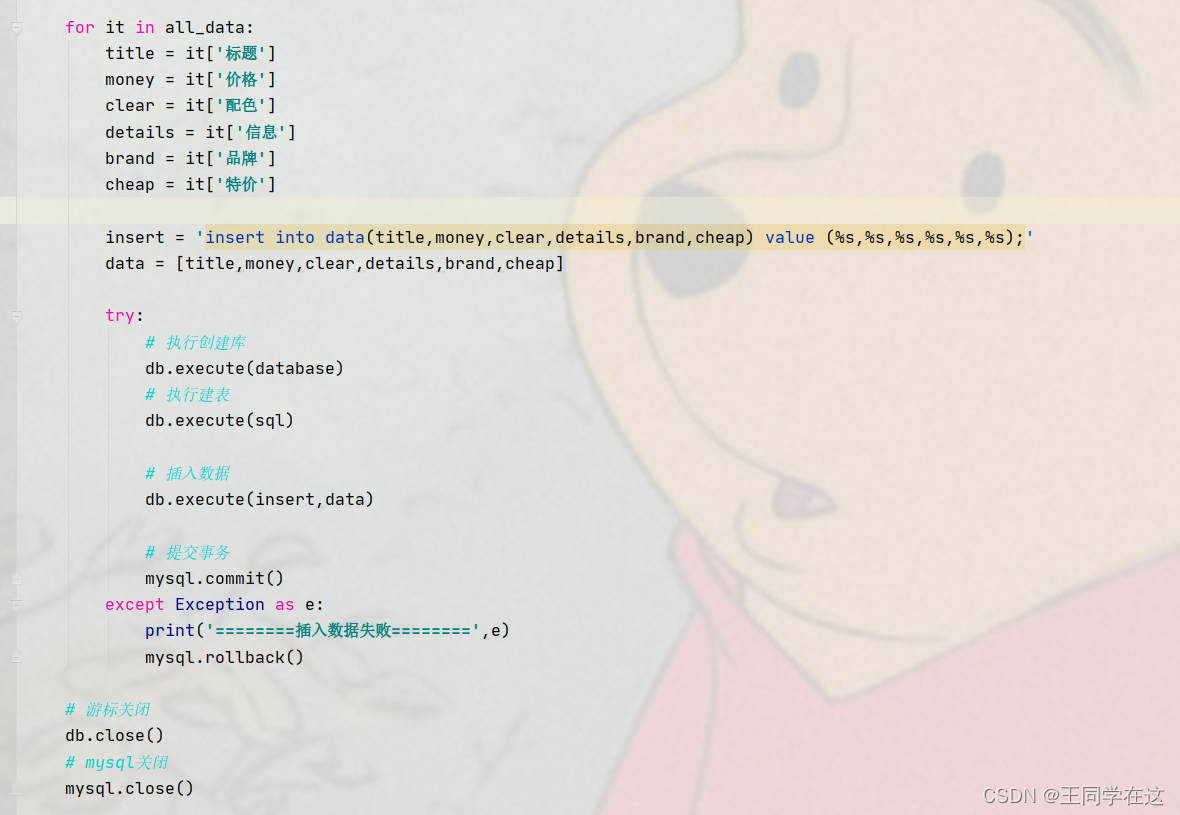
步骤就完成了
运行结果

到这里程序就完成了,运行代码时注意保持网络畅通,如果网速太慢可能会失败,建议在网络好的环境下运行。

以下是全部代码
# @Author : 王同学
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait # 等待
from selenium.webdriver.common.action_chains import ActionChains # 动作链
from selenium.webdriver.support import expected_conditions as EC
import time
import csv # csv
import pymysql # MySQL库# 创建浏览器对象
driver = webdriver.Chrome()# 显示等待
wait = WebDriverWait(driver,10)def get_serch(url):# 窗口最大化driver.maximize_window()# 发送请求driver.get(url,)print('===========访问成功============')time.sleep(1)# 等待页面元素加载wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="J-search"]/div[1]/input')))# 输入框insert = driver.find_element(By.XPATH,'//*[@id="J-search"]/div[1]/input')insert.send_keys('电脑')time.sleep(1)# clickcli = driver.find_element(By.CLASS_NAME,'c-search-icon')cli.click()time.sleep(1)def get_data():# 空列表all_data = []num = 1while num <= 12:print(f'========================正在保存第{num}页的数据======================')# 加载三次for i in range(1,4):try:# 动作链加载元素action = driver.find_element(By.XPATH,'//*[@id="J_nextPage_link"]/i')ActionChains(driver).move_to_element(action).perform()time.sleep(1)except:print('======================没有下一页了===================')break# 找到全部divall_div = driver.find_elements(By.XPATH,'//*[@id="J_searchCatList"]/div')print(f'=============一共有{len(all_div)}件商品=============')time.sleep(1)# 字典for i in all_div[1:]: # 切片,除了第一个不要i.click()time.sleep(1)# 切换窗口视角driver.switch_to.window(driver.window_handles[-1])try:title = driver.find_element(By.XPATH,'//*[@id="J_detail_info_mation"]/div/p[1]').textexcept:title = 'NOD DATA'try:money = driver.find_element(By.XPATH,'//*[@class="spcecialPrice-box"]/div[1]/div[1]/span[1]').textexcept:money = 'NOD DATA'try:clear = driver.find_element(By.XPATH,'//*[@class="color-list"]/ul').text.replace('\n','').replace(' ','|').replace('♥','')except:clear = 'NOD DATA'try:details = driver.find_element(By.XPATH,'//*[@id="J_dc_Detail"]/div[2]/div[1]/table/tbody').text.replace('\n','').replace(' ','|')except:details = 'NOD DATA'try:brand = driver.find_element(By.XPATH,'//*[@class="pib-title"]/a').textexcept:brand = 'NOD DATA'try:cheap = driver.find_element(By.XPATH,'//*[@class="finalPrice"]/div[1]/span').text.replace('¥','').replace('起','')except:cheap = 'NOD DATA'item = {'标题': title,'价格': money,'配色': clear,'信息': details,'品牌': brand,'特价': cheap}print(item)all_data.append(item)driver.close()# 切换回用来的driver.switch_to.window(driver.window_handles[0])time.sleep(1)try:# 翻页net_page = driver.find_element(By.XPATH, '//*[@id="J_nextPage_link"]/i')net_page.click()num += 1except:breaktime.sleep(1)# 验证try:driver.switch_to.frame(driver.find_element(By.TAG_NAME, 'iframe'))dic = driver.find_element(By.XPATH, '/html/body/div/a')dic.click()time.sleep(1)driver.switch_to.default_content()except:continuereturn all_datadef save_csv(all_data):# 表头headers = ['标题','价格','配色','信息','品牌','特价']# 打开文件with open('数据.csv','w',encoding='utf-8',newline='')as f:filt = csv.DictWriter(f,headers)filt.writeheader()filt.writerows(all_data)return all_datadef sql_mysql(all_data):# 创建MySQL,用自己MySQL登录密码mysql = pymysql.connect(host='localhost',user='root',password='111111',port=3306,charset='utf8',database='shop')# 游标db = mysql.cursor()# 创建数据库database = 'create database if not exists shop charset=utf8'# 创建表sql = 'create table if not exists data(' \'id int not null primary key auto_increment' \',title varchar(1000)' \',money varchar(1000) not null' \',clear varchar(1000) not null' \',details varchar(1000) not null' \',brand varchar(1000) not null' \',cheap varchar(2000) not null' \');'for it in all_data:title = it['标题']money = it['价格']clear = it['配色']details = it['信息']brand = it['品牌']cheap = it['特价']insert = 'insert into data(title,money,clear,details,brand,cheap) value (%s,%s,%s,%s,%s,%s);'data = [title,money,clear,details,brand,cheap]try:# 执行创建库db.execute(database)# 执行建表db.execute(sql)# 插入数据db.execute(insert,data)# 提交事务mysql.commit()except Exception as e:print('========插入数据失败========',e)mysql.rollback()# 游标关闭db.close()# mysql关闭mysql.close()def main():url = 'https://www.vip.com/'get_serch(url)all_data = get_data()all_data = save_csv(all_data)sql_mysql(all_data)if __name__ == '__main__':main()